Qwen Image の概要
Qwen Imageとは?
Qwen Imageは、AlibabaのQwenチームによって開発されたAI駆動の画像生成における画期的な進歩を表します。この200億パラメータのモデルは、画像内の複雑なテキストレンダリングを真にマスターした最初のモデルとして際立ち、特に中国語と英語のテキストを驚異的な精度で扱う点で優れています。従来のAI画像生成ツールがしばしば読みやすいテキストに苦戦するのに対し、Qwen Imageは完璧な多行レイアウト、段落レベルの意味論、細かな詳細を提供し、テキストを埋め込んだ高忠実度のビジュアルを必要とするクリエイターにとって不可欠なツールです。
Multimodal Diffusion Transformer (MMDiT) アーキテクチャによって駆動されるQwen Imageは、Multimodal Scalable Rotary Position Encoding (MSROPE)などの革新的技術を統合し、テキスト-画像の共同モデリングを強化します。これにより、記述的なプロンプトからシームレスに画像を生成し、意味的一貫性と優れた品質を確保します。マーケティング資料、ソーシャルメディアグラフィックス、教育コンテンツを作成する際、Qwen Imageの修正時に未編集領域を保持する能力が、競争の激しいAIツールの風景で差別化を図っています。
Qwen Imageの仕組みは?
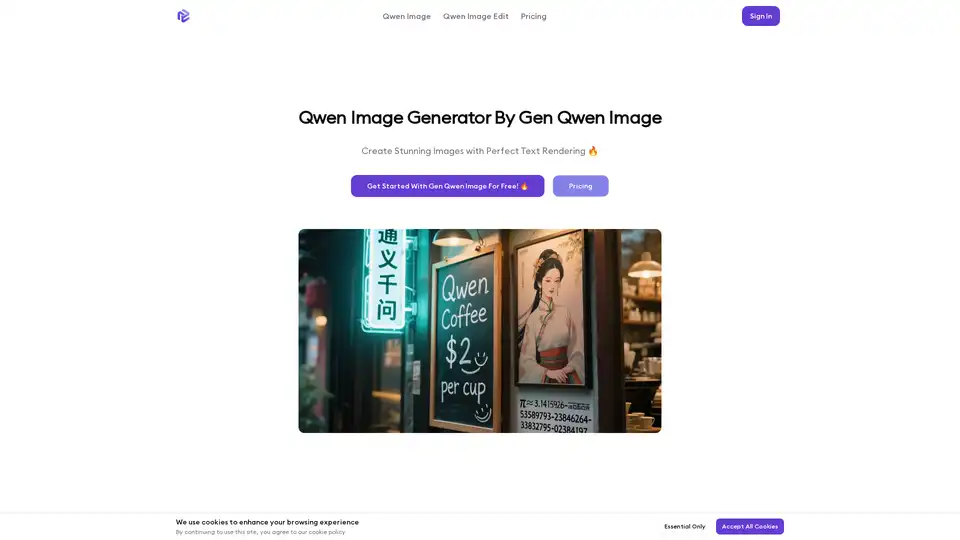
その核心では、Qwen Imageは20Bパラメータの巨大スケールを利用して多モード入力処理を行い、シンプルなテキストプロンプトを魅力的なビジュアルに変換します。MMDiTフレームワークとMSROPEの組み合わせは、テキストと画像の位置エンコーディングに優れ、フォントスタイル、レイアウト、構成などの要素に対する精密な制御を可能にします。例えば、中国語の文字が入ったコーヒーショップの看板画像を生成する場合、Qwen Imageはストローク、間隔、ネオン効果まで正確にレンダリングし、歪みなく実現します。
プロセスは4つの直感的ステップに簡略化されています:
- インターフェースにアクセス:Gen Qwen Imageの作成ページへ行き、ユーザーフレンドリーなダッシュボードをお待ちください。
- プロンプトを入力:アイデアを記述し、複雑なテキスト要素を含めて——Qwen Imageはバイリンガルプロンプトで輝きます。
- 生成の魔法:モデルが先進的な拡散技術を使って入力処理を行い、数秒で高解像度出力を生成します。
- ダウンロードして使用:画像を取得し、商用または個人プロジェクトに使用可能で、詳細を洗練するための編集オプションがあります。
このワークフローはAI画像作成を民主化するだけでなく、Apache 2.0オープンソースライセンスの下で出力が商用利用可能であることを保証し、開発者やビジネスに魅力的です。
Qwen Imageの主な特徴
Qwen Imageの特徴は精度と汎用性に特化しています:
- テキストレンダリングのブレークスルー:中国語と英語のテキストを完璧に統合、多行段落と意味の深みをサポート——バイリンガルコンテンツに理想的。
- 精密な画像編集:全体の整合性を保ちつつ特定の領域を編集、マルチタスク訓練フレームワークで駆動。
- 高性能ベンチマーク:GenEvalで0.91(0.9を超えた初)、DPGで88.32、品質指標でライバルを上回る。
- オープンソースのアクセシビリティ:完全に無料で利用可能、拡張クレジットと機能のためのサブスクリプションオプションあり。
- マルチモーダル機能:シンプルなシーンからテキストオーバーレイ付きの複雑なデザインまで、多様なプロンプトに対応。
これらの要素により、Qwen ImageはAI画像生成のリーダーとなり、特に中国語テキストの精度が重要なアジア市場を対象とするユーザーに適しています。
Qwen Imageを効果的に使用する方法
Qwen Imageの開始は簡単で、登録ユーザーには初期クレジットが提供され、可能性を探求できます。Gen Qwen Imageプラットフォームを訪れ、サインインして生成ページに移動します。「中国語の文字でネオンライト付きのQwen Coffeeを宣伝する鮮やかなポスター」などの特定のテキストを組み込んだプロンプトを作成します。ツールのインターフェースが洗練をガイドし、最適な結果のためのイテレーションを許可します。
上級ユーザー向けには、オープンソースコード経由でワークフローにQwen Imageを統合し、UIデザインや広告などの特定アプリケーション向けにモデルをカスタマイズします。ベストプラクティスは、テキストレンダリングの強みを活かす記述的で詳細なプロンプトを使用すること——曖昧な入力を避け、忠実度を最大化します。チュートリアルとYouTubeレビューは、セットアップの迅速さを強調し、通常1分以内で生成を完了します。
他のAI画像生成ツールよりQwen Imageを選ぶ理由は?
DALL-EやMidjourneyなどのツールが混在する分野で、Qwen Imageはテキストの熟練度で差別化します。競合他社が非ラテンスクリプトでつまずく中、Qwen ImageのMSROPEイノベーションは文化的関連性を確保、特に中国コンテンツクリエイター向けです。プレミアム使用で画像あたり0.025ドルとコスト効果が高く、多くの代替品より速く、完全にオープンソースで実験の障壁を低減します。
ユーザー反馈がこれを裏付けます:X(旧Twitter)で、@YakiNamaShakeのようなクリエイターがレンダリング品質を称賛し、@PrunaAIがプロフェッショナル出力の速度と手頃さを指摘します。レビューは現実的なアプリケーションを強調、テキスト埋め込みの黒板看板やポスター生成など、通常のAIアーティファクトなし。
Qwen Imageは誰向け?
このツールは幅広いオーディエンスに最適です:
- コンテンツクリエイターとマーケター:精密なテキストを要するバイリンガル広告、ソーシャルメディア投稿、プロモーショングラフィックスに理想的。
- 開発者と研究者:カスタムAIプロジェクト、データセット強化、マルチモーダル実験のためのオープンソースモデルを活用。
- グローバル市場を狙うビジネス:特にeコマースや教育で高品質中国語ビジュアルを必要とするもの。
- 趣味家と学生:無料アクセスでAI生成学習が低コストで可能。
小規模スタートアップから大企業まで、信頼できるテキスト内画像ソリューションを求めるすべての人にQwen Imageは価値があります。
実世界のアプリケーションと実用的価値
Qwen Imageは数多くのユースケースを解き放ちます。マーケティングでは、多言語スローガンテキスト付きの目を引くフライヤーを生成。教育では、正確なキャプション付きのイラスト教材を作成。開発者はAPIを基にしたアプリで自動デザイン工具を構築可能。
Xレビューの顧客事例が実用的勝利を示します:一ユーザーがLightning LoRAで2ステップの高速プロトタイプをテストし、テキストオーバーレイ付きのフォトリアリスティック結果を得ました。もう一人はコストの優位性を強調——独自モデルよりはるかに安価——優れた詳細を維持。
実用的価値は効率にあります:手動編集時間を節約、編集可能出力でブランド一貫性を確保、ライセンスの障害なく商用スケール。テキストレンダリングの障壁を打破し、Qwen Imageはユーザーにプロフェッショナル級コンテンツを容易に制作可能にします。
Qwen Imageに関するよくある質問
Qwen Imageの中国語テキストレンダリングがなぜ高度か? Qwen Imageはストローク順序、レイアウト、意味論を扱う専門トレーニングを使用し、非英語テキストのベンチマークで他を上回ります。
商用プロジェクトに適しているか? はい、Apache 2.0ライセンスが完全な商用利用を許可、ビジネス向けに最適化された高解像度エクスポートなどのプラットフォーム機能あり。
速度はどうか? ユーザーは生成時間を速いと報告、特に4ステップLightning LoRAのような最適化で、反復ワークフローに理想的です。
詳細はsupport@genqwenimage.comまでお問い合わせください。
要約すると、Qwen Imageはテキスト精度とマルチモーダル優秀性を優先し、AI画像生成を再定義、世界中のクリエイターに比類ない価値を提供します。今日Gen Qwen Imageで試して、ビジュアルコンテンツ作成の未来を体験してください。
"Qwen Image" のベストな代替ツール
ByteDanceのSeedream 4.0は、わずか1.8秒で超高精細4K画像を生成する最先端のAI画像ジェネレーターです。高度なテキストレンダリングと自然言語編集機能を提供します。
Qwen Imageは、アリババによる無料のオープンソースAI画像ジェネレーターで、テキストレンダリングに優れています。マーケティング資料、ソーシャルメディアコンテンツ、正確なテキスト配置による多言語ビジュアルの作成に最適です。
Seedream 4.0は、次世代のAI画像ジェネレーターおよびエディターです。数秒で高品質の2K画像を作成し、正確なテキストから画像へのツールでアイデアを変換し、プロレベルの創造性のための高度な編集をお楽しみください。無料でお試しください。
AI Library を探索し、2150 以上のニューラルネットワークと生成コンテンツ作成のための AI ツールの包括的なカタログをご覧ください。テキストから画像、ビデオ生成などのトップ AI アートモデルを発見し、クリエイティブプロジェクトを強化します。
Mangraは、iPhone、iPad、Mac向けのAI搭載アプリで、マンガ、マンファ、マンフア、ウェブトゥーンを瞬時に翻訳します。30以上の言語で正確なオフライン対応のコミック読みを楽しむシームレスなAI技術で。
Vagent は、n8n で構築されたカスタム AI エージェント向けにクリーンで音声対応のインターフェースを提供します。単一の webhook で統合し、60 以上の言語で自然な音声インタラクションが可能で、ローカルデータストレージで登録不要です。
OpenAI 画像生成 API を探索して、GPT Image や DALL·E などのモデルを使用してテキストプロンプトから美しい画像を作成・編集します。AI 駆動のビジュアルコンテンツを統合する開発者に最適です。
TacoTranslate を使用すると、React アプリケーションを新しい市場に自動 i18n で導入できます。75 以上の言語からの翻訳。Next.js に最適です。
X Moji は iPhone 向けの強力な AI 絵文字生成器アプリで、テキストとセルフィーをユニークなカスタム絵文字に変換します。クリエイティブモードを探索し、絵文字パックを作成し、Genmoji のトップ代替として簡単に共有。
写真と動画を瞬時にリアルな話すAIアバターに変換。40以上の言語でリップシンクのプロフェッショナルビデオ。今日から無料で作成を始めよう!
Qwen Image AI は、英語と中国語で卓越したテキスト レンダリングを備えた、高忠実度画像生成のための最先端の AI モデルです。 AI の精度で画像を編集します。
Kie.aiのGPT-Image-1 APIを使用して高品質の4o画像を生成します。鮮明なビジュアル、柔軟なスタイル、正確なテキストレンダリング。無料テストとスケーラブル。
Flux AI Proは、FLUX1.1 Ultraモデルを搭載し、テキストレンダリングとプロンプトフォローに優れた高度なAI画像ジェネレーターです。