WebCrawler API
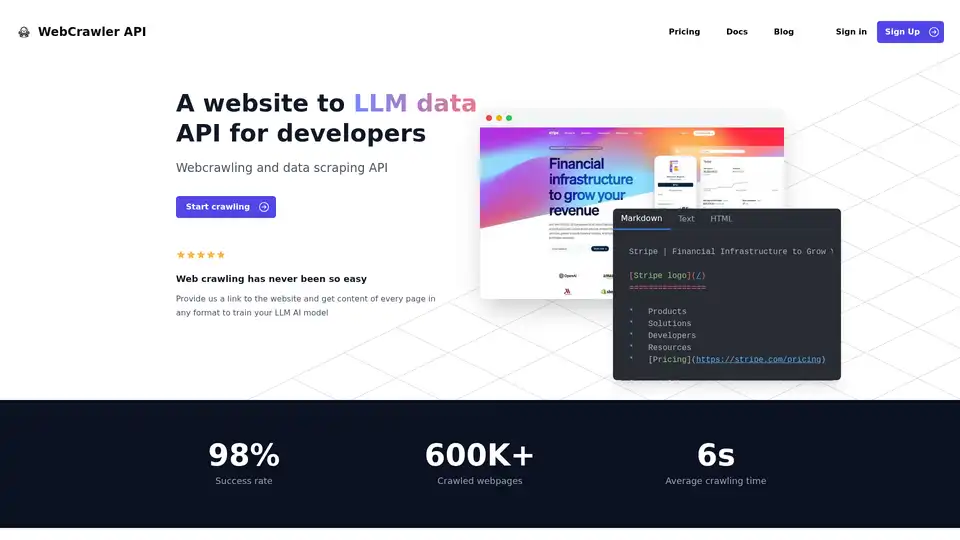
Descripción general de WebCrawler API
API WebCrawler: Rastreo web y extracción de datos sin esfuerzo para la IA
¿Qué es la API WebCrawler? Es una herramienta poderosa diseñada para simplificar el proceso de extracción de datos de sitios web, específicamente para el entrenamiento de Modelos de Lenguaje Grandes (LLM) y otras aplicaciones de AI. Maneja las complejidades del rastreo web, permitiéndote concentrarte en la utilización de los datos.
Características clave:
- Fácil integración: Integra WebCrawlerAPI con solo unas pocas líneas de código usando NodeJS, Python, PHP o .NET.
- Formatos de salida versátiles: Recibe contenido en formatos Markdown, Texto o HTML, adaptados a tus necesidades.
- Alta tasa de éxito: Con una tasa de éxito del 98%, WebCrawlerAPI supera los desafíos comunes de rastreo como los bloqueos anti-bot, los CAPTCHA y los bloqueos de IP.
- Manejo integral de enlaces: Gestiona enlaces internos, elimina duplicados y limpia URLs.
- Renderizado JS: Emplea Puppeteer y Playwright de manera estable para manejar sitios web con mucho JavaScript.
- Infraestructura escalable: Gestiona y almacena de manera confiable millones de páginas rastreadas.
- Limpieza automática de datos: Convierte HTML a texto limpio o Markdown usando reglas de análisis complejas.
- Gestión de proxies: Incluye el uso de proxies ilimitados, para que no tengas que preocuparte por las restricciones de IP.
¿Cómo funciona la API WebCrawler?
La API WebCrawler abstrae las dificultades del rastreo web, tales como:
- Manejo de enlaces: Gestión de enlaces internos, eliminación de duplicados y limpieza de URLs.
- Renderizado JS: Renderizado de sitios web con mucho JavaScript para extraer contenido dinámico.
- Bloqueos anti-bot: Evitar CAPTCHAs, bloqueos de IP y límites de velocidad.
- Almacenamiento: Gestión y almacenamiento de grandes volúmenes de datos rastreados.
- Escalado: Manejo de múltiples rastreadores en diferentes servidores.
- Limpieza de datos: Conversión de HTML a texto limpio o Markdown.
Al manejar estas complejidades subyacentes, WebCrawlerAPI te permite centrarte en lo que realmente importa: utilizar los datos extraídos para tus proyectos de AI.
¿Cómo usar la API WebCrawler?
- Regístrate para obtener una cuenta y obtener tu clave de acceso a la API.
- Elige tu lenguaje de programación preferido: NodeJS, Python, PHP o .NET.
- Integra el cliente WebCrawlerAPI en tu código.
- Especifica la URL de destino y el formato de salida deseado (Markdown, Texto o HTML).
- Inicia el rastreo y recupera el contenido extraído.
Ejemplo usando NodeJS:
// npm i webcrawlerapi-js
import webcrawlerapi from "webcrawlerapi-js";
async function main() {
const client = new webcrawlerapi.WebcrawlerClient(
"YOUR API ACCESS KEY HERE",
)
const syncJob = await client.crawl({
"items_limit": 10,
"url": "https://stripe.com/",
"scrape_type": "markdown"
}
)
console.log(syncJob);
}
main().catch(console.error);
¿Por qué elegir la API WebCrawler?
- Concéntrate en tu negocio principal: Evita gastar tiempo y recursos en la gestión de una infraestructura compleja de rastreo web.
- Accede a datos limpios y estructurados: Recibe datos en tu formato preferido, listos para el entrenamiento de AI.
- Escala tus esfuerzos de extracción de datos: Maneja millones de páginas sin preocuparte por las limitaciones de la infraestructura.
- Precios rentables: Paga solo por las solicitudes exitosas, sin cuotas de suscripción.
¿Para quién es la API WebCrawler?
La API WebCrawler es ideal para:
- Ingenieros de AI y Aprendizaje Automático: Que necesitan grandes conjuntos de datos para entrenar sus modelos.
- Científicos de Datos: Que necesitan extraer datos de sitios web para análisis e investigación.
- Empresas: Que necesitan monitorear a los competidores, rastrear las tendencias del mercado o recopilar información sobre los clientes.
Precios
WebCrawlerAPI ofrece precios sencillos basados en el uso, sin cuotas de suscripción. Solo pagas por las solicitudes exitosas. Un calculador de costos está disponible para estimar tus gastos mensuales en función del número de páginas que planeas rastrear.
Preguntas frecuentes
- ¿Qué es WebcrawlerAPI? WebcrawlerAPI es una API que te permite extraer contenido de sitios web con una alta tasa de éxito, manejando proxies, reintentos y navegadores sin cabeza.
- ¿Puedo rastrear solo páginas específicas o todo el sitio web? Puedes especificar si deseas rastrear páginas específicas o todo el sitio web al realizar una solicitud.
- ¿Puedo usar los datos rastreados en RAG o entrenar mi propio modelo de AI? Sí, los datos rastreados se pueden utilizar en sistemas de Generación Aumentada por Recuperación (RAG) o para entrenar tus propios modelos de AI.
- ¿Necesito pagar una suscripción para usar WebcrawlerAPI? No, no hay cuotas de suscripción. Solo pagas por las solicitudes exitosas.
- ¿Puedo probar WebcrawlerAPI antes de comprar? Ponte en contacto con ellos para preguntar sobre las opciones de prueba.
- ¿Qué pasa si necesito ayuda con la integración? Se proporciona soporte por correo electrónico.
La mejor forma de extraer datos de sitios web para el entrenamiento de AI con WebCrawlerAPI
WebCrawlerAPI proporciona una solución optimizada para extraer datos de sitios web, simplificando las complejidades del rastreo web y permitiéndote concentrarte en el entrenamiento de modelos de AI y el análisis de datos. Con su alta tasa de éxito, formatos de salida versátiles y capacidades eficientes de limpieza de datos, empodera a los ingenieros de AI, a los científicos de datos y a las empresas para recopilar información valiosa de la web de manera efectiva.
Mejores herramientas alternativas a "WebCrawler API"
Firecrawl es la API líder de rastreo, raspado y búsqueda web diseñada para aplicaciones de IA. Convierte sitios web en datos limpios, estructurados y listos para LLM a escala, impulsando agentes de IA con extracción web confiable sin proxies ni complicaciones.
Transforme cualquier sitio web en datos limpios y estructurados con Skrape.ai. Nuestra API impulsada por IA extrae datos en su formato preferido para el entrenamiento de IA.
Hoody AI ofrece acceso anónimo a LLMs líderes como GPT-4o, Claude 3.7 y Llama 3.1 a través de un tablero seguro. Disfruta de chats multi-modelo, interacciones por voz, cargas de archivos y privacidad total sin seguimiento ni datos personales.
PriceResonance es una plataforma impulsada por IA para el seguimiento, análisis y optimización de precios competitivos. Rastrea los precios de la competencia, analiza las tendencias y optimiza tu estrategia de precios.

Olostep es una API de datos web para IA y agentes de investigación. Le permite extraer datos web estructurados de cualquier sitio web en tiempo real y automatizar sus flujos de trabajo de investigación web. Los casos de uso incluyen datos para IA, enriquecimiento de hojas de cálculo, generación de leads y más.
AgentX es una plataforma multiagente que te permite crear agentes de IA especializados para tu negocio. Construye equipos de IA sin código. Integra agentes de IA en tu sitio web, Slack, Discord y más.

Exa es un motor de búsqueda impulsado por IA y una API de datos web diseñada para desarrolladores. Ofrece búsqueda web rápida, conjuntos web para consultas complejas y herramientas para rastrear, responder e investigar en profundidad, lo que permite que la IA acceda a información en tiempo real.
Agenty® es un software de web scraping sin código que automatiza la recopilación de datos, el monitoreo de cambios y la automatización del navegador. Extraiga información valiosa de los sitios web con IA, mejorando la investigación y obteniendo información.
BulkGPT es una herramienta sin código para automatización de flujos de trabajo AI en masa, que permite un raspado web rápido y procesamiento por lotes de ChatGPT para crear contenido SEO, descripciones de productos y materiales de marketing sin esfuerzo.
Chat Data es una herramienta de creación de chatbots de IA para sitios web, Discord, Slack, Shopify, WordPress y más. Entrena una vez, implementa en todas partes. Personaliza, conecta y comparte.
UseScraper es una API de web scraping y crawling hiperrápida. Scrapea cualquier URL al instante, rastrea sitios web completos y exporta datos en texto sin formato, HTML o Markdown. Las primeras 1000 páginas son gratuitas.
Schemawriter.ai es un generador de marcado schema impulsado por IA que automatiza datos estructurados JSON-LD para páginas web. Extrae entidades de competidores, genera schemas de georradio y negocio local, y optimiza contenido con YAKE, Wikipedia y APIs de Google para un SEO superior.
Stockpulse.AI ayuda a las instituciones financieras a tomar decisiones informadas mediante el monitoreo de las redes sociales y la extracción de información útil mediante el análisis impulsado por IA de noticias financieras y comunidades.
CommodityAI es una plataforma impulsada por IA para la gestión moderna de commodities, automatizando envíos, documentos y análisis para aumentar ingresos en 25%, reducir costos en 35% y mejorar productividad en 40%. Ideal para operaciones comerciales.