
Baseten 개요
Baseten이란 무엇입니까?
Baseten은 AI 모델의 프로덕션 환경 배포 및 확장을 간소화하도록 설계된 플랫폼입니다. AI 제품을 빠르게 시장에 출시하는 데 필요한 인프라, 도구 및 전문 지식을 제공합니다.
Baseten은 어떻게 작동합니까?
Baseten의 플랫폼은 최첨단 성능 연구, 클라우드 네이티브 인프라 및 추론을 위해 설계된 개발자 경험을 포함하는 Baseten Inference Stack을 중심으로 구축되었습니다.
다음은 주요 구성 요소에 대한 분석입니다.
- 모델 API: 프로덕션급 성능으로 새로운 워크로드, 프로토타입 제품을 빠르게 테스트하고 최신 모델을 평가합니다.
- Baseten에서 훈련: 제한이나 오버헤드 없이 추론에 최적화된 인프라를 사용하여 모델을 훈련합니다.
- 응용 성능 연구: 사용자 정의 커널, 디코딩 기술 및 고급 캐싱을 활용하여 모델 성능을 최적화합니다.
- 클라우드 네이티브 인프라: 빠른 콜드 스타트와 높은 가동 시간으로 모든 지역 및 클라우드(Baseten 클라우드 또는 자체 클라우드)에서 워크로드를 확장합니다.
- 개발자 경험 (DevEx): 프로덕션 환경에 적합한 개발자 경험으로 모델과 복합 AI 솔루션을 배포, 최적화 및 관리합니다.
주요 기능 및 이점
- 전용 배포: 대규모 워크로드를 위해 설계되었으며 프로덕션을 위해 구축된 인프라에서 오픈 소스, 사용자 정의 및 미세 조정된 AI 모델을 제공할 수 있습니다.
- 멀티 클라우드 용량 관리: Baseten 클라우드, 자체 호스팅 또는 주문형으로 워크로드를 유연하게 실행합니다. 이 플랫폼은 모든 클라우드 공급자와 호환됩니다.
- 사용자 정의 모델 배포: 즉시 사용 가능한 성능 최적화를 통해 모든 사용자 정의 또는 독점 모델을 배포합니다.
- Gen AI 지원: Gen AI 애플리케이션에 맞게 조정된 사용자 정의 성능 최적화.
- 모델 라이브러리: 미리 빌드된 모델을 쉽게 탐색하고 배포합니다.
특정 응용 분야
Baseten은 다음을 포함한 다양한 AI 응용 분야에 적합합니다.
- 이미지 생성: 사용자 정의 모델 또는 ComfyUI 워크플로를 제공하고, 사용 사례에 맞게 미세 조정하거나, 몇 분 안에 모든 오픈 소스 모델을 배포합니다.
- 전사: 빠르고 정확하며 비용 효율적인 전사를 위해 사용자 정의된 Whisper 모델을 활용합니다.
- 텍스트 음성 변환: 짧은 대기 시간의 AI 전화 통화, 음성 에이전트, 번역 등을 위한 실시간 오디오 스트리밍을 지원합니다.
- 대규모 언어 모델 (LLM): 전용 배포를 통해 DeepSeek, Llama 및 Qwen과 같은 모델에서 더 높은 처리량과 더 낮은 대기 시간을 달성합니다.
- 임베딩: 다른 솔루션에 비해 더 높은 처리량과 더 낮은 대기 시간으로 Baseten Embeddings Inference (BEI)를 제공합니다.
- 복합 AI: 복합 AI에 대한 세분화된 하드웨어 및 자동 크기 조정을 가능하게 하여 GPU 사용량을 개선하고 대기 시간을 줄입니다.
Baseten을 선택해야 하는 이유?
다음은 Baseten이 눈에 띄는 몇 가지 이유입니다.
- 성능: 빠른 추론 시간을 위해 최적화된 인프라.
- 확장성: Baseten의 클라우드 또는 자체 클라우드에서 원활한 확장.
- 개발자 경험: 프로덕션 환경을 위해 설계된 도구 및 워크플로.
- 유연성: 오픈 소스, 사용자 정의 및 미세 조정된 모델을 포함한 다양한 모델을 지원합니다.
- 비용 효율성: 리소스 활용률을 최적화하여 비용을 절감합니다.
Baseten은 누구를 위한 것입니까?
Baseten은 다음에 적합합니다.
- 머신 러닝 엔지니어: 모델 배포 및 관리를 간소화합니다.
- AI 제품 팀: AI 제품의 시장 출시 시간을 가속화합니다.
- 기업: 확장 가능하고 안정적인 AI 인프라를 찾고 있습니다.
고객 평가
- Nathan Sobo, 공동 창립자: Baseten은 사용자와 회사에 가능한 최고의 경험을 제공했습니다.
- Sahaj Garg, 공동 창립자 겸 CTO: Baseten 팀과 함께 추론 파이프라인을 크게 제어하고 각 단계를 최적화했습니다.
- Lily Clifford, 공동 창립자 겸 CEO: Rime의 최첨단 대기 시간 및 가동 시간은 Baseten과의 기본 사항에 대한 공유된 초점에 의해 주도됩니다.
- Isaiah Granet, CEO 겸 공동 창립자: GPU 및 확장에 대해 걱정하지 않고 엄청난 수익을 올릴 수 있었습니다.
- Waseem Alshikh, Writer의 CTO 겸 공동 창립자: 내부 엔지니어링 팀에 부담을 주지 않고 맞춤형으로 구축된 LLM을 위한 비용 효율적이고 고성능 모델 서비스를 달성했습니다.
Baseten은 프로덕션 환경에서 AI 모델을 배포하고 확장하기 위한 포괄적인 솔루션을 제공하여 높은 성능, 유연성 및 사용자 친화적인 개발자 경험을 제공합니다. 이미지 생성, 전사, LLM 또는 사용자 정의 모델을 사용하든 Baseten은 전체 프로세스를 간소화하는 것을 목표로 합니다.
"Baseten"의 최고의 대체 도구

Cloudflare Workers AI를 사용하면 Cloudflare의 글로벌 네트워크에서 사전 훈련된 머신러닝 모델에 대해 서버리스 AI 추론 작업을 실행할 수 있습니다. 다양한 모델을 제공하고 다른 Cloudflare 서비스와 원활하게 통합됩니다.
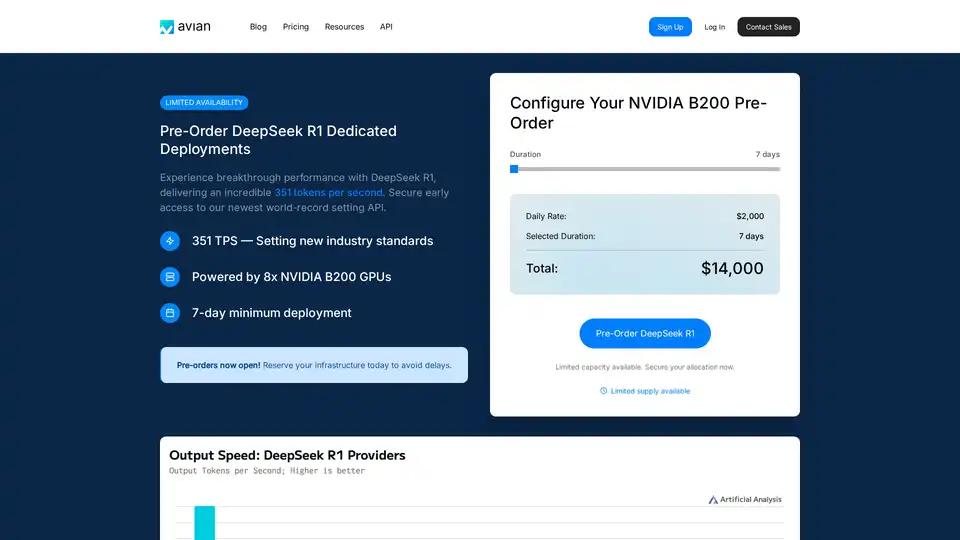
Avian API는 오픈 소스 LLM에 가장 빠른 AI 추론을 제공하여 DeepSeek R1에서 351 TPS를 달성합니다. OpenAI 호환 API를 사용하여 HuggingFace LLM을 3~10배 빠른 속도로 배포하십시오. 엔터프라이즈급 성능 및 개인 정보 보호.
AIMLAPI는 단일, 낮은 대기 시간 API를 통해 300개 이상의 AI 모델에 대한 액세스를 제공합니다. 머신 러닝을 위한 빠르고 비용 효율적인 AI 솔루션으로 OpenAI에 비해 최대 80%를 절약하십시오.

Float16.cloud는 AI 개발을 위한 서버리스 GPU를 제공합니다. 사용량에 따른 요금제로 H100 GPU에 모델을 즉시 배포하십시오. LLM, 미세 조정 및 교육에 이상적입니다.

Friendli Inference는 가장 빠른 LLM 추론 엔진으로, 속도와 비용 효율성을 위해 최적화되어 높은 처리량과 짧은 대기 시간을 제공하면서 GPU 비용을 50~90% 절감합니다.

NVIDIA NIM API를 탐색하여 주요 AI 모델의 최적화된 추론 및 배포를 구현하십시오. 서버리스 API를 사용하여 엔터프라이즈 생성 AI 애플리케이션을 구축하거나 GPU 인프라에서 자체 호스팅하십시오.

Runpod는 AI 모델 구축 및 배포를 단순화하는 AI 클라우드 플랫폼입니다. AI 개발자를 위해 온디맨드 GPU 리소스, 서버리스 확장 및 엔터프라이즈급 가동 시간을 제공합니다.

GPUX는 StableDiffusionXL, ESRGAN, AlpacaLLM과 같은 AI 모델을 위해 1초 콜드 스타트를 가능하게 하는 서버리스 GPU 추론 플랫폼으로, 최적화된 성능과 P2P 기능을 갖추고 있습니다.

개발자를 위한 번개처럼 빠른 AI 플랫폼. 간단한 API로 200개 이상의 최적화된 LLM과 멀티모달 모델 배포, 미세 조정 및 실행 - SiliconFlow.

Inferless는 ML 모델 배포를 위한 초고속 서버리스 GPU 추론을 제공합니다. 자동 확장, 동적 배치 처리, 기업 보안 등의 기능으로 확장 가능하고 수월한 맞춤형 머신러닝 모델 배포를 가능하게 합니다.

Runpod는 AI 모델 구축 및 배포를 간소화하는 올인원 AI 클라우드 플랫폼입니다. 강력한 컴퓨팅 및 자동 스케일링으로 AI를 쉽게 훈련, 미세 조정 및 배포하십시오.

Synexa를 사용하여 AI 배포를 간소화하세요. 단 한 줄의 코드로 강력한 AI 모델을 즉시 실행할 수 있습니다. 빠르고 안정적이며 개발자 친화적인 서버리스 AI API 플랫폼입니다.

fal.ai: Gen AI를 사용하는 가장 쉽고 비용 효율적인 방법입니다. 무료 API와 함께 생성 미디어 모델을 통합합니다. 600개 이상의 프로덕션 준비 모델입니다.
Julep AI: AI 에이전트 워크플로를 구축하기 위한 백엔드. 완전한 추적성과 제로 운영 오버헤드로 AI 에이전트를 설계, 배포 및 확장합니다.