Deep Infra
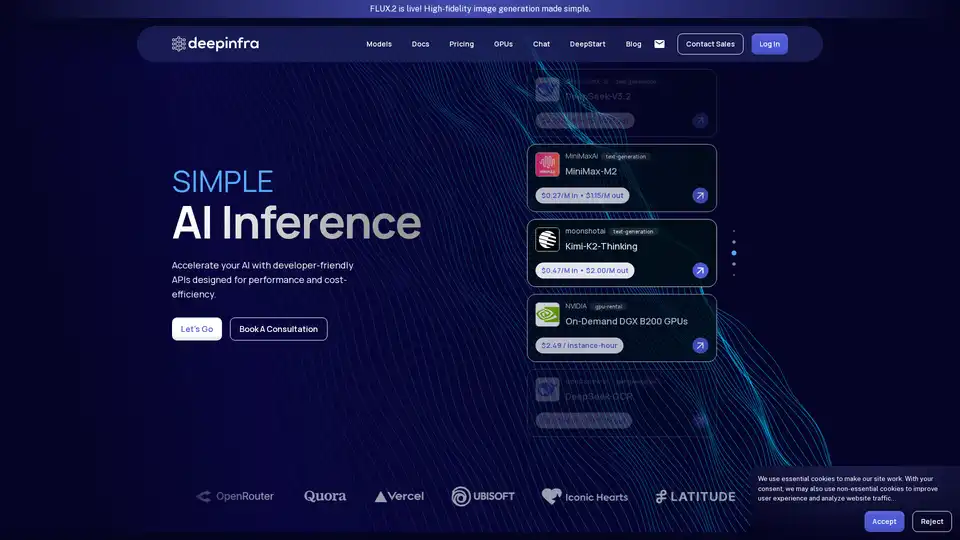
Descripción general de Deep Infra
¿Qué es Deep Infra?
Deep Infra es una potente plataforma especializada en inferencia de IA para modelos de machine learning, que ofrece acceso económico, rápido, simple y confiable a más de 100 modelos de deep learning listos para producción. Ya sea que estés ejecutando modelos de lenguaje grandes (LLMs) como DeepSeek-V3.2 o herramientas especializadas de OCR, las APIs amigables para desarrolladores de Deep Infra facilitan la integración de IA de alto rendimiento en tus aplicaciones sin la molestia de gestionar infraestructura. Construida sobre hardware de vanguardia optimizado para inferencia en centros de datos seguros con sede en EE.UU., soporta escalado a billones de tokens priorizando la eficiencia de costos, privacidad y rendimiento.
Ideal para startups y empresas por igual, Deep Infra elimina contratos a largo plazo y tarifas ocultas con su modelo de pago por uso, asegurando que solo pagues por lo que utilizas. Con certificaciones SOC 2 e ISO 27001, más una estricta política de retención cero, tus datos permanecen privados y seguros.
Características clave de Deep Infra
Deep Infra destaca en el saturado panorama de infraestructura de machine learning con estas capacidades principales:
Vasta biblioteca de modelos: Accede a más de 100 modelos en categorías como generación de texto, reconocimiento automático de voz, texto a voz y OCR. Modelos destacados incluyen:
- DeepSeek-V3.2: LLM eficiente con atención dispersa para razonamiento en contextos largos.
- MiniMax-M2: Modelo compacto de 10B parámetros para tareas de codificación y agenticas.
- Serie Qwen3: Modelos escalables para modos de seguimiento de instrucciones y pensamiento.
- Especialistas en OCR como DeepSeek-OCR, olmOCR-2-7B y PaddleOCR-VL para análisis de documentos.
Precios rentables: Tarifas ultrabajas, p. ej., $0.03/M de entrada para DeepSeek-OCR, $0.049/M para gpt-oss-120b. Precios en caché reducen aún más los costos para consultas repetidas.
Rendimiento escalable: Maneja billones de tokens con métricas como 0ms de tiempo hasta el primer token (en demos en vivo) y cómputo exaFLOPS. Soporta hasta 256k de longitud de contexto.
Alquiler de GPUs: GPUs NVIDIA DGX B200 bajo demanda a $2.49/hora de instancia para cargas de trabajo personalizadas.
Seguridad y cumplimiento: Retención cero de entrada/salida, SOC 2 Type II, certificado ISO 27001.
Personalización: Inferencia adaptada para prioridades de latencia, rendimiento o escala, con soporte práctico.
| Ejemplo de Modelo | Tipo | Precio (entrada/salida por 1M tokens) | Longitud de Contexto |
|---|---|---|---|
| DeepSeek-V3.2 | text-generation | $0.27 / $0.40 | 160k |
| gpt-oss-120b | text-generation | $0.049 / $0.20 | 128k |
| DeepSeek-OCR | text-generation | $0.03 / $0.10 | 8k |
| DGX B200 GPUs | gpu-rental | $2.49/hora | N/A |
¿Cómo funciona Deep Infra?
Comenzar con Deep Infra es sencillo:
Regístrate y accede a la API: Crea una cuenta gratuita, obtén tu clave API e integra vía endpoints RESTful simples—sin configuración compleja requerida.
Selecciona modelos: Elige del catálogo (p. ej., vía dashboard o docs) soportando proveedores como DeepSeek-AI, OpenAI, Qwen y MoonshotAI.
Ejecuta inferencia: Envía prompts vía llamadas API. Modelos como DeepSeek-V3.1-Terminus soportan modos de razonamiento configurables (pensando/no pensando) y uso de herramientas para flujos de trabajo agenticos.
Escala y monitorea: Métricas en vivo rastrean tokens/seg, TTFT, RPS y gasto. Aloja tus propios modelos en sus servidores para privacidad.
Optimiza: Aprovecha optimizaciones como cuantización FP4/FP8, atención dispersa (p. ej., DSA en DeepSeek-V3.2) y arquitecturas MoE para eficiencia.
La infraestructura propietaria de la plataforma asegura baja latencia y alta confiabilidad, superando a proveedores de nube genéricos en inferencia de deep learning.
Casos de uso y valor práctico
Deep Infra destaca en aplicaciones reales de IA:
Desarrolladores y startups: Prototipado rápido de chatbots, agentes de código o generadores de contenido usando LLMs asequibles.
Empresas: Despliegues a escala de producción para OCR en procesamiento de documentos (p. ej., PDFs con tablas/gráficos vía PaddleOCR-VL), análisis financiero o agentes personalizados.
Investigadores: Experimenta con modelos de vanguardia como Kimi-K2-Thinking (rendimiento medalla de oro en IMO) sin costos de hardware.
Flujos de trabajo agenticos: Modelos como DeepSeek-V3.1 soportan llamadas a herramientas, síntesis de código y razonamiento en contextos largos para sistemas autónomos.
Los usuarios reportan ahorros de costos 10x vs. competidores, con escalado fluido—perfecto para manejar cargas pico en apps SaaS o procesamiento por lotes.
¿Para quién es Deep Infra?
Ingenieros de IA/ML: Necesitando alojamiento de modelos confiable y APIs.
Equipos de producto: Construyendo funciones de IA sin sobrecarga de infraestructura.
Innovadores conscientes de costos: Startups optimizando tasa de quema en tareas de alto cómputo.
Organizaciones enfocadas en cumplimiento: Manejando datos sensibles con garantías de retención cero.
¿Por qué elegir Deep Infra sobre alternativas?
A diferencia de hyperscalers con mínimos altos o dolores de autoalojamiento, Deep Infra combina facilidad nivel OpenAI con costos 50-80% más bajos. Sin lock-in de proveedor, accesibilidad global y actualizaciones activas de modelos (p. ej., FLUX.2 para imágenes). Respaldado por métricas reales y éxito de usuarios en bancos de codificación (LiveCodeBench), razonamiento (GPQA) y uso de herramientas (Tau2).
¿Listo para acelerar? Reserva una consulta o sumérgete en los docs para infraestructura de IA escalable hoy. Deep Infra impulsa la próxima ola de IA eficiente y de grado producción.
Etiquetas Relacionadas con Deep Infra
