ImageBind
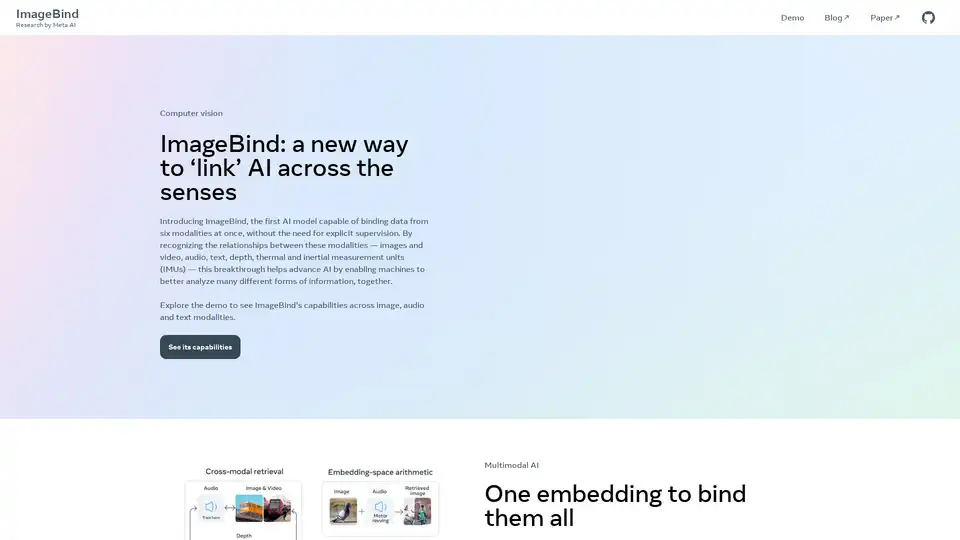
Overview of ImageBind
ImageBind: Meta AI's Breakthrough in Multimodal AI
What is ImageBind?
ImageBind, developed by Meta AI, represents a significant advancement in the field of artificial intelligence. It is the first AI model capable of binding data from six different modalities simultaneously, without requiring explicit supervision. These modalities include:
- Images and video
- Audio
- Text
- Depth
- Thermal
- Inertial measurement units (IMUs)
This innovative approach allows machines to better analyze various forms of information collectively, mimicking how humans perceive and understand the world through multiple senses.
How does ImageBind work?
ImageBind functions by learning a single embedding space that binds multiple sensory inputs together. This is achieved without explicit supervision, meaning the model learns the relationships between the modalities on its own, based on the data it is trained on. By creating a unified embedding space, ImageBind enables various applications, including audio-based search, cross-modal search, multimodal arithmetic, and even cross-modal generation.
Key Features and Capabilities
- Multimodal Binding: Links data from six modalities into a single embedding space.
- Zero-Shot Recognition: Achieves state-of-the-art performance on emergent zero-shot recognition tasks across modalities.
- Cross-Modal Search: Enables searching for information across different modalities (e.g., finding images based on audio descriptions).
- Audio-Based Search: Allows users to search using audio inputs.
- Multimodal Arithmetic: Facilitates arithmetic operations across different modalities.
- Cross-Modal Generation: Supports the generation of content across different modalities.
Applications and Use Cases
ImageBind's capabilities open up a wide range of potential applications across various domains:
- Enhanced Search Engines: Improve search accuracy by combining text, image, and audio inputs.
- Robotics: Enable robots to better understand their environment by processing data from multiple sensors.
- Content Creation: Generate new content by combining information from different modalities.
- Accessibility: Develop assistive technologies that leverage multiple senses to aid individuals with disabilities.
Who is ImageBind for?
ImageBind is valuable for researchers, developers, and organizations interested in advancing the field of multimodal AI. It can be used to build more sophisticated AI systems that can better understand and interact with the world.
How to use ImageBind?
The model is available as an open-source resource, allowing developers to integrate it into their own projects. Meta AI provides a demo and research paper for further exploration.
Emergent Recognition Performance
ImageBind excels in emergent zero-shot recognition tasks, surpassing the performance of specialized models trained specifically for individual modalities. This highlights its ability to generalize and adapt to new tasks without requiring additional training.
The Significance of ImageBind
ImageBind represents a crucial step forward in the development of AI systems that can understand and process information in a more human-like way. By binding multiple senses together, ImageBind enables machines to gain a more comprehensive understanding of the world, leading to more intelligent and versatile AI applications.
Why choose ImageBind?
- Comprehensive Multimodal Support: Handles a wide range of input modalities.
- State-of-the-Art Performance: Achieves excellent results in zero-shot recognition tasks.
- Open-Source Availability: Allows for easy integration and customization.
- Versatile Applications: Can be applied to various tasks and domains.
Conclusion
ImageBind is a groundbreaking AI model developed by Meta AI that has the potential to revolutionize the field of artificial intelligence. Its ability to bind data from multiple modalities without explicit supervision enables machines to gain a more comprehensive understanding of the world. With its open-source availability and state-of-the-art performance, ImageBind is poised to drive innovation across a wide range of applications and industries.
Tags Related to ImageBind
