Baseten

Visão geral de Baseten
O que é Baseten?
Baseten é uma plataforma projetada para simplificar a implantação e o dimensionamento de modelos de AI em produção. Ela fornece a infraestrutura, as ferramentas e a experiência necessárias para levar os produtos de AI ao mercado rapidamente.
Como funciona o Baseten?
A plataforma da Baseten é construída em torno do Baseten Inference Stack, que inclui pesquisa de ponta em desempenho, infraestrutura nativa da nuvem e uma experiência de desenvolvedor projetada para inferência.
Aqui está uma análise dos principais componentes:
- Model APIs: Teste rapidamente novas cargas de trabalho, protótipos de produtos e avalie os modelos mais recentes com desempenho de nível de produção.
- Training on Baseten: Treine modelos usando infraestrutura otimizada para inferência sem restrições ou sobrecarga.
- Applied Performance Research: Utilize kernels personalizados, técnicas de decodificação e cache avançado para otimizar o desempenho do modelo.
- Cloud-Native Infrastructure: Dimensione as cargas de trabalho em qualquer região e nuvem (Baseten Cloud ou a sua própria), com inicializações rápidas e alta disponibilidade.
- Developer Experience (DevEx): Implante, otimize e gerencie modelos e soluções de AI compostas com uma experiência de desenvolvedor pronta para produção.
Principais recursos e benefícios
- Dedicated Deployments: Projetado para cargas de trabalho de alta escala, permitindo que você atenda modelos de AI de código aberto, personalizados e ajustados em infraestrutura construída para produção.
- Multi-Cloud Capacity Management: Execute cargas de trabalho no Baseten Cloud, auto-hospede ou flexibilize sob demanda. A plataforma é compatível com qualquer provedor de nuvem.
- Custom Model Deployment: Implante qualquer modelo personalizado ou proprietário com otimizações de desempenho prontas para uso.
- Support for Gen AI: Otimizações de desempenho personalizadas, adaptadas para aplicações Gen AI.
- Model Library: Explore e implemente modelos pré-construídos com facilidade.
Aplicações específicas
A Baseten atende a uma variedade de aplicações de AI, incluindo:
- Image Generation: Sirva modelos personalizados ou fluxos de trabalho ComfyUI, ajuste para seu caso de uso ou implemente qualquer modelo de código aberto em minutos.
- Transcription: Utiliza um modelo Whisper personalizado para transcrição rápida, precisa e econômica.
- Text-to-Speech: Suporta streaming de áudio em tempo real para chamadas telefônicas de AI de baixa latência, agentes de voz, tradução e muito mais.
- Large Language Models (LLMs): Obtenha maior throughput e menor latência para modelos como DeepSeek, Llama e Qwen com Dedicated Deployments.
- Embeddings: Oferece Baseten Embeddings Inference (BEI) com maior throughput e menor latência em comparação com outras soluções.
- Compound AI: Permite hardware granular e escalonamento automático para AI composta, melhorando o uso da GPU e reduzindo a latência.
Por que escolher a Baseten?
Aqui estão vários motivos pelos quais a Baseten se destaca:
- Performance: Infraestrutura otimizada para tempos de inferência rápidos.
- Scalability: Dimensionamento contínuo na nuvem da Baseten ou na sua própria.
- Developer Experience: Ferramentas e fluxos de trabalho projetados para ambientes de produção.
- Flexibility: Suporta vários modelos, incluindo modelos de código aberto, personalizados e ajustados.
- Cost-Effectiveness: Otimiza a utilização de recursos para reduzir custos.
Para quem é a Baseten?
A Baseten é ideal para:
- Machine Learning Engineers: Simplifique a implantação e o gerenciamento de modelos.
- AI Product Teams: Acelere o tempo de lançamento no mercado para produtos de AI.
- Companies: Buscando infraestrutura de AI escalável e confiável.
Depoimentos de clientes
- Nathan Sobo, Co-founder: A Baseten proporcionou a melhor experiência possível para os usuários e a empresa.
- Sahaj Garg, Co-founder e CTO: Ganhou muito controle sobre o pipeline de inferência e otimizou cada etapa com a equipe da Baseten.
- Lily Clifford, Co-founder e CEO: A latência e o tempo de atividade de última geração da Rime são impulsionados por um foco compartilhado nos fundamentos com a Baseten.
- Isaiah Granet, CEO e Co-founder: Permitiu números de receita insanos sem se preocupar com GPUs e escalonamento.
- Waseem Alshikh, CTO e Co-founder da Writer: Alcançou um serviço de modelo de alto desempenho e econômico para LLMs construídos sob medida, sem sobrecarregar as equipes de engenharia internas.
A Baseten fornece uma solução abrangente para implantar e dimensionar modelos de AI em produção, oferecendo alto desempenho, flexibilidade e uma experiência de desenvolvedor amigável. Se você estiver trabalhando com geração de imagens, transcrição, LLMs ou modelos personalizados, a Baseten tem como objetivo simplificar todo o processo.
Melhores ferramentas alternativas para "Baseten"

O Cloudflare Workers AI permite que você execute tarefas de inferência de IA sem servidor em modelos de aprendizado de máquina pré-treinados na rede global da Cloudflare, oferecendo uma variedade de modelos e integração perfeita com outros serviços da Cloudflare.
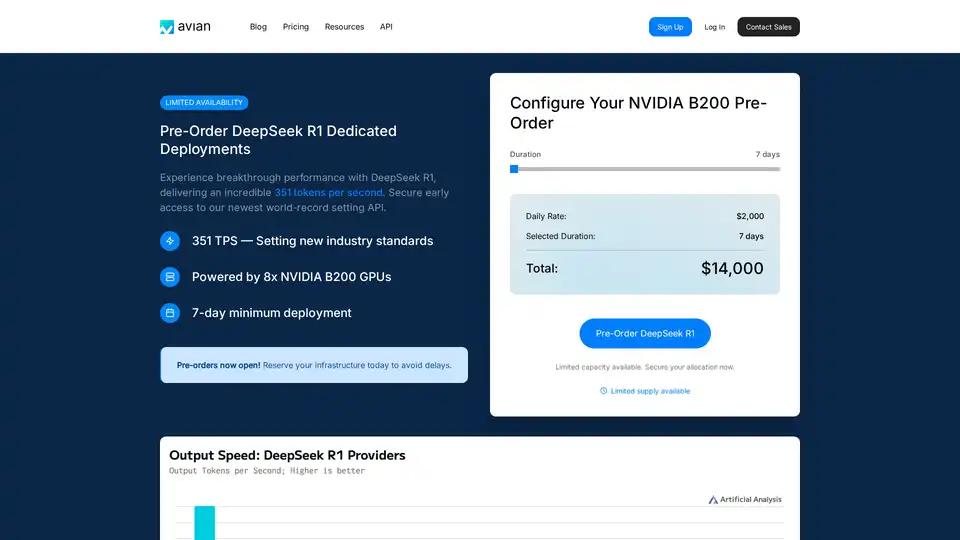
A Avian API oferece a inferência de IA mais rápida para LLMs de código aberto, atingindo 351 TPS no DeepSeek R1. Implante qualquer LLM HuggingFace com uma velocidade de 3 a 10 vezes maior com uma API compatível com OpenAI. Desempenho e privacidade de nível empresarial.
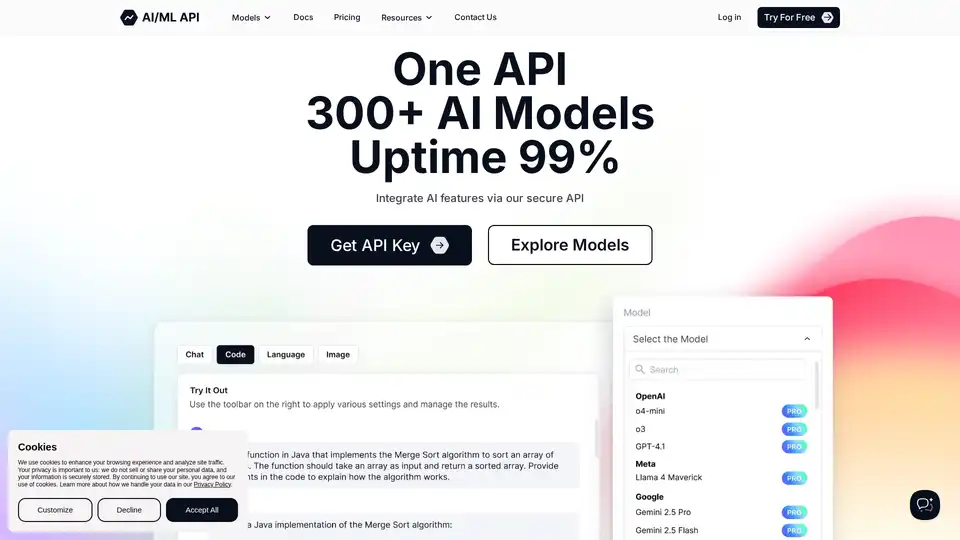
AIMLAPI fornece acesso a mais de 300 modelos de IA através de uma única API de baixa latência. Economize até 80% em comparação com o OpenAI com soluções de IA rápidas e econômicas para aprendizado de máquina.

Float16.cloud oferece GPUs sem servidor para desenvolvimento de IA. Implante modelos instantaneamente em GPUs H100 com preços de pagamento por uso. Ideal para LLM, ajuste fino e treinamento.
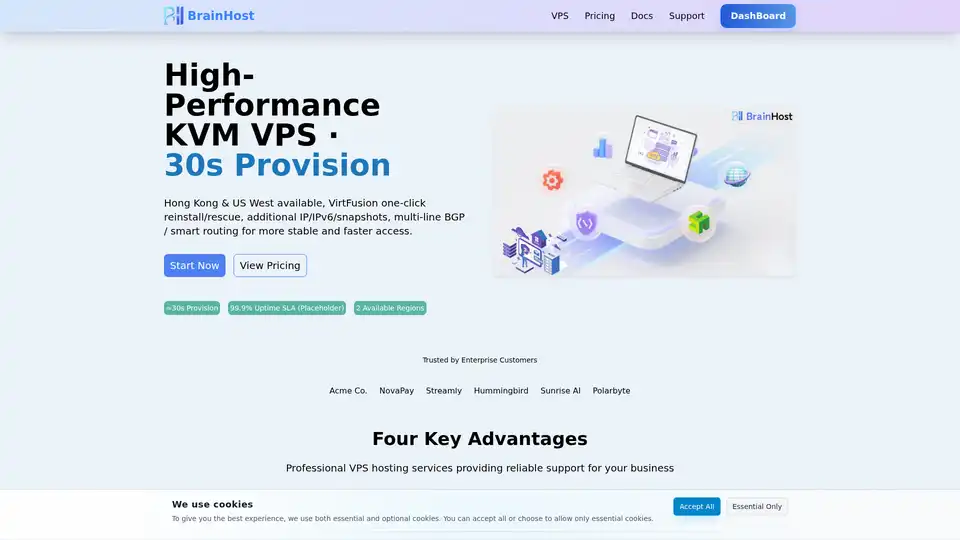
BrainHost VPS oferece servidores virtuels KVM de alto desempenho com armazenamento NVMe, ideal para inferência de IA, sites web e e-commerce. Provisionamento rápido em 30s em Hong Kong e US West garante acesso global confiable.

Explore as APIs NVIDIA NIM para inferência otimizada e implantação de modelos de IA líderes. Crie aplicativos de IA generativa empresarial com APIs sem servidor ou auto-hospedagem em sua infraestrutura de GPU.

Runpod é uma plataforma de nuvem de IA que simplifica a construção e a implantação de modelos de IA. Oferecendo recursos de GPU sob demanda, escalonamento sem servidor e tempo de atividade de nível empresarial para desenvolvedores de IA.

GPUX é uma plataforma de inferência GPU sem servidor que permite inicializações a frio de 1 segundo para modelos de IA como StableDiffusionXL, ESRGAN e AlpacaLLM com desempenho otimizado e capacidades P2P.

Plataforma de IA ultrarrápida para desenvolvedores. Implante, ajuste e execute mais de 200 LLMs e modelos multimodais otimizados com APIs simples - SiliconFlow.
PremAI é um laboratório de pesquisa de IA que fornece modelos de IA seguros e personalizados para empresas e desenvolvedores. Os recursos incluem inferência criptografada TrustML e modelos de código aberto.
Prodia transforma a infraestrutura de IA complexa em fluxos de trabalho prontos para produção — rápidos, escaláveis e amigáveis para desenvolvedores.

Runpod é uma plataforma de nuvem de IA completa que simplifica a construção e a implantação de modelos de IA. Treine, ajuste e implemente IA sem esforço com computação poderosa e escalonamento automático.

Simplifique a implementação de IA com Synexa. Execute modelos de IA poderosos instantaneamente com apenas uma linha de código. Plataforma de API de IA sem servidor rápida, estável e amigável para desenvolvedores.
Modal: Plataforma sem servidor para equipes de IA e dados. Execute computação intensiva de CPU, GPU e dados em escala com seu próprio código.