Unreal Speech
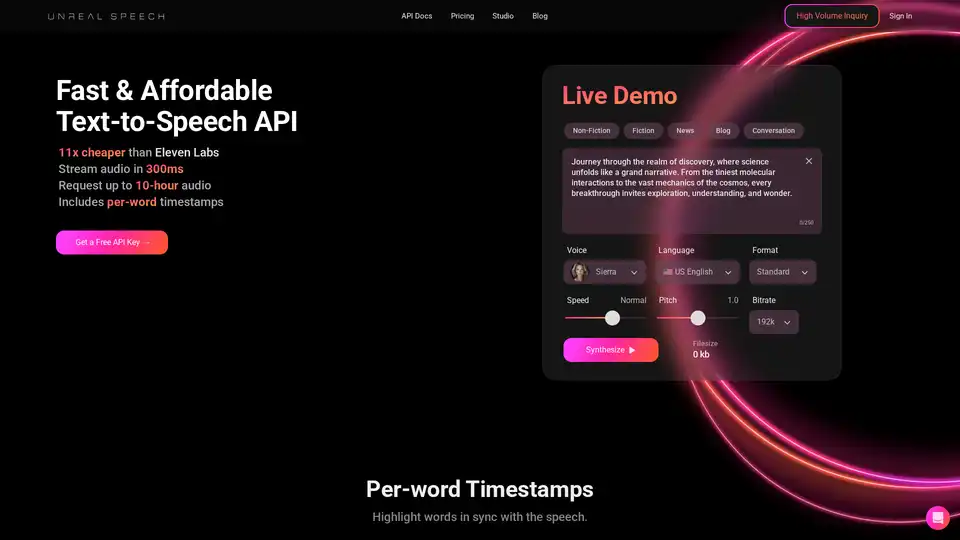
Übersicht von Unreal Speech
Unreal Speech: Schnelle und erschwingliche Text-to-Speech-API
Unreal Speech bietet eine schnelle und erschwingliche Text-to-Speech-API-Lösung, die deutlich günstiger ist als Alternativen wie Eleven Labs. Sie ermöglicht es Benutzern, Audio schnell zu streamen, Langform-Audio anzufordern und bietet Zeitstempel pro Wort für verbesserte Kontrolle und Synchronisation.
Was ist Unreal Speech?
Unreal Speech ist eine Text-to-Speech-API, die für Entwickler und Unternehmen entwickelt wurde, die eine kostengünstige und leistungsstarke Lösung zur Umwandlung von Text in natürlich klingende Sprache suchen. Ziel ist es, eine nahtlose Erfahrung für die Erstellung von Audioinhalten zu bieten, von kurzen Snippets bis hin zu langen Audiodateien.
Wie funktioniert Unreal Speech?
Unreal Speech verwendet fortschrittliche Sprachsynthesemodelle, um geschriebenen Text in gesprochenes Audio umzuwandeln. Die API bietet mehrere Schlüsselfunktionen:
- Geringe Latenz: Streamt Audio in nur 300 ms, wodurch es für Echtzeitanwendungen geeignet ist.
- Hohe Kapazität: Kann Anfragen für bis zu 10 Stunden Audio verarbeiten.
- Zeitstempel pro Wort: Bietet präzise Timing-Informationen für jedes Wort und ermöglicht so synchronisiertes Hervorheben und Animation.
- Mehrere Stimmen und Sprachen: Bietet eine Vielzahl von Stimmen in verschiedenen Sprachen, darunter US-Englisch, UK-Englisch, Mandarin-Chinesisch, Hindi, Spanisch, Portugiesisch, Japanisch, Französisch und Italienisch.
- Flexible Ausgabeformate: Unterstützt Standard-Audioformate wie MP3 und PCM µ-law, um verschiedenen Anwendungsfällen gerecht zu werden.
Hauptmerkmale von Unreal Speech
- Erschwingliche Preise: Unreal Speech positioniert sich als wirtschaftliche Alternative zu anderen Text-to-Speech-Diensten und kostet 11x weniger als Eleven Labs.
- Echtzeit-Streaming: Der /stream-Endpunkt ermöglicht die schnelle Konvertierung von bis zu 1.000 Zeichen und liefert nahezu sofortiges Audio.
- Asynchrone Synthese: Der /synthesisTasks-Endpunkt ist für die Erstellung längerer Audiodateien konzipiert, mit der Möglichkeit, 10-Stunden-Audio in etwa 15 Minuten zu generieren.
- Timestamp-Unterstützung: Die API kann Zeitstempel auf Wort- oder Satzebene bereitstellen und so die synchronisierte Texthervorhebung erleichtern.
Wie verwende ich Unreal Speech?
Um Unreal Speech zu verwenden, benötigen Sie einen API-Schlüssel. So legen Sie los:
- API-Schlüssel erhalten: Melden Sie sich auf der Unreal Speech-Website für einen kostenlosen API-Schlüssel an.
- Endpunkt auswählen: Wählen Sie den entsprechenden Endpunkt basierend auf Ihren Bedürfnissen aus:
/stream: Für Echtzeit-Streaming von kurzem Text./synthesisTasks: Zum asynchronen Generieren längerer Audiodateien./streamWithTimestamps: Für das Streamen von Audio mit Wort-Level-Zeitstempeln.
- API-Anfragen stellen: Verwenden Sie die bereitgestellten Codebeispiele (Python, Node.js, React Native, Bash), um die API in Ihre Anwendung zu integrieren.
Hier ist ein Beispiel für die Verwendung des /stream-Endpunkts in Python:
import requests
response = requests.post(
'https://api.v8.unrealspeech.com/stream',
headers = {
'Authorization' : 'Bearer YOUR_API_KEY'
},
json = {
'Text': '''<YOUR_TEXT>''', # Up to 1,000 characters
'VoiceId': '<VOICE_ID>', # af, af_bella, af_sarah, am_adam, am_michael, bf_emma, bf_isabella, bm_george, bm_lewis, af_nicole, af_sky
'Bitrate': '192k', # 320k, 256k, 192k, ...
'Speed': '0', # -1.0 to 1.0
'Pitch': '1', # 0.5 to 1.5
'Codec': 'libmp3lame', # libmp3lame or pcm_mulaw
}
)
with open('audio.mp3', 'wb') as f:
f.write(response.content)
Warum Unreal Speech wählen?
- Kosteneinsparungen: Deutliche Reduzierung der Text-to-Speech-Kosten im Vergleich zu anderen Anbietern.
- Hohe Qualität: Liefert natürlich klingende Sprache mit verschiedenen Sprachoptionen.
- Skalierbarkeit: Kann hohe Anfragevolumina verarbeiten, wie Kundenaussagen belegen.
- Flexibilität: Bietet mehrere API-Endpunkte und Ausgabeformate für verschiedene Anwendungsfälle.
Für wen ist Unreal Speech geeignet?
Unreal Speech ist für eine breite Palette von Benutzern geeignet, darunter:
- Entwickler: Integration von Text-to-Speech-Funktionen in Anwendungen.
- Content Creators: Erstellung von Audioversionen von Artikeln, Blogbeiträgen und anderen schriftlichen Inhalten.
- Unternehmen: Automatisierung des Kundenservice mit Sprachassistenten und Chatbots.
- Bildungseinrichtungen: Erstellung von barrierefreien Lernmaterialien mit Audio-Unterstützung.
Unreal Speech Preise
Unreal Speech bietet verschiedene Preispläne, um unterschiedlichen Bedürfnissen gerecht zu werden:
- Kostenloser Plan: Enthält eine begrenzte Anzahl von Zeichen pro Monat.
- Bezahlte Pläne: Bieten größere Zeichenkontingente und zusätzliche Funktionen.
- Enterprise Plan: Bietet kundenspezifische Lösungen und dedizierten Support für High-Volume-Benutzer.
Zusätzliche Nutzung über das monatliche Kontingent hinaus wird pro 1 Million Zeichen berechnet, wobei die Preise je nach Abonnementplan variieren.
Kundenmeinung
Derek Pankaew, CEO von Listening.com, teilt seine Erfahrungen mit Unreal Speech:
"Unreal Speech hat uns 75 % unserer Text-to-Speech-Kosten gespart. Es klingt besser als Amazon Polly und ist viel billiger. Wir haben bei hohen Volumina umgestellt und verarbeiten oft über 10.000 Seiten pro Stunde. Unreal war in der Lage, das Volumen zu bewältigen und gleichzeitig ein qualitativ hochwertiges Hörerlebnis zu bieten."
FAQ
- Bieten Sie Stimmen in anderen Sprachen an? Ja, Unreal Speech bietet 48 Stimmen in 8 verschiedenen Sprachen.
- Kann ich benutzerdefinierte Stimmen (Stimmklonung) erstellen? Noch nicht, aber sie arbeiten daran!
- Kann ich generiertes Audio kommerziell nutzen? Ja, mit Unreal Speech generiertes Audio kann kommerziell genutzt werden. Für den kostenlosen Plan ist eine Namensnennung erforderlich.
Unreal Speech ist eine überzeugende Option für alle, die eine schnelle, erschwingliche und zuverlässige Text-to-Speech-API suchen. Mit seiner geringen Latenz, hohen Kapazität und den Zeitstempeln pro Wort eignet es sich gut für eine Vielzahl von Anwendungen und Anwendungsfällen.
Beste Alternativwerkzeuge zu "Unreal Speech"
Text2Audio: Kostenloses Online-Text-to-Speech-Tool. Konvertieren Sie Text mühelos in Audio für jeden Zweck mit der TTS API von Google.
Erleben Sie bahnbrechende Voice AI mit unserem kostenlosen Text-to-Speech-Generator und -Converter. Genießen Sie schnelle, hochwertige Stimmensynthese, angetrieben von fortschrittlichen KI-Modellen wie Deepseek, Hailuo, Grok und Kling, für natürliche, ausdrucksstarke Sprache in verschiedenen Anwendungen.
Erstellen Sie realistische KI-Stimmen mit der Plattform von VoiSpark. Bietet Text-to-Speech, Sprachklonierung und benutzerdefiniertes Sprachdesign. Starten Sie noch heute Ihre 100% kostenlose Testversion!
Vbee AIVoice ist eine KI-Text-to-Speech-Plattform, die natürliche, emotionale Stimmen für die Erstellung von Inhalten und praktische Anwendungen bietet und über 90 % des Budgets und der Zeit einspart.
All Voice Lab bietet fortschrittliche AI-Text-zu-Sprache-, Sprachklonungs- und Sprachwechsel-Tools für realistischen, mehrsprachigen Audio. Erstellen Sie ansprechende Voice-Overs mit emotionaler Expressivität—kostenloses Testen starten.
Azure AI Speech Studio befähigt Entwickler mit Sprach-zu-Text-, Text-zu-Sprache- und Übersetzungstools. Erkunden Sie Funktionen wie benutzerdefinierte Modelle, Sprachavatare und Echtzeit-Transkription, um die Zugänglichkeit und Interaktion von Apps zu verbessern.
LMNT liefert schnelle, lebensechte, günstige KI-Sprache. Genießen Sie Studio-Qualitäts-Stimmklone und Low-Latency-Streaming, ideal für konversationelle Apps, Spiele und Agents. Für Zuverlässigkeit entwickelt, skalieren Sie mühelos mit Technologie von einem Ex-Google-Team.
PyGPT ist ein kostenloser Open-Source-Desktop-KI-Assistent für Windows, macOS und Linux. Es bietet Chat, Vision, Agenten, Bildgenerierung, Sprachsteuerung und mehr, unterstützt durch Modelle wie GPT-5, GPT-4, Google Gemini und andere.
ToleAI bietet einen anpassbaren KI-Arbeitsbereich mit Tools für Projektmanagement, Transkriptionszusammenfassungen, KI-Notizblock, Bildgenerierung und OCR. Steigern Sie die Teamproduktivität und -Zusammenarbeit mit intelligenten Agenten und nahtlosen Integrationen.
Kokoro Web ist ein 100 % kostenloser und Open-Source-Online-KI-Sprachgenerator. Wandeln Sie Text mit natürlichen, KI-gestützten Stimmen in Sprache um – für immer kostenlos!
TTSMaker ist ein kostenloses Online-Text-zu-Sprache-Tool, das Text mit KI-Technologie in natürliche Sprache umwandelt. Es unterstützt 100+ Sprachen und 600+ KI-Stimmen und bietet kommerzielle Nutzungsrechte sowie MP3/WAV-Downloads.
AnyVoice bietet die schnellste KI-Stimmklonung und benötigt nur 3 Sekunden Audio, um jede Stimme zu klonen. Es unterstützt mehrere Sprachen und bietet realistische Text-to-Speech-Funktionen, ideal für die Erstellung von Inhalten und Echtzeitanwendungen.
Inworld TTS bietet hochmoderne KI-Text-to-Speech für Endverbraucheranwendungen mit geringerer Latenz, mehr Kontrolle und flexiblen Bereitstellungsoptionen. Entdecken Sie verschiedene KI-Stimmen und klonen Sie Ihre eigene.
Free Text to Speech Online ist ein Reader, der Ihren Text in eine natürlich klingende Stimme umwandelt. Konvertieren Sie Text einfach in Sprache und hören Sie ihn an.