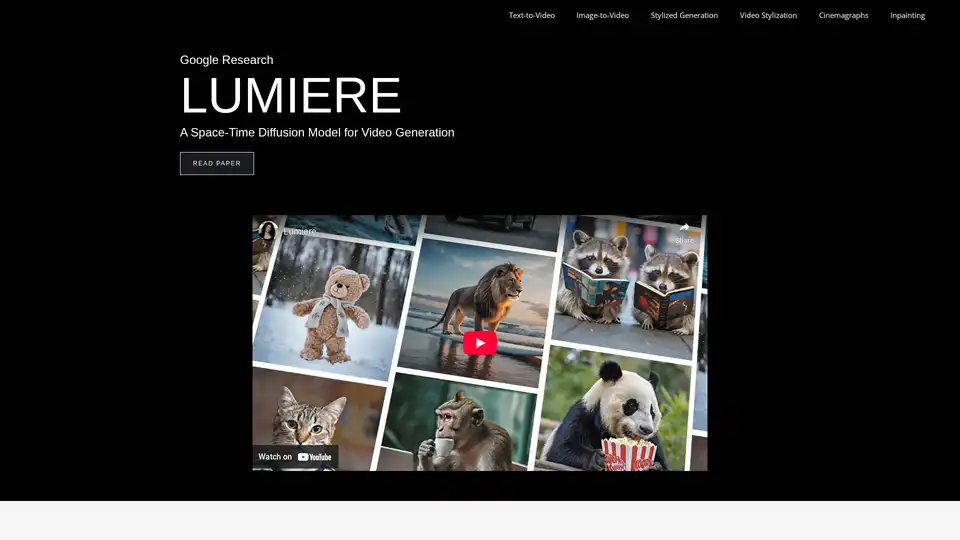
Lumiere の概要
Lumiere: Google Researchによるビデオ生成のための時空間拡散モデル
Lumiereは、Google Researchによって開発された画期的なテキストからビデオへの拡散モデルであり、リアルで多様で一貫性のあるモーションを持つビデオを合成するように設計されています。このモデルは、斬新な時空間U-Netアーキテクチャを導入することにより、ビデオ合成における重要な課題に取り組みます。既存のビデオモデルは、グローバルな時間的一貫性に苦労することが多いのとは異なり、Lumiereは単一のパスでビデオの全時間的持続時間を一度に生成し、よりシームレスで自然なモーションの流れを保証します。
Lumiereとは?
Lumiereは、テキストまたは画像のプロンプトから高品質のビデオを作成するために、時空間拡散プロセスを使用するビデオ生成モデルです。単一のパスでビデオシーケンス全体を生成し、時間的な一貫性とコヒーレンスを促進することで際立っています。
Lumiereはどのように機能するのか?
Lumiereは、複数の時空間スケールでビデオを処理する時空間U-Netアーキテクチャを活用しています。空間的および時間的なダウンサンプリングとアップサンプリングの両方を使用し、事前トレーニングされたテキストから画像への拡散モデルを利用します。これにより、Lumiereはフルフレームレートの低解像度ビデオを直接生成できるようになり、最先端のテキストからビデオへの生成が実現します。
主な機能と能力
Lumiereは、以下を含む幅広いコンテンツ作成タスクとビデオ編集アプリケーションを提供します。
- テキストからビデオ: テキストプロンプトから直接ビデオを生成します。
- 画像からビデオ: 静止画像をダイナミックビデオにアニメーション化します。
- スタイル化された生成: 参照画像を使用して、特定のスタイルをビデオに適用します。
- ビデオのスタイル化: 一貫性のあるビデオ編集のために、テキストベースの画像編集方法を使用します。
- シネマグラフ: 画像内の特定の領域をアニメーション化します。
- ビデオインペインティング: ビデオのマスクされた領域を塗りつぶします。
ユースケース
Lumiereの汎用性により、さまざまなアプリケーションに適しています。
- コンテンツ作成: ソーシャルメディア、マーケティング、またはエンターテインメント向けの魅力的なビデオコンテンツを生成します。
- ビデオ編集: 既存のビデオにスタイルとエフェクトを適用します。
- アニメーション: リアルなモーションで静止画に命を吹き込みます。
- 特殊効果: 映画やビデオのためのユニークな視覚効果を作成します。
Lumiereの使い方は?
具体的な実装の詳細とアクセス方法は異なる場合がありますが、Lumiereは、テキストプロンプトまたは画像を入力として提供することで使用できます。次に、モデルは、提供された入力に基づいてビデオを生成し、リアルなモーションと視覚要素を組み込みます。
Lumiereを選ぶ理由?
Lumiereは、時間的に一貫性のあるビデオを生成する能力、多様なアプリケーション範囲、および最先端のパフォーマンスにより際立っています。時空間U-Netアーキテクチャにより、生成されたビデオは自然で一貫性のあるモーションの流れを持ち、コンテンツ作成とビデオ編集のための強力なツールになります。
Lumiereは誰のため?
Lumiereは、以下を対象として設計されています。
- コンテンツクリエイター: ユニークなビデオコンテンツを迅速かつ効率的に生成します。
- ビデオエディター: 既存のビデオを強化およびスタイル化します。
- アニメーター: リアルなモーションで静止画に命を吹き込みます。
- 研究者: ビデオ生成のための時空間拡散モデルの能力を探求します。
Lumiere: ビデオ生成の再定義
Lumiereの革新的なビデオ生成へのアプローチは、その時空間U-Netアーキテクチャと多様なアプリケーション範囲により、AI駆動のビデオ作成の可能性を再定義するように設定されています。Lumiereは、ユーザーがテキストまたは画像からリアルで一貫性のあるビデオを生成できるようにすることで、コンテンツクリエイター、ビデオエディター、アニメーターがビジョンを実現できるようにします。
社会的影響
Lumiereは大きな創造的可能性を提供しますが、開発者は、偽のまたは有害なコンテンツを作成するための悪用のリスクを認識しています。彼らは、偏見や悪意のあるユースケースを検出するためのツールを開発および適用し、テクノロジーの安全で公正な使用を確保することの重要性を強調しています。
その高度な機能と倫理的考慮事項への焦点により、Lumiereは、AI駆動のビデオ生成の分野における重要な一歩を表しています。
"Lumiere" のベストな代替ツール
DomoAIは、ビデオ、テキスト、画像を高品質のアニメーションに変換する無料のAIクリエイティブスタジオです。 DomoAIを使用して、あらゆるキャラクターを動かしましょう。 テキストからAIビデオを生成し、画像をアニメーション化し、映像をクリエイティブコンテンツに変換します。
Reel Studio は、テキスト、画像、または描画から AI で魅力的なビデオ、音楽、サウンドエフェクト、ボイスオーバーを生成し、クリエイターを強化します。YouTube、TikTok、Instagram コンテンツに最適。
Yolly AIは、テキストプロンプトをリアルなサウンドを備えた映画品質の4Kビデオ、または高解像度画像に数秒で変換できるオールインワンのAIビデオおよび写真ジェネレーターであり、Veo 3やDALL-EなどのトップAIモデルへのアクセスを提供します。
OpenArtは、100種類以上のモデルとスタイルを備えた無料のAI画像&ビデオジェネレーターです。アートを作成したり、画像/ビデオを編集したり、パーソナライズされたAIモデルをトレーニングしたりできます。テキストから画像、画像からビデオなどの人気アプリがあります!
Magi-1.videoを使用して、テキスト、写真、またはビデオからプロ品質のビデオと画像を作成します。オールインワンのAIビデオジェネレーター&イメージクリエータープラットフォーム。
Luma AI Dream Machine AI は、テキストや画像から高品質でリアルなビデオを迅速に作成する無料のAIビデオジェネレーターです。

TextToVideo.Bot:AI搭載のビデオエディターで、テキストをバイラルショートビデオに瞬時に変換します。あらゆるデバイスであらゆるニッチ向けの顔のないビデオを作成します。
オールインワンAIクリエーションツール:テキスト、画像、ビデオ、デジタルヒューマン作成のためのワンストップAIプラットフォーム。高度なAI機能でアイデアを素早く驚くべきビジュアルに変身。

AI音楽、画像、音声用のオールインワンAIビデオジェネレーターであるSuperMaker AIで、未来のビデオ制作を体験してください。シネマ品質のビデオを簡単に作成できます。無料で開始でき、ログインは不要です!

Tencent Hunyuan Videoは、テキストプロンプトから映画品質のビデオを生成できる、TencentによるAIビデオ生成モデルです。ダイナミックでリアル、そして芸術的なビデオの作成に優れています。
GoEnhance AIは、AIビデオおよび画像制作のためのオールインワンプラットフォームです。ビデオをアニメーションに変換し、非常に詳細な画像品質を向上させ、数分でテキストまたは画像からAIビデオを生成します。
RunAleph.com は、テキストプロンプトからビデオを変換する AI ビデオ編集ツールである Runway Aleph への無料アクセスを提供します。 Runway AI のビデオ to ビデオ AI を使用して、ビデオを編集、生成、作成します。
Lanta AI:オンラインAIビデオジェネレーター。ビデオからビデオへ、画像からビデオへ、テキストからビデオへのツールを使用して、素晴らしいAI生成ビデオを作成します。

Sora2ビデオジェネレーターは、テキストまたは画像プロンプトからプロ品質のビデオを作成するためのAI搭載プラットフォームです。リアルな物理演算、同期されたオーディオ、マルチショットの連続性、ウォーターマークなしが特徴で、ソーシャルメディア、マーケティング、映画制作に適しています。