Deep Infra
Übersicht von Deep Infra
Was ist Deep Infra?
Deep Infra ist eine leistungsstarke Plattform, die sich auf AI-Inferenz für Machine-Learning-Modelle spezialisiert hat und kostengünstigen, schnellen, einfachen und zuverlässigen Zugriff auf über 100 produktionsreife Deep-Learning-Modelle bietet. Ob Sie große Sprachmodelle (LLMs) wie DeepSeek-V3.2 oder spezialisierte OCR-Tools ausführen – die Entwickler-freundlichen APIs von Deep Infra erleichtern die Integration hochperformanter KI in Ihre Anwendungen, ohne den Aufwand der Infrastrukturverwaltung. Auf modernster, inferenzoptimierten Hardware in sicheren US-amerikanischen Rechenzentren aufgebaut, unterstützt es Skalierungen auf Billionen von Tokens bei priorisierter Kosteneffizienz, Datenschutz und Leistung.
Ideal für Startups und Unternehmen gleichermaßen, eliminiert Deep Infra langfristige Verträge und versteckte Gebühren durch sein Pay-as-you-go-Preismodell, sodass Sie nur für das bezahlen, was Sie nutzen. Mit SOC 2- und ISO 27001-Zertifizierungen sowie einer strengen Null-Retention-Richtlinie bleibt Ihre Daten privat und sicher.
Wichtige Funktionen von Deep Infra
Deep Infra sticht im überfüllten Machine-Learning-Infrastruktur-Landschaft mit diesen Kernfähigkeiten hervor:
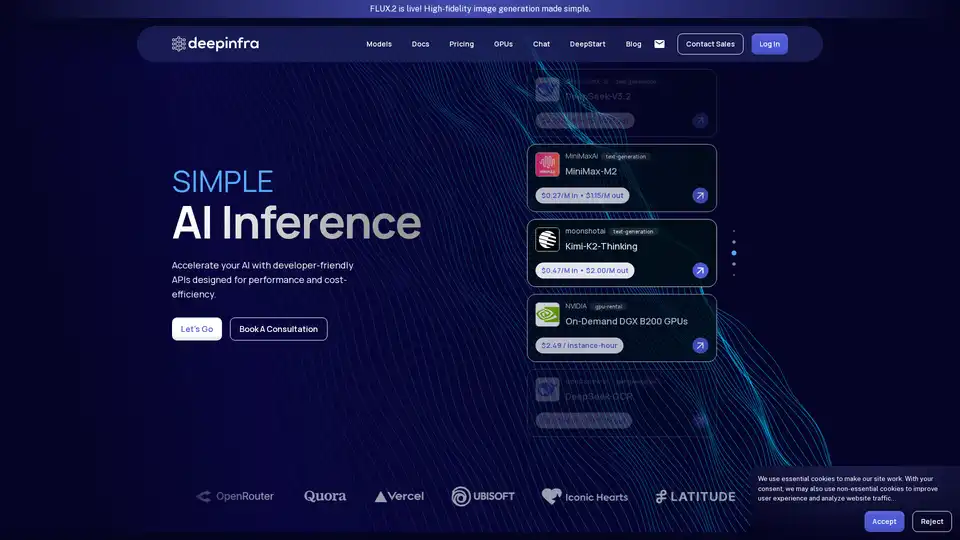
Umfangreiche Modellbibliothek: Zugriff auf über 100 Modelle in Kategorien wie Text-Generierung, Automatic-Speech-Recognition, Text-to-Speech und OCR. Hervorgehobene Modelle umfassen:
- DeepSeek-V3.2: Effizientes LLM mit sparse attention für Long-Context-Reasoning.
- MiniMax-M2: Kompaktes 10B-Parameter-Modell für Coding- und agentische Aufgaben.
- Qwen3-Serie: Skalierbare Modelle für Instruction-Following und Thinking-Modes.
- OCR-Spezialisten wie DeepSeek-OCR, olmOCR-2-7B und PaddleOCR-VL für Dokumenten-Parsing.
Kosteneffektive Preise: Ultraniedrige Raten, z. B. $0.03/M Input für DeepSeek-OCR, $0.049/M für gpt-oss-120b. Zwischengespeicherte Preise senken die Kosten für wiederholte Abfragen weiter.
Skalierbare Leistung: Bewältigt Billionen von Tokens mit Metriken wie 0ms Time-to-First-Token (in Live-Demos) und ExaFLOPS-Compute. Unterstützt bis zu 256k Kontextlängen.
GPU-Vermietung: On-Demand NVIDIA DGX B200 GPUs zu $2.49/Instanz-Stunde für benutzerdefinierte Workloads.
Sicherheit & Compliance: Null-Retention von Input/Output, SOC 2 Type II, ISO 27001-zertifiziert.
Anpassung: Maßgeschneiderte Inferenz für Latenz-, Durchsatz- oder Skalierungs-Prioritäten mit hands-on Support.
| Modellbeispiel | Typ | Preise (in/out pro 1M Tokens) | Kontextlänge |
|---|---|---|---|
| DeepSeek-V3.2 | text-generation | $0.27 / $0.40 | 160k |
| gpt-oss-120b | text-generation | $0.049 / $0.20 | 128k |
| DeepSeek-OCR | text-generation | $0.03 / $0.10 | 8k |
| DGX B200 GPUs | gpu-rental | $2.49/hour | N/A |
Wie funktioniert Deep Infra?
Der Einstieg in Deep Infra ist unkompliziert:
Registrieren und API-Zugriff: Erstellen Sie ein kostenloses Konto, erhalten Sie Ihren API-Key und integrieren Sie über einfache RESTful-Endpunkte – keine komplexe Einrichtung erforderlich.
Modelle auswählen: Wählen Sie aus dem Katalog (z. B. über Dashboard oder Docs), der Provider wie DeepSeek-AI, OpenAI, Qwen und MoonshotAI unterstützt.
Inferenz ausführen: Senden Sie Prompts über API-Aufrufe. Modelle wie DeepSeek-V3.1-Terminus unterstützen konfigurierbare Reasoning-Modes (Thinking/Non-Thinking) und Tool-Use für agentische Workflows.
Skalieren & Überwachen: Live-Metriken tracken Tokens/Sek., TTFT, RPS und Ausgaben. Hosten Sie Ihre eigenen Modelle auf ihren Servern für Datenschutz.
Optimieren: Nutzen Sie Optimierungen wie FP4/FP8-Quantisierung, sparse attention (z. B. DSA in DeepSeek-V3.2) und MoE-Architekturen für Effizienz.
Die proprietäre Infrastruktur der Plattform gewährleistet niedrige Latenz und hohe Zuverlässigkeit und übertrifft generische Cloud-Provider bei Deep-Learning-Inferenz.
Anwendungsfälle und praktischer Wert
Deep Infra glänzt in realen AI-Anwendungen:
Entwickler & Startups: Schnelle Prototyping von Chatbots, Code-Agents oder Content-Generatoren mit erschwinglichen LLMs.
Unternehmen: Produktionsskalierte Deployments für OCR in Dokumentenverarbeitung (z. B. PDFs mit Tabellen/Diagrammen via PaddleOCR-VL), Finanzanalyse oder custom Agents.
Forscher: Experimentieren mit Frontier-Modellen wie Kimi-K2-Thinking (Gold-Medaillen-IMO-Performance) ohne Hardware-Kosten.
Agentische Workflows: Modelle wie DeepSeek-V3.1 unterstützen Tool-Calling, Code-Synthese und Long-Context-Reasoning für autonome Systeme.
Nutzer berichten von 10x Kosteneinsparungen im Vergleich zu Wettbewerbern, mit nahtloser Skalierung – perfekt für Peak-Loads in SaaS-Apps oder Batch-Verarbeitung.
Für wen ist Deep Infra?
AI/ML-Ingenieure: Brauchen zuverlässiges Model-Hosting und APIs.
Produktteams: Bauen AI-Features ohne Infra-Overhead.
Kostbewusste Innovatoren: Startups optimieren Burn Rate bei High-Compute-Aufgaben.
Compliance-fokussierte Organisationen: Handhaben sensibler Daten mit Zero-Retention-Garantien.
Warum Deep Infra statt Alternativen wählen?
Im Gegensatz zu Hyperscalern mit hohen Mindestmengen oder Self-Hosting-Schmerzen kombiniert Deep Infra OpenAI-Level-Einfachheit mit 50-80% niedrigeren Kosten. Kein Vendor-Lock-in, globale Zugänglichkeit und aktive Modell-Updates (z. B. FLUX.2 für Bilder). Untermauert durch echte Metriken und Nutzererfolge in Coding-Benchmarks (LiveCodeBench), Reasoning (GPQA) und Tool-Use (Tau2).
Bereit zur Beschleunigung? Buchen Sie eine Beratung oder tauchen Sie in die Docs ein für skalierbare AI-Infrastruktur heute. Deep Infra treibt die nächste Welle effizienter, produktionsreifer AI voran.
Mit Deep Infra Verwandte Tags
