Baseten

Descripción general de Baseten
¿Qué es Baseten?
Baseten es una plataforma diseñada para simplificar la implementación y el escalado de modelos de AI en producción. Proporciona la infraestructura, las herramientas y la experiencia necesarias para llevar los productos de AI al mercado rápidamente.
¿Cómo funciona Baseten?
La plataforma de Baseten se basa en el Baseten Inference Stack, que incluye investigación de vanguardia en rendimiento, infraestructura nativa de la nube y una experiencia de desarrollador diseñada para la inferencia.
Aquí hay un desglose de los componentes clave:
- Model APIs: Pruebe rápidamente nuevas cargas de trabajo, prototipos de productos y evalúe los últimos modelos con un rendimiento de nivel de producción.
- Training on Baseten: Entrene modelos utilizando infraestructura optimizada para la inferencia sin restricciones ni sobrecarga.
- Applied Performance Research: Utilice kernels personalizados, técnicas de decodificación y almacenamiento en caché avanzado para optimizar el rendimiento del modelo.
- Cloud-Native Infrastructure: Escale las cargas de trabajo en cualquier región y nube (Baseten Cloud o la suya propia), con inicios en frío rápidos y un alto tiempo de actividad.
- Developer Experience (DevEx): Implemente, optimice y gestione modelos y soluciones de AI compuestas con una experiencia de desarrollador lista para la producción.
Características y Beneficios Clave
- Dedicated Deployments: Diseñado para cargas de trabajo a gran escala, lo que le permite servir modelos de AI de código abierto, personalizados y ajustados en una infraestructura creada para la producción.
- Multi-Cloud Capacity Management: Ejecute cargas de trabajo en Baseten Cloud, autoalojamiento o flexibilidad bajo demanda. La plataforma es compatible con cualquier proveedor de nube.
- Custom Model Deployment: Implemente cualquier modelo personalizado o propietario con optimizaciones de rendimiento listas para usar.
- Support for Gen AI: Optimizaciones de rendimiento personalizadas diseñadas para aplicaciones Gen AI.
- Model Library: Explore e implemente modelos preconstruidos con facilidad.
Aplicaciones Específicas
Baseten atiende a una variedad de aplicaciones de AI, que incluyen:
- Image Generation: Sirva modelos personalizados o flujos de trabajo de ComfyUI, ajuste para su caso de uso o implemente cualquier modelo de código abierto en minutos.
- Transcription: Utiliza un modelo Whisper personalizado para una transcripción rápida, precisa y rentable.
- Text-to-Speech: Admite la transmisión de audio en tiempo real para llamadas telefónicas de AI de baja latencia, agentes de voz, traducción y más.
- Large Language Models (LLMs): Logre un mayor rendimiento y una menor latencia para modelos como DeepSeek, Llama y Qwen con Dedicated Deployments.
- Embeddings: Ofrece Baseten Embeddings Inference (BEI) con mayor rendimiento y menor latencia en comparación con otras soluciones.
- Compound AI: Permite hardware granular y autoescalado para AI compuesta, mejorando el uso de la GPU y reduciendo la latencia.
¿Por qué elegir Baseten?
Aquí hay varias razones por las que Baseten se destaca:
- Performance: Infraestructura optimizada para tiempos de inferencia rápidos.
- Scalability: Escalado perfecto en la nube de Baseten o en la suya propia.
- Developer Experience: Herramientas y flujos de trabajo diseñados para entornos de producción.
- Flexibility: Admite varios modelos, incluidos modelos de código abierto, personalizados y ajustados.
- Cost-Effectiveness: Optimiza la utilización de recursos para reducir los costos.
¿Para quién es Baseten?
Baseten es ideal para:
- Machine Learning Engineers: Agilice la implementación y gestión de modelos.
- AI Product Teams: Acelere el tiempo de comercialización de los productos de AI.
- Companies: Buscando una infraestructura de AI escalable y confiable.
Testimonios de Clientes
- Nathan Sobo, Co-founder: Baseten ha brindado la mejor experiencia posible para los usuarios y la empresa.
- Sahaj Garg, Co-founder and CTO: Obtuvo mucho control sobre el pipeline de inferencia y optimizó cada paso con el equipo de Baseten.
- Lily Clifford, Co-founder and CEO: La latencia y el tiempo de actividad de última generación de Rime están impulsados por un enfoque compartido en los fundamentos con Baseten.
- Isaiah Granet, CEO and Co-founder: Permitió números de ingresos increíbles sin preocuparse por las GPU y el escalado.
- Waseem Alshikh, CTO and Co-founder of Writer: Logró un servicio de modelos rentable y de alto rendimiento para LLMs creados a medida sin sobrecargar a los equipos de ingeniería internos.
Baseten proporciona una solución integral para implementar y escalar modelos de AI en producción, ofreciendo alto rendimiento, flexibilidad y una experiencia de desarrollador fácil de usar. Ya sea que esté trabajando con generación de imágenes, transcripción, LLMs o modelos personalizados, Baseten tiene como objetivo agilizar todo el proceso.
Mejores herramientas alternativas a "Baseten"
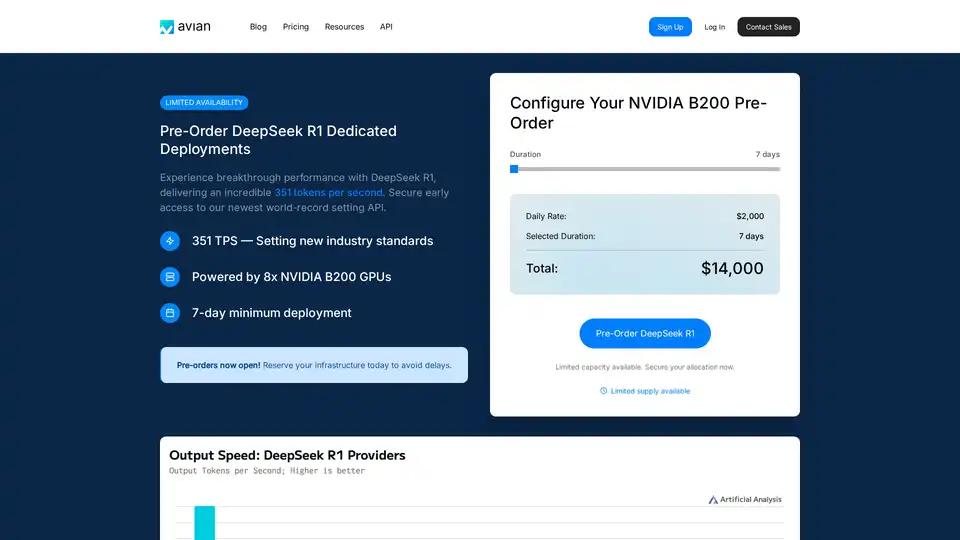
Avian API ofrece la inferencia de IA más rápida para LLM de código abierto, alcanzando 351 TPS en DeepSeek R1. Implemente cualquier LLM de HuggingFace a una velocidad de 3 a 10 veces mayor con una API compatible con OpenAI. Rendimiento y privacidad de nivel empresarial.
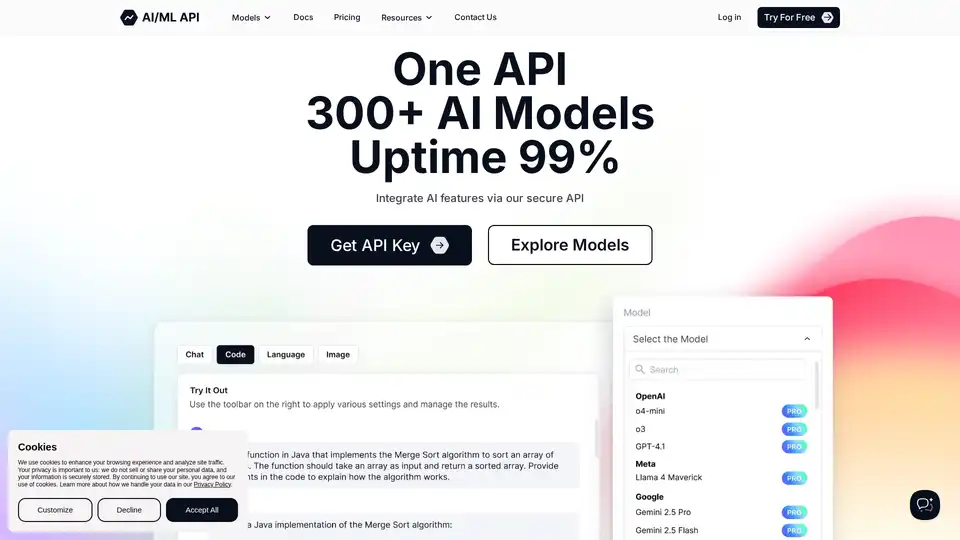
AIMLAPI ofrece acceso a más de 300 modelos de IA a través de una única API de baja latencia. Ahorre hasta un 80% en comparación con OpenAI con soluciones de IA rápidas y rentables para el aprendizaje automático.

Float16.cloud ofrece GPUs sin servidor para el desarrollo de IA. Implementa modelos instantáneamente en GPUs H100 con precios de pago por uso. Ideal para LLM, ajuste fino y entrenamiento.

Habilite la inferencia LLM eficiente con llama.cpp, una biblioteca C/C++ optimizada para diversos hardware, que admite cuantificación, CUDA y modelos GGUF. Ideal para implementación local y en la nube.
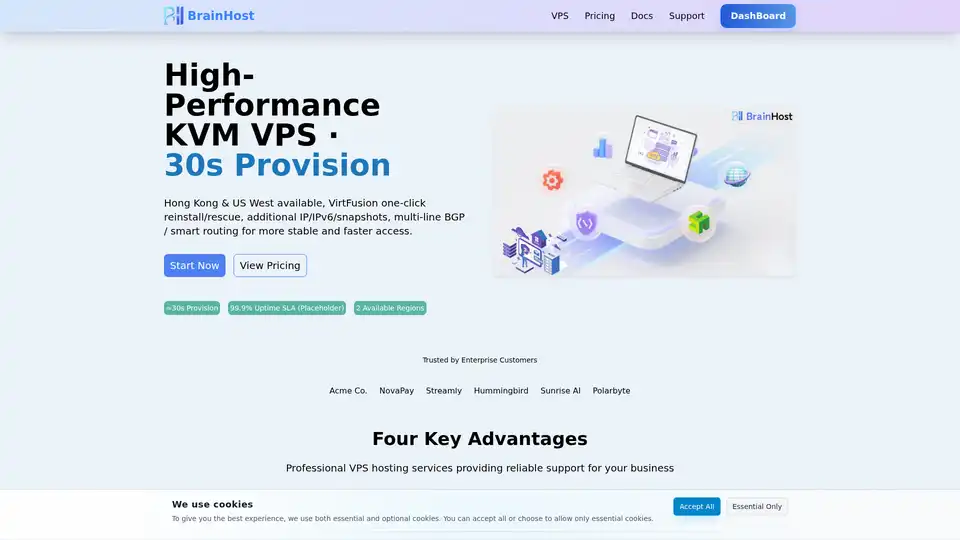
BrainHost VPS ofrece servidores virtuales KVM de alto rendimiento con almacenamiento NVMe, ideal para inferencia de IA, sitios web y comercio electrónico. Implementación rápida en 30s en Hong Kong y US West para acceso global confiable.

Explore las API de NVIDIA NIM para la inferencia optimizada y la implementación de modelos de IA líderes. Cree aplicaciones de IA generativa empresarial con API sin servidor o autohospedaje en su infraestructura de GPU.

GPUX es una plataforma de inferencia GPU sin servidor que permite arranques en frío de 1 segundo para modelos de IA como StableDiffusionXL, ESRGAN y AlpacaLLM con rendimiento optimizado y capacidades P2P.
PremAI es un laboratorio de investigación de IA que proporciona modelos de IA seguros y personalizados para empresas y desarrolladores. Las características incluyen inferencia encriptada TrustML y modelos de código abierto.
Cirrascale AI Innovation Cloud acelera el desarrollo de IA, el entrenamiento y las cargas de trabajo de inferencia. Pruebe e implemente en los principales aceleradores de IA con alto rendimiento y baja latencia.
Spice.ai es un motor de inferencia de datos e IA de código abierto para construir aplicaciones de IA con federación de consultas SQL, aceleración, búsqueda y recuperación basadas en datos empresariales.

Runpod es una plataforma de nube de IA todo en uno que simplifica la creación e implementación de modelos de IA. Entrena, ajusta e implementa IA sin esfuerzo con una computación potente y escalado automático.

Simplifique la implementación de IA con Synexa. Ejecute potentes modelos de IA al instante con solo una línea de código. Plataforma API de IA sin servidor rápida, estable y fácil de usar para desarrolladores.
Modal: Plataforma sin servidor para equipos de IA y datos. Ejecute cómputo intensivo de CPU, GPU y datos a escala con su propio código.
Batteries Included es una plataforma de IA autoalojada que simplifica la implementación de LLM, bases de datos vectoriales y Jupyter notebooks. Construye aplicaciones de IA de clase mundial en tu infraestructura.