DataChain 개요
DataChain이란 무엇인가요?
DataChain은 고급 머신러닝과 인공지능 시대에서 대용량 데이터의 복잡성을 처리하기 위해 설계된 AI 네이티브 플랫폼입니다. 비디오, 오디오 파일, PDF, 이미지, MRI 스캔,甚至 임베딩을 포함한 다중 모드 데이터셋을 위한 중앙 집중식 레지스트리를 제공하여 두각을 나타냅니다. S3, GCS 또는 Azure와 같은 객체 저장소에 저장된 비정형 또는 대규모 데이터를 처리하는 데 어려움을 겪는 기존 SQL 기반 도구와 달리, DataChain은 개발자 친화적인 워크플로와 기업 규모 처리 간의 격차를 해소합니다. 이 플랫폼은 스타트업부터 포춘 500 기업까지 데이터셋을 효율적으로 큐레이션, 강화 및 버전 관리하여 원시 다중 모드 입력을 실행 가능한 AI 지식으로 전환할 수 있도록 합니다.
핵심에서 DataChain은 빅데이터에서 이른바 '헤비 데이터'——AI 애플리케이션을 위한 미개발 잠재력으로 가득한 풍부한 비정형 형식——로의 전환을 해결합니다. 에이전트, 코파일럿 또는 적응형 워크플로를 구축하는 경우에도 DataChain은 데이터 파이프라인이 지속적인 재처리를 요구하지 않도록 보장하여 시간과 자원을 절약하면서 더 깊은 통찰력을 제공합니다.
DataChain은 어떻게 작동하나요?
DataChain은 개발자 최우선 철학으로 운영되며, Python의 단순성과 SQL과 같은 작업의 확장성을 결합합니다. 주요 메커니즘의 breakdown은 다음과 같습니다:
중앙 집중식 데이터셋 레지스트리: 모든 데이터셋은 전체 계보, 메타데이터 및 버전 관리로 추적됩니다. 사용자 인터페이스(UI), 채팅 인터페이스, 통합 개발 환경(IDE) 또는甚至 모델 제어 프로토콜(MCP)을 통한 AI 에이전트를 통해 원활하게 액세스할 수 있습니다. 이 레지스트리는 단일 진실 공급원으로 작동하여 종속성 관리와 결과 재현을 쉽게 만듭니다.
Python 단순성과 SQL 규모의 만남: 개발자는 코드와 데이터 작업 모두에서 하나의 친숙한 언어——Python——으로 작성합니다. 이는 별도의 SQL 도구로 인해 생성된 사일로를 제거하여 IDE 및 AI 에이전트와의 통합을 강화합니다. 예를 들어, 컨텍스트를 전환하지 않고 헤비 데이터를 쿼리 및 조작할 수 있어 워크플로를 간소화합니다.
로컬 개발 및 클라우드 확장: 빠른 반복을 위해 로컬 IDE에서 데이터 파이프라인 구축 및 테스트를 시작합니다. 준비되면 코드 재작업 없이 클라우드에서 수백 개의 GPU로 effortless하게 확장합니다. 이 하이브리드 접근 방식은 대규모 작업의 성능을 저해하지 않으면서 생산성을 극대화합니다.
제로 데이터 복사 및 잠금 방지: 원본 파일——비디오, 이미지, 오디오——은 S3와 같은 기본 저장소에 유지됩니다. DataChain은 단순히 참조 및 버전 추적하여 불필요한 중복 또는 공급업체 잠금을 방지합니다. 이는 비용을 절감할 뿐만 아니라 데이터 주권과 유연성을 보장합니다.
플랫폼은 대규모 언어 모델(LLM) 및 머신러닝 모델을 활용하여 비정형 소스에서 구조, 임베딩 및 통찰력을 추출합니다. 예를 들어, ETL(추출, 변환, 로드) 프로세스 중에 비디오 또는 PDF에 모델을 적용하여 혼란을 AI 준비 형식으로 조직할 수 있습니다.
DataChain의 핵심 기능
DataChain의 도구 세트는 AI 프로젝트의 데이터 처리 모든 단계를 coverage합니다. 주요 기능은 다음을 포함합니다:
다중 모드 데이터 숙달: 비디오(🎥), 오디오(🎧), PDF(📄), 이미지(🖼️), 의료 스캔(🔬 MRI)과 같은 다양한 형식을 한 곳에서 처리. 비정형 콘텐츠를 effortless하게 처리하기 위해 LLM을 사용하여 통찰력 추출.
원활한 ETL 파이프라인: 원시 파일을 강화된 데이터셋으로 변환하는 자동화된 워크플로 구축. 실험 추적부터 모델 버전 관리까지 모든 것을 powering하는 대규모 데이터 필터링, 조인 및 업데이트.
데이터 계보 및 재현성: 코드, 데이터 및 모델 간의 모든 종속성 추적. 주문형으로 데이터셋 재현 및 업데이트 자동화——재현 가능한 ML 연구 및 compliance에 중요.
대규모 처리: 병목 현상 없이 수백만 또는 수십억 개의 파일 관리. 업데이트를 효율적으로 계산 및 고급 필터링을 위해 ML 활용——헤비 데이터 시나리오에 이상적.
통합 및 접근성: UI, 채팅, IDE, 에이전트 지원. GitHub 저장소를 통한 오픈소스 요소는 사용자 정의를允许하며, 클라우드 기반 Studio는 즉시 사용 가능한 환경을 제공.
이러한 기능은 글로벌 industry 리더와의 신뢰할 수 있는 파트너십으로 지원되어 high-stakes AI 배포의 reliability를 보장합니다.
DataChain 사용 방법
DataChain 시작은 straightforward且 무료로 시작할 수 있습니다:
가입: DataChain 웹사이트에서 계정 생성하여 플랫폼 액세스. 선불 비용 없음——즉시 탐색 시작.
환경 설정: 객체 저장소(예: S3) 연결 및 데이터셋 가져오기. 직관적인 UI 또는 Python SDK 사용하여 데이터 큐레이션 시작.
파이프라인 구축: Python을 사용하여 로컬 IDE에서 개발. 강화를 위해 ML 모델 적용 후 확장을 위해 클라우드에 배포.
버전 관리 및 추적: 메타데이터 및 계보로 데이터셋 등록. 에이전트 상호 작용을 위해 MCP 사용 또는 자연어를 통해 쿼리.
모니터링 및 반복: 레지스트리 활용하여 결과 재현, ETL을 통해 데이터셋 업데이트, AI 모델에 대한 통찰력 분석.
문서, Quick Start 가이드 및 Discord community 지원으로 온보딩을 원활하게 합니다. 엔터프라이즈 needs의 경우 규모에 맞춘 가격 및 기능에 대해 sales에 문의.
DataChain을 선택하는 이유
AI가 더 크고 복잡한 데이터셋을 요구하는 landscape에서 DataChain은 헤비 데이터를 접근 가능하고 관리 가능하게 만들어 경쟁 우위를 제공합니다. 기존 도구는 비정형 형식에서 shortfall하여 사일로와 비효율을 초래합니다. DataChain은 제로 복사 접근 방식으로 이러한 pain points를 제거하며, 경우에 따라 저장 비용을 최대 100% 절감하고, 개발자 중심 설계는 insight까지의 시간을 가속화합니다.
DataChain을 사용하는 팀은 더 빠른 실험 추적, 원활한 모델 버전 관리 및 강력한 파이프라인 자동화를 보고합니다. 반복적 AI 개발에서 재처리 회피에 특히 valuable하며, 데이터 또는 모델의 변경이 otherwise 수시간의 rework로 cascade될 수 있습니다. 게다가, 잠금 없이 인프라에 대한 control을 유지합니다.
대안과 비교하여 DataChain의 다중 모드 헤비 데이터에 대한 초점이 두드러집니다——それは単なる 다른 데이터 관리 도구가 아닙니다; 생성 모델부터 실시간 에이전트까지 다음 AI 물결을 위해 구축되었습니다.
DataChain은 누구를 위한 것인가요?
DataChain은 AI 생태계의广泛的 user에게 이상적입니다:
개발자 및 데이터 과학자: SQL 장애물 없이 다중 모드 데이터를 위한 Python 네이티브 도구가 필요한 ML 파이프라인 구축자.
스타트업 및 기업의 AI/ML 팀: 비디오 분석, 오디오 transcriptions 또는 의료 이미징을 다루는 초기 단계 혁신자부터 포춘 500 기업까지.
연구원 및 분석가: 컴퓨터 비전, NLP 또는 다중 모드 AI의 실험을 위한 전체 계보를 가진 재현 가능한 데이터셋을 요구하는任何人.
제품 빌더: 강화된, 버전 관리된 지식 기반에 의존하는 코파일럿, 에이전트 또는 적응형 시스템 생성자.
객체 저장소의 비정형 데이터를 grappling하고 오버헤드 없이 AI에 활용하려는 경우 DataChain은您的 go-to solution입니다.
실용적 가치 및 사용 사례
DataChain은 헤비 데이터를 전략적 자산으로 변환하여 tangible value를 제공합니다. 이러한 실제 applications을 고려하세요:
미디어 및 엔터테인먼트: 추천 엔진 또는 콘텐츠 moderation을 위한 임베딩 추출을 위해 비디오 및 오디오 library 처리.
의료: AI 주진단을 위한 MRI 스캔 및 PDF 버전 관리, 데이터 계보 추적으로 compliance 보장.
이커머스: LLM을 사용하여 제품 이미지 및 설명 강화, personalized search 및 virtual try-on 기능 구축.
연구실: 다중 모드 학습에서 대규모 데이터셋에 대한 ETL 자동화, 모델 training cycles 가속화.
사용자는其 확장성——수십억 개의 파일을 effortlessly 처리——및 IDE 통합からの 생산성 향상을称赞합니다. 가격 details는 연락으로 available하지만, 무료 tier는 실험 barriers를 낮춥니다.
요약하면, DataChain은 규모에서 AI를 위한 데이터 관리를 redefines합니다. 최소 friction으로 다중 모드 데이터셋을 큐레이션, 강화 및 버전 관리함으로써 efficient teams가 헤비 데이터 revolution에서 lead할 수 있도록 합니다. 데이터를 AI advantage로 전환할 준비가 되셨나요? 오늘 가입하고 오픈소스 기여를 위해 GitHub를 explore하세요.
"DataChain"의 최고의 대체 도구
ProductCore를 발견하세요. 이는 24/7 인텔리전스, 빠른 실험, AI 네이티브 컨설팅 서비스를 위한 6개의 전문 에이전트를 사용한 AI 플랫폼으로, 제품 관리를 혁신하며 학습 속도와 전략적 결정을 높입니다.
ZekAI는 맞춤 채팅을 위한 Assistant, 쓰기 작업을 위한 Author, 이미지 생성을 위한 Designer, 문서 상호작용을 위한 Explorer와 같은 도구를 제공하는 다용도 AI 플랫폼입니다. GPT-4o와 같은 최고 모델에 액세스하여 교육, 소매, 미디어 분야의 생산성을 향상시키세요.

개발자를 위한 번개처럼 빠른 AI 플랫폼. 간단한 API로 200개 이상의 최적화된 LLM과 멀티모달 모델 배포, 미세 조정 및 실행 - SiliconFlow.
Robovision의 AI 기반 컴퓨터 비전 플랫폼으로 지능형 자동화를 발견하세요. 딥러닝으로 시각 데이터를 처리하여 제조 및 농업과 같은 산업에서 효율적인 모델 훈련과 배포를 가능하게 합니다.
Agent TARS는 브라우저 작업, 명령줄, 파일 시스템을 원활하게 통합하여 워크플로 자동화를 강화하는 오픈소스 멀티모달 AI 에이전트입니다. 고급 시각 해석과 정교한 추론으로 효율적인 작업 처리를 경험하세요.
Slazzer는 AI 기반 도구로, 몇 초 만에 이미지 배경을 자동으로 제거합니다. 사진을 업로드하면 즉시 컷아웃이 가능하며, 전자상거래, 사진, 디자인에 적합하며 수동 편집이 필요 없습니다.
콘텐츠, 이미지, 비디오, 음성 생성; 자동화 워크플로, 맞춤 AI 앱, 지능형 에이전트 제작. 당신의 독점 AI 앱 맞춤형 워크스테이션.
연구, 글쓰기, 코딩, 이미지 생성, 파일 분석 등에 최적화된 최고의 AI 도구로 매일 더 많은 일을 해내세요. 오늘 Ninja를 무료로 시도해 보세요.
BasicAI는 AI/ML 모델을 위한 선도적인 데이터 주석 플랫폼과 전문 라벨링 서비스를 제공하며, AV, ADAS, 스마트 시티 애플리케이션에서 수천 명의 사용자에게 신뢰받습니다. 7년 이상의 전문 지식으로 고품질, 효율적인 데이터 솔루션을 보장합니다.
Xander는 노코드 AI 모델 훈련을 가능하게 하는 오픈 소스 데스크톱 플랫폼입니다. 자연어로 작업을 설명하면 텍스트 분류, 이미지 분석, LLM 미세 조정에 대한 자동화된 파이프라인을 실행하며, 로컬 머신에서 프라이버시와 성능을 보장합니다。
Falcon LLM은 TII의 오픈소스 생성 대형 언어 모델 계열로, Falcon 3, Falcon-H1, Falcon Arabic 등의 모델을 통해 일상 기기에서 효율적으로 실행되는 다국어·멀티모달 AI 애플리케이션을 제공합니다.
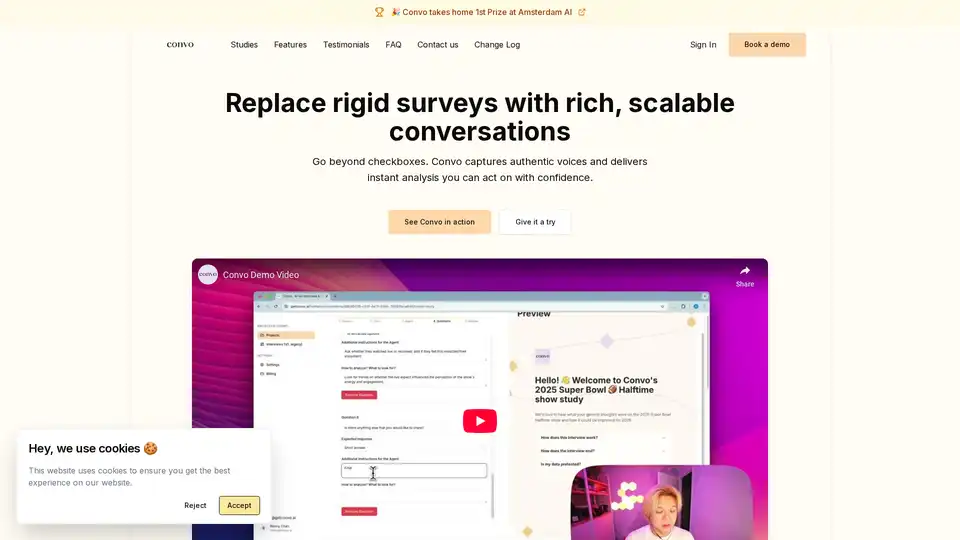
AI 기반 사용자 인터뷰로 질적 연구를 확장하세요. 즉시 통찰을 얻고 피드백을 10배 빠르게 분석. LinkedIn, Ford, Miro가 신뢰. 무료 시도.
AI ASMR ONE을 발견하세요. 간단한 텍스트 프롬프트에서 동기화된 사운드와 함께 독특하고 안정된 ASMR 비디오를 즉시 생성하는 무료 도구. 개인화된 휴식과 창의적 트리거에 완벽합니다.