ImageBind の概要
ImageBind:Meta AIによるマルチモーダルAIのブレークスルー
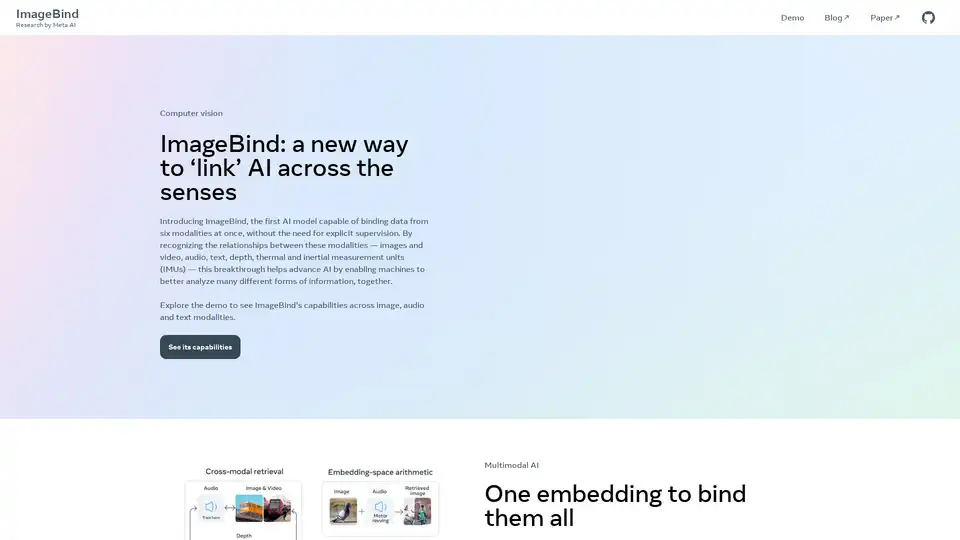
ImageBindとは?
Meta AIによって開発されたImageBindは、人工知能の分野における重要な進歩を代表しています。これは、明示的な監督を必要とせずに、6つの異なるモダリティからのデータを同時に結合できる最初のAIモデルです。これらのモダリティには以下が含まれます。
- 画像とビデオ
- オーディオ
- テキスト
- 深度
- サーマル
- 慣性計測ユニット(IMU)
この革新的なアプローチにより、マシンは複数の感覚を通じて人間が世界を認識し理解する方法を模倣して、さまざまな形式の情報をまとめてより良く分析できます。
ImageBindの仕組みは?
ImageBindは、複数の感覚入力を結合する単一の埋め込み空間を学習することによって機能します。これは明示的な監督なしで実現されます。つまり、モデルはトレーニングされたデータに基づいて、モダリティ間の関係を独自に学習します。統一された埋め込み空間を作成することにより、ImageBindは、オーディオベースの検索、クロスモーダル検索、マルチモーダル演算、さらにはクロスモーダル生成など、さまざまなアプリケーションを可能にします。
主な機能と能力
- マルチモーダルバインディング: 6つのモダリティからのデータを単一の埋め込み空間にリンクします。
- ゼロショット認識: モダリティ全体で、新たなゼロショット認識タスクで最先端のパフォーマンスを実現します。
- クロスモーダル検索: さまざまなモダリティ間で情報を検索できます(たとえば、オーディオの説明に基づいて画像を検索するなど)。
- オーディオベースの検索: ユーザーがオーディオ入力を使用して検索できます。
- マルチモーダル演算: さまざまなモダリティ間での算術演算を容易にします。
- クロスモーダル生成: さまざまなモダリティ間でのコンテンツの生成をサポートします。
アプリケーションとユースケース
ImageBindの機能は、さまざまなドメインにわたる幅広い潜在的なアプリケーションを開きます。
- 強化された検索エンジン: テキスト、画像、オーディオ入力を組み合わせることで、検索精度を向上させます。
- ロボティクス: ロボットが複数のセンサーからのデータを処理することにより、その環境をより良く理解できるようにします。
- コンテンツ作成: さまざまなモダリティからの情報を組み合わせることにより、新しいコンテンツを生成します。
- アクセシビリティ: 複数の感覚を活用して、障害のある個人を支援する支援技術を開発します。
ImageBindは誰のためですか?
ImageBindは、マルチモーダルAIの分野を前進させることに関心のある研究者、開発者、および組織にとって価値があります。これは、世界をより良く理解し、対話できる、より高度なAIシステムを構築するために使用できます。
ImageBindの使用方法は?
モデルはオープンソースリソースとして利用できるため、開発者はそれを独自のプロジェクトに統合できます。 Meta AIは、さらに調査するためのデモと研究論文を提供しています。
新たな認識パフォーマンス
ImageBindは、新たなゼロショット認識タスクで優れており、個々のモダリティ用に特別にトレーニングされた専用モデルのパフォーマンスを上回っています。これは、追加のトレーニングを必要とせずに、新しいタスクに一般化して適応する能力を強調しています。
ImageBindの意義
ImageBindは、人間のような方法で情報を理解し処理できるAIシステムの開発における重要なステップを表しています。複数の感覚を結合することにより、ImageBindはマシンが世界をより包括的に理解できるようにし、よりインテリジェントで用途の広いAIアプリケーションにつながります。
ImageBindを選択する理由
- 包括的なマルチモーダルサポート: 幅広い入力モダリティを処理します。
- 最先端のパフォーマンス: ゼロショット認識タスクで優れた結果を達成します。
- オープンソースの可用性: 簡単な統合とカスタマイズが可能です。
- 用途の広いアプリケーション: さまざまなタスクとドメインに適用できます。
結論
ImageBindは、Meta AIによって開発された画期的なAIモデルであり、人工知能の分野に革命を起こす可能性を秘めています。明示的な監督なしに複数のモダリティからのデータを結合する機能により、マシンは世界をより包括的に理解できます。オープンソースの可用性と最先端のパフォーマンスにより、ImageBindは幅広いアプリケーションと業界でイノベーションを推進する準備ができています。
ImageBind関連タグ
