Stable Diffusion
Übersicht von Stable Diffusion
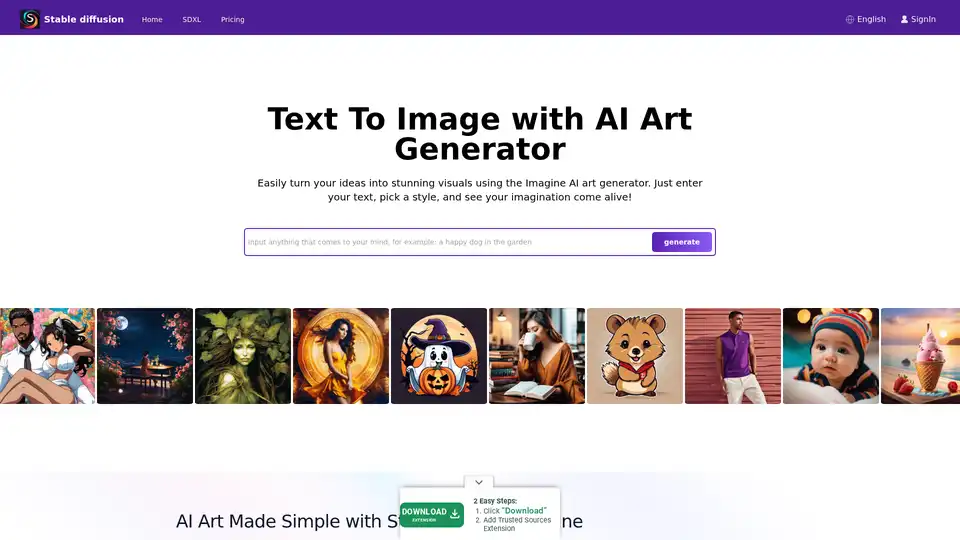
Was ist Stable Diffusion AI?
Stable Diffusion ist ein bahnbrechendes Open-Source-AI-System, das Textbeschreibungen in atemberaubende, realistische Bilder umwandelt. Entwickelt von der CompVis-Gruppe an der Ludwig Maximilian University of Munich in Zusammenarbeit mit Runway ML und Stability AI, nutzt es Diffusionsmodelle, um Text-zu-Bild-Generierung, Bildbearbeitung und mehr zu ermöglichen. Im Gegensatz zu proprietären Tools sind der Code, die vortrainierten Modelle und die Lizenz von Stable Diffusion vollständig Open-Source, sodass Nutzer es auf einer einzelnen GPU direkt auf ihren Geräten ausführen können. Diese Zugänglichkeit hat die KI-gestützte Kreativität demokratisiert und hochwertige Bildgenerierung für Künstler, Designer und Hobbyisten ohne Unternehmensressourcen zugänglich gemacht.
Im Kern zeichnet sich Stable Diffusion durch die Erstellung detaillierter Visuals aus einfachen Prompts aus und unterstützt Auflösungen bis zu 1024x1024 Pixeln. Es ist besonders für seine Vielseitigkeit bekannt, bei der Landschaften, Porträts, abstrakte Kunst und sogar konzeptionelle Designs generiert werden. Für diejenigen, die in die KI-Kunst eintauchen, ist Stable Diffusion ein zuverlässiger Einstiegspunkt, der kreative Freiheit bietet, während ethische Nutzung im Sinn gehalten wird, um Voreingenommenheiten aus den Trainingsdaten zu vermeiden.
Wie funktioniert Stable Diffusion?
Stable Diffusion basiert auf einer Latent Diffusion Model (LDM)-Architektur, die Bilder effizient in einem latenten Raum komprimiert und verarbeitet, anstatt im vollständigen Pixelraum, was den Rechenaufwand reduziert. Das System umfasst drei Schlüsselkomponenten:
- Variational Autoencoder (VAE): Dies komprimiert Eingabebilder in eine kompakte latente Darstellung, bewahrt wesentliche semantische Details und wirft Rauschen weg.
- U-Net: Das Denoisier-Backbone, aufgebaut auf einer ResNet-Struktur, entfernt iterativ Gauß-Rauschen, das während des Forward-Diffusionsprozesses hinzugefügt wird. Es verwendet Cross-Attention-Mechanismen, um Text-Prompts einzubeziehen, und leitet die Generierung zu benutzerdefinierten Ausgaben.
- Text Encoder (Optional): Wandelt Textbeschreibungen in Embeddings um, die die Denoisier-Schritte beeinflussen.
Der Prozess beginnt mit dem Hinzufügen von Rauschen zu einem latenten Bild (oder dem Start von purem Rauschen für die Generierung). Das U-Net kehrt diesen Diffusionsprozess schrittweise um, verfeinert die Ausgabe, bis ein kohärentes Bild entsteht. Sobald entrauscht, rekonstruiert der VAE-Decoder das finale pixelbasierte Bild. Dieser elegante Workflow gewährleistet hochwertige Ergebnisse, sogar für komplexe Prompts mit Stilen, Kompositionen oder Motiven.
Das Training auf dem massiven LAION-5B-Datensatz – bestehend aus Milliarden von Bild-Text-Paaren aus Webquellen – ermöglicht es Stable Diffusion, vielfältige visuelle Konzepte zu lernen. Die Daten werden nach Qualität, Auflösung und Ästhetik gefiltert, wobei Techniken wie Classifier-Free Guidance die Einhaltung des Prompts verbessern. Allerdings führt diese webquellenbasierte Data kulturelle Voreingenommenheiten ein, hauptsächlich gegenüber Englisch und westlichem Inhalt, die Nutzer bei der Generierung diverser Darstellungen berücksichtigen sollten.
Kernfunktionen und Fähigkeiten von Stable Diffusion
Stable Diffusion geht über die grundlegende Bilderstellung hinaus; es bietet eine Reihe fortschrittlicher Funktionen:
- Text-zu-Bild-Generierung: Geben Sie einen beschreibenden Prompt wie „eine ruhige Berglandschaft bei Sonnenuntergang“ ein und generieren Sie Originalkunstwerke in Sekunden.
- Bildbearbeitungstools: Verwenden Sie Inpainting, um Teile eines Bildes auszufüllen oder zu modifizieren (z. B. das Ändern von Hintergründen), und Outpainting, um über die ursprünglichen Ränder hinauszuerweitern.
- Bild-zu-Bild-Übersetzung: Zeichnen Sie bestehende Fotos mit neuer textueller Anleitung neu, bewahren Sie die Struktur bei und ändern Sie Stile oder Elemente.
- ControlNet Integration: Erhalten Sie geometrische Strukturen, Posen oder Kanten aus Referenzbildern, während stilistische Änderungen angewendet werden.
- Hochauflösungsunterstützung: Die XL-Variante (Stable Diffusion XL 1.0) verbessert die Fähigkeiten mit einem Dual-Modell mit 6 Milliarden Parametern, ermöglicht 1024x1024-Ausgaben, bessere Textdarstellung in Bildern und vereinfachte Prompts für schnellere, realistischere Ergebnisse.
Verbesserungen wie LoRAs (Low-Rank Adaptations) ermöglichen Feinabstimmungen für spezifische Details – wie Gesichter, Kleidung oder Anime-Stile – ohne das gesamte Modell neu zu trainieren. Embeddings erfassen visuelle Stile für konsistente Ausgaben, während negative Prompts unerwünschte Elemente wie Verzerrungen oder zusätzliche Gliedmaßen ausschließen und die Qualität verfeinern.
Wie man Stable Diffusion AI verwendet
Der Einstieg in Stable Diffusion ist unkompliziert, ob online oder offline.
Online-Zugang über Plattformen
Für Anfänger bieten Plattformen wie Stablediffusionai.ai eine benutzerfreundliche Weboberfläche:
- Besuchen Sie stablediffusionai.ai und melden Sie sich an.
- Geben Sie Ihren Text-Prompt in das Eingabefeld ein.
- Wählen Sie Stile, Auflösungen (z. B. SDXL für hochauflösend) und passen Sie Parameter wie Sampling-Schritte an.
- Klicken Sie auf „Generate“ oder „Dream“, um Bilder zu erstellen.
- Verfeinern Sie mit negativen Prompts (z. B. „blurry, low quality“) und laden Sie Favoriten herunter.
Diese Installationsfreie Option ist ideal für schnelle Experimente, erfordert jedoch Internet.
Lokale Installation und Download
Für vollständige Kontrolle und Offline-Nutzung:
- Laden Sie von GitHub (github.com/CompVis/stable-diffusion) herunter, indem Sie „Code“ > „Download ZIP“ klicken (benötigt ~10GB Platz).
- Installieren Sie Voraussetzungen: Python 3.10+, Git und eine GPU mit 4GB+ VRAM (NVIDIA empfohlen).
- Entpacken Sie die ZIP, platzieren Sie Modell-Checkpoints (z. B. von Hugging Face) im Models-Ordner.
- Führen Sie webui-user.bat (Windows) oder das entsprechende Skript aus, um die lokale UI zu starten.
- Geben Sie Prompts ein, passen Sie Einstellungen wie Inference-Schritte (20-50 für Balance) an und generieren Sie.
Erweiterungen wie Automatic1111's Web-UI fügen Funktionen wie Batch-Verarbeitung hinzu. Sobald eingerichtet, läuft es vollständig offline und priorisiert Datenschutz.
Trainieren Ihres eigenen Stable Diffusion-Modells
Fortgeschrittene Nutzer können Stable Diffusion anpassen:
- Sammeln Sie einen Datensatz von Bild-Text-Paaren (z. B. für Nischenstile).
- Bereiten Sie Daten durch Reinigen und Beschreiben vor.
- Modifizieren Sie Configs für Ihren Datensatz und Hyperparameter (Batch-Größe, Lernrate).
- Trainieren Sie Komponenten separat (VAE, U-Net, Text-Encoder) mit Skripten – mieten Sie Cloud-GPUs für schwere Aufgaben.
- Evaluieren und feinabstimmen iterativ.
Dieser Prozess erfordert technisches Wissen, schaltet aber maßgeschneiderte Modelle für spezifische Bereiche wie Mode oder Architektur frei.
Stable Diffusion XL: Die verbesserte Version
Im Juli 2023 von Stability AI veröffentlicht, baut SDXL auf dem Original mit einer größeren Parameteranzahl für überlegene Details auf. Es vereinfacht Prompts (weniger Wörter nötig), enthält integrierte Stile und excelliert bei lesbarem Text in Bildern. Für Profis liefert SDXL Online über dedizierte Plattformen ultra-hochauflösende Ausgaben für Marketing-Visuals, Game-Assets oder Drucke. Es ist ein Schritt nach oben für diejenigen, die Photorealismus oder intricate Designs ohne Kompromisse bei der Geschwindigkeit suchen.
Verwendung von LoRAs, Embeddings und negativen Prompts
- LoRAs: Laden Sie spezialisierte Dateien (z. B. für Porträts) herunter und aktivieren Sie sie über Prompts wie "lora:portrait_style:1.0". Sie verbessern Details effizient.
- Embeddings: Trainieren Sie auf Stil-Datensätzen, dann rufen Sie mit ":style_name:" in Prompts für thematische Konsistenz auf.
- Negative Prompts: Spezifizieren Sie Vermeidungen wie "deformed, ugly", um Mängel zu minimieren und die Gesamtpräzision zu verbessern.
Praktische Anwendungen und Use Cases
Stable Diffusion glänzt in verschiedenen Szenarien:
- Künstler und Designer: Prototypen von Konzepten, Generierung von Referenzen oder Experimente mit Stilen für digitale Kunst, Illustrationen oder UI/UX-Mockups.
- Marketing und Media: Erstellen Sie maßgeschneiderte Visuals für Werbung, Social Media oder Inhalte ohne Stock-Fotos – ideal für E-Commerce-Produktrenderings.
- Bildung und Hobbyisten: Lehren Sie KI-Konzepte oder basteln Sie personalisierte Kunst, wie Familienporträts in Fantasy-Settings.
- Game Development: Asset-Erstellung für Charaktere, Umgebungen oder Texturen, besonders mit ControlNet für Pose-Kontrolle.
Seine Offline-Fähigkeit eignet sich für remote Kreative, während API-Zugang (über Dream Studio oder Hugging Face) in Workflows integriert werden kann.
Für wen ist Stable Diffusion?
Dieses Tool richtet sich an kreative Profis, von novizenhaften Digital-Künstlern bis zu erfahrenen Entwicklern. Anfänger schätzen die intuitiven Interfaces, während Experten die Anpassungsoptionen wie Feinabstimmung wertschätzen. Es ist perfekt für diejenigen, die Open-Source-Ethik und lokalen Datenschutz über Cloud-Abhängigkeiten priorisieren. Allerdings ist es weniger geeignet für nicht-kreative Aufgaben oder Nutzer ohne grundlegende Tech-Setup.
Einschränkungen und Best Practices
Trotz Stärken hat Stable Diffusion Hürden:
- Voreingenommenheiten: Ausgaben könnten westliche Ästhetik bevorzugen; diverse Prompts und Feinabstimmungen helfen, dies zu mildern.
- Anatomische Herausforderungen: Hände und Gesichter können verzerrt wirken – verwenden Sie negative Prompts oder LoRAs.
- Ressourcenbedarf: Lokale Läufe erfordern anständige Hardware; Cloud-Alternativen wie Stablediffusionai.ai überbrücken Lücken.
Überprüfen Sie immer auf ethische Probleme, wie Urheberrecht in Trainingsdaten. Communities auf Civitai oder Reddit bieten Modelle und Tipps, um Mängel zu überwinden.
Warum Stable Diffusion wählen?
In einer überfüllten KI-Landschaft fördert die Open-Source-Natur von Stable Diffusion Innovation mit ständigen Community-Updates. Im Vergleich zu geschlossenen Tools wie DALL-E bietet es unbegrenzte Generierungen ohne Quoten und vollständiges Eigentum an Ausgaben. Für Hochauflösungsbedürfnisse liefert SDXL pro-level Qualität kostengünstig. Ob beim Anregen von Ideen oder Finalisieren von Projekten, es befähigt Nutzer, menschliche Erfindungskraft mit KI-Effizienz zu verbinden.
Preise und Zugang
Das Kern-Stable Diffusion ist kostenlos zum Download und zur Nutzung. Plattformen wie Stablediffusionai.ai bieten kostenlose Tiers mit bezahlten Upgrades für schnellere Generierungen oder fortschrittliche Features. Dream Studio API-Credits starten niedrig und skalieren für intensive Nutzung. Lokale Setups eliminieren laufende Kosten und machen es wirtschaftlich für anhaltende Kreativität.
Zusammenfassend definiert Stable Diffusion die KI-Kunstgenerierung neu, indem es die Macht in die Hände der Nutzer legt. Tauchen Sie in sein Ökosystem über GitHub oder Online-Demos ein und schalten Sie endlose Möglichkeiten für visuelles Storytelling frei.
Mit Stable Diffusion Verwandte Tags
