WebCrawler API
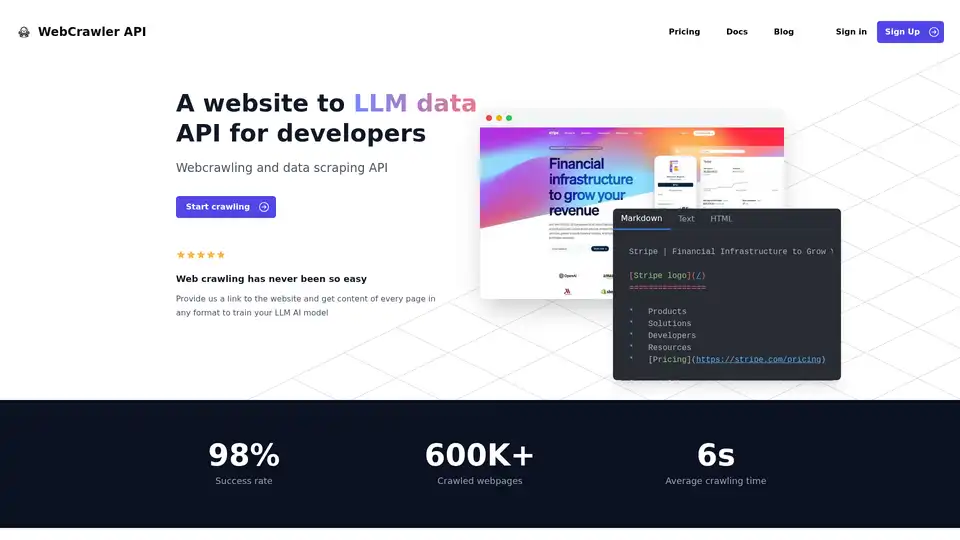
Overview of WebCrawler API
WebCrawler API: Effortless Web Crawling and Data Extraction for AI
What is WebCrawler API? It's a powerful tool designed to simplify the process of extracting data from websites, specifically for training Large Language Models (LLMs) and other AI applications. It handles the complexities of web crawling, allowing you to focus on utilizing the data.
Key Features:
- Easy Integration: Integrate WebCrawlerAPI with just a few lines of code using NodeJS, Python, PHP, or .NET.
- Versatile Output Formats: Receive content in Markdown, Text, or HTML formats, tailored to your needs.
- High Success Rate: Boasting a 98% success rate, WebCrawlerAPI overcomes common crawling challenges like anti-bot blocks, CAPTCHAs, and IP blocks.
- Comprehensive Link Handling: Manages internal links, removes duplicates, and cleans URLs.
- JS Rendering: Employs Puppeteer and Playwright in a stable manner to handle JavaScript-heavy websites.
- Scalable Infrastructure: Reliably manages and stores millions of crawled pages.
- Automatic Data Cleaning: Converts HTML to clean text or Markdown using complex parsing rules.
- Proxy Management: Includes unlimited proxy usage, so you don't have to worry about IP restrictions.
How does WebCrawler API work?
WebCrawler API abstracts away the difficulties of web crawling, such as:
- Link Handling: Managing internal links, removing duplicates, and cleaning URLs.
- JS Rendering: Rendering JavaScript-heavy websites to extract dynamic content.
- Anti-Bot Blocks: Bypassing CAPTCHAs, IP blocks, and rate limits.
- Storage: Managing and storing large volumes of crawled data.
- Scaling: Handling multiple crawlers across different servers.
- Data Cleaning: Converting HTML to clean text or Markdown.
By handling these underlying complexities, WebCrawlerAPI allows you to focus on what truly matters – utilizing the extracted data for your AI projects.
How to use WebCrawler API?
- Sign up for an account and obtain your API access key.
- Choose your preferred programming language: NodeJS, Python, PHP, or .NET.
- Integrate the WebCrawlerAPI client into your code.
- Specify the target URL and desired output format (Markdown, Text, or HTML).
- Initiate the crawl and retrieve the extracted content.
Example using NodeJS:
// npm i webcrawlerapi-js
import webcrawlerapi from "webcrawlerapi-js";
async function main() {
const client = new webcrawlerapi.WebcrawlerClient(
"YOUR API ACCESS KEY HERE",
)
const syncJob = await client.crawl({
"items_limit": 10,
"url": "https://stripe.com/",
"scrape_type": "markdown"
}
)
console.log(syncJob);
}
main().catch(console.error);
Why choose WebCrawler API?
- Focus on your core business: Avoid spending time and resources on managing complex web crawling infrastructure.
- Access clean and structured data: Receive data in your preferred format, ready for AI training.
- Scale your data extraction efforts: Handle millions of pages without worrying about infrastructure limitations.
- Cost-effective pricing: Pay only for successful requests, with no subscription fees.
Who is WebCrawler API for?
WebCrawler API is ideal for:
- AI and Machine Learning Engineers: Who need large datasets to train their models.
- Data Scientists: Who need to extract data from websites for analysis and research.
- Businesses: That need to monitor competitors, track market trends, or gather customer insights.
Pricing
WebCrawlerAPI offers simple, usage-based pricing with no subscription fees. You pay only for successful requests. A cost calculator is available to estimate your monthly expenses based on the number of pages you plan to crawl.
FAQ
- What is WebcrawlerAPI? WebcrawlerAPI is an API that allows you to extract content from websites with a high success rate, handling proxies, retries, and headless browsers.
- Can I only crawl specific pages or the entire website? You can specify whether you want to crawl specific pages or the entire website when making a request.
- Can I use crawled data in RAG or train my own AI model? Yes, the crawled data can be used in Retrieval-Augmented Generation (RAG) systems or to train your own AI models.
- Do I need to pay a subscription to use WebcrawlerAPI? No, there are no subscription fees. You only pay for successful requests.
- Can I try WebcrawlerAPI before purchasing? Contact them to inquire about trial options.
- What if I need help with integration? Email support is provided.
Best way to Extract Website Data for AI Training with WebCrawlerAPI
WebCrawlerAPI provides a streamlined solution for extracting website data, simplifying the complexities of web crawling and enabling you to concentrate on AI model training and data analysis. With its high success rate, versatile output formats, and efficient data cleaning capabilities, it empowers AI engineers, data scientists, and businesses to gather valuable insights from the web effectively.
Best Alternative Tools to "WebCrawler API"
Firecrawl is the leading web crawling, scraping, and search API designed for AI applications. It turns websites into clean, structured, LLM-ready data at scale, powering AI agents with reliable web extraction without proxies or headaches.
Transform any website into clean, structured data with Skrape.ai. AI-powered API extracts data in preferred format for AI training.

Olostep is a web data API for AI and research agents. It allows you to extract structured web data from any website in real-time and automate your web research workflows. Use cases include data for AI, spreadsheet enrichment, lead generation, and more.

Exa is an AI-powered search engine and web data API designed for developers. It offers fast web search, websets for complex queries, and tools for crawling, answering, and in-depth research, enabling AI to access real-time information.
Agenty® is a no-code web scraping software that automates data collection, change monitoring, and browser automation. Extract valuable information from websites with AI, enhancing research and gaining insights.
UseScraper is a hyper-fast web scraping and crawling API. Scrape any URL instantly, crawl entire websites, and output data in plain text, HTML, or Markdown. First 1,000 pages are free.
Chat Data is an AI chatbot creation tool for websites, Discord, Slack, Shopify, WordPress, & more. Train once, deploy everywhere. Customize, connect, & share.
BulkGPT is a no-code tool for bulk AI workflow automation, enabling fast web scraping and ChatGPT batch processing to create SEO content, product descriptions, and marketing materials effortlessly.
Capalyze is a data analytics tool that empowers businesses with insights through multi-source integration and web data crawling, driving smarter decisions.
Schemawriter.ai is an AI-powered schema markup generator that automates JSON-LD structured data for webpages. It extracts entities from competitors, generates georadius and local business schemas, and optimizes content using YAKE keywords, Wikipedia, and Google APIs for superior SEO performance.
Apify is a full-stack cloud platform for web scraping, browser automation, and AI agents. Use pre-built tools or build your own Actors for data extraction and workflow automation.
Horseman is a configurable web crawler that uses JavaScript snippets and GPT integration to provide insights into your website. It's perfect for developers, SEO specialists, and performance analysts.
Crawl AI: Build custom AI assistants, agents, and web scrapers easily. Scrape websites, extract data, and power deep research.
PromptLoop: AI platform for GTM & B2B Sales. Automate web scraping, deep research, and CRM data enrichment for accurate B2B insights. 10x faster B2B research. Get started free.