DataChain
Visão geral de DataChain
O que é DataChain?
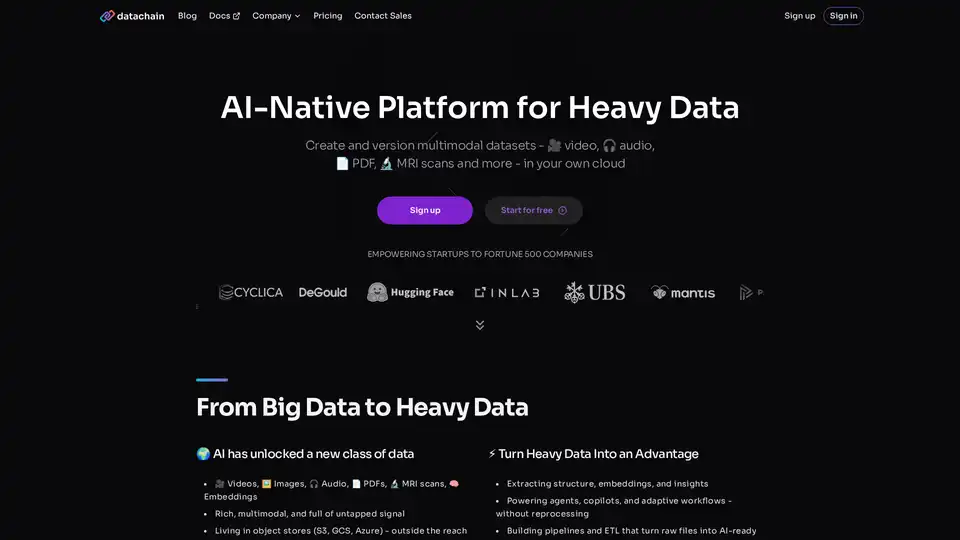
DataChain é uma plataforma nativa de IA projetada para lidar com as complexidades de dados pesados na era do aprendizado de máquina avançado e inteligência artificial. Ela se destaca ao fornecer um registro centralizado para conjuntos de dados multimodais, incluindo vídeos, arquivos de áudio, PDFs, imagens, exames de MRI e até embeddings. Diferente de ferramentas tradicionais baseadas em SQL que lutam com dados não estruturados ou em grande escala armazenados em stores de objetos como S3, GCS ou Azure, DataChain preenche a lacuna entre fluxos de trabalho amigáveis a desenvolvedores e processamento em escala empresarial. Essa plataforma capacita startups até empresas Fortune 500 a curar, enriquecer e versionar seus conjuntos de dados de forma eficiente, transformando entradas multimodais brutas em conhecimento acionável de IA.
Em seu núcleo, DataChain aborda a transição do big data para o que chama de 'heavy data'—formatos ricos e não estruturados cheios de potencial inexplorado para aplicações de IA. Seja você construindo agentes, copilotos ou fluxos de trabalho adaptativos, DataChain garante que seu pipeline de dados não exija reprocessamento constante, economizando tempo e recursos enquanto desbloqueia insights mais profundos.
Como o DataChain Funciona?
DataChain opera com uma filosofia centrada no desenvolvedor, combinando a simplicidade do Python com a escalabilidade de operações semelhantes a SQL. Aqui está uma análise de seus mecanismos principais:
Registro Centralizado de Conjuntos de Dados: Todos os conjuntos de dados são rastreados com linhagem completa, metadados e versionamento. Você pode acessá-los de forma contínua por meio de uma interface de usuário (UI), interfaces de chat, ambientes de desenvolvimento integrados (IDEs) ou até agentes de IA via Protocolo de Controle de Modelo (MCP). Esse registro atua como uma fonte única de verdade, facilitando a gestão de dependências e a reprodução de resultados.
Simplicidade do Python Encontra Escala SQL: Desenvolvedores escrevem em uma linguagem familiar—Python—tanto para código quanto para operações de dados. Isso elimina os silos criados por ferramentas SQL separadas, melhorando a integração com IDEs e agentes de IA. Por exemplo, você pode consultar e manipular dados pesados sem alternar contextos, otimizando seu fluxo de trabalho.
Desenvolvimento Local e Escala na Nuvem: Comece a construir e testar pipelines de dados em seu IDE local para iterações rápidas. Uma vez pronto, escale sem esforço para centenas de GPUs na nuvem sem reescrita de código. Essa abordagem híbrida maximiza a produtividade sem comprometer o desempenho para tarefas em grande escala.
Cópia Zero de Dados e Lock-in: Seus arquivos originais—vídeos, imagens, áudio—permanecem em seu armazenamento nativo como S3. DataChain simplesmente referencia e rastreia versões, evitando duplicações desnecessárias ou lock-in de fornecedores. Isso não só reduz custos, mas também garante soberania de dados e flexibilidade.
A plataforma aproveita modelos de linguagem grandes (LLMs) e modelos de aprendizado de máquina para extrair estrutura, embeddings e insights de fontes não estruturadas. Por exemplo, ela pode aplicar modelos a vídeos ou PDFs durante processos ETL (Extract, Transform, Load), organizando o caos em formatos prontos para IA.
Recursos Principais do DataChain
A suíte de ferramentas do DataChain cobre todas as etapas do manuseio de dados para projetos de IA. Recursos principais incluem:
Domínio de Dados Multimodais: Lide com formatos diversos como vídeo (🎥), áudio (🎧), PDFs (📄), imagens (🖼️) e exames médicos (🔬 MRI) em um só lugar. Extraia insights usando LLMs para processar conteúdo não estruturado com facilidade.
Pipelines ETL Sem Emendas: Construa fluxos de trabalho automatizados para transformar arquivos brutos em conjuntos de dados enriquecidos. Filtre, junte e atualize dados em escala, alimentando desde o rastreamento de experimentos até o versionamento de modelos.
Linhagem de Dados e Reprodutibilidade: Rastreie toda dependência entre código, dados e modelos. Reproduza conjuntos de dados sob demanda e automatize atualizações, o que é crucial para pesquisa em ML reprodutível e conformidade.
Processamento em Grande Escala: Gerencie milhões ou bilhões de arquivos sem gargalos. Calcule atualizações eficientemente e aproveite ML para filtragem avançada, tornando-o ideal para cenários de dados pesados.
Integração e Acessibilidade: Suporta UI, chat, IDEs e agentes. Elementos open-source via repositório GitHub permitem customização, enquanto o Studio baseado na nuvem fornece um ambiente pronto para uso.
Esses recursos são respaldados por parcerias confiáveis com líderes da indústria global, garantindo confiabilidade para implantações de IA de alto risco.
Como Usar o DataChain
Começar com DataChain é direto e gratuito para iniciar:
Cadastre-se: Crie uma conta no site do DataChain para acessar a plataforma. Sem custos iniciais—comece a explorar imediatamente.
Configure Seu Ambiente: Conecte seu armazenamento de objetos (ex.: S3) e importe conjuntos de dados. Use a UI intuitiva ou o SDK Python para começar a curar dados.
Construa Pipelines: Desenvolva em seu IDE local usando Python. Aplique modelos de ML para enriquecimento, depois implante na nuvem para escalar.
Versões e Rastreie: Registre conjuntos de dados com metadados e linhagem. Use MCP para interações com agentes ou consulte via linguagem natural.
Monitore e Itere: Aproveite o registro para reproduzir resultados, atualize conjuntos de dados via ETL e analise insights para seus modelos de IA.
Documentação, um guia de início rápido e suporte da comunidade Discord tornam o onboarding suave. Para necessidades empresariais, contate vendas para preços e recursos adaptados à sua escala.
Por Que Escolher DataChain?
Em um cenário onde a IA demanda conjuntos de dados cada vez maiores e mais complexos, DataChain oferece uma vantagem competitiva ao tornar os dados pesados acessíveis e gerenciáveis. Ferramentas tradicionais falham em formatos não estruturados, levando a silos e ineficiências. DataChain elimina esses pontos de dor com sua abordagem de cópia zero, reduzindo custos de armazenamento em até 100% em alguns casos, e seu design centrado no desenvolvedor acelera o tempo para insights.
Equipes que usam DataChain relatam rastreamento de experimentos mais rápido, versionamento de modelos sem emendas e automação robusta de pipelines. É particularmente valioso para evitar reprocessamento no desenvolvimento iterativo de IA, onde mudanças em dados ou modelos podem caso contrário cascatear em horas de retrabalho. Além disso, sem lock-in, você mantém o controle sobre sua infraestrutura.
Comparado a alternativas, o foco do DataChain em dados pesados multimodais o diferencia—não é apenas outra ferramenta de gerenciamento de dados; é construído para a próxima onda de IA, de modelos generativos a agentes em tempo real.
Para Quem é o DataChain?
DataChain é ideal para uma ampla gama de usuários no ecossistema de IA:
Desenvolvedores e Cientistas de Dados: Aqueles que constroem pipelines de ML e precisam de ferramentas nativas de Python para dados multimodais sem obstáculos SQL.
Equipes de IA/ML em Startups e Empresas: De inovadores em estágio inicial a empresas Fortune 500 lidando com análise de vídeo, transcrição de áudio ou imagens médicas.
Pesquisadores e Analistas: Qualquer um que exija conjuntos de dados reprodutíveis com linhagem completa para experimentos em visão computacional, NLP ou IA multimodal.
Construtores de Produtos: Criando copilotos, agentes ou sistemas adaptativos que dependem de bases de conhecimento enriquecidas e versionadas.
Se você está lidando com dados não estruturados em armazenamento de objetos e quer aproveitá-los para IA sem o overhead, DataChain é sua solução principal.
Valor Prático e Casos de Uso
DataChain entrega valor tangível ao transformar dados pesados em um ativo estratégico. Considere essas aplicações do mundo real:
Mídia e Entretenimento: Processe bibliotecas de vídeo e áudio para extrair embeddings para motores de recomendação ou moderação de conteúdo.
Saúde: Versione exames de MRI e PDFs para diagnósticos impulsionados por IA, garantindo conformidade com rastreamento de linhagem de dados.
E-Commerce: Enriqueça imagens e descrições de produtos usando LLMs para construir busca personalizada e recursos de provador virtual.
Laboratórios de Pesquisa: Automatize ETL para conjuntos de dados em grande escala no aprendizado multimodal, acelerando ciclos de treinamento de modelos.
Usuários elogiam sua escalabilidade—lidando com bilhões de arquivos sem esforço—e o aumento de produtividade da integração com IDE. Embora detalhes de preços estejam disponíveis sob contato, o nível gratuito baixa barreiras para experimentação.
Em resumo, DataChain redefine a gerenciamento de dados para IA em escala. Ao curar, enriquecer e versionar conjuntos de dados multimodais com fricção mínima, ele capacita equipes eficientes a liderar na revolução dos dados pesados. Pronto para transformar seus dados em uma vantagem de IA? Cadastre-se hoje e explore seu GitHub para contribuições open-source.
Melhores ferramentas alternativas para "DataChain"
Dataloop é uma pilha de dados pronta para IA que oferece gerenciamento de dados, pipelines de automação e uma plataforma de rotulagem de dados. Ele acelera projetos de IA, agilizando os fluxos de trabalho de dados e integrando o feedback humano.
Tafi Avatar, parte da Daz 3D, fornece conjuntos de dados de personagens e ambientes 3D normalizados e gerados processualmente para treinamento de IA. Oferece geração de personagens paramétricos em escala, anatomia humana realista e flexibilidade de pipeline.

Nomic Atlas é uma plataforma de dados nativa de IA que operacionaliza grandes conjuntos de dados não estruturados para aplicações de IA, análise de dados e fluxos de trabalho. Oferece ferramentas para exploração de dados, colaboração e integração.
micro1 é uma plataforma de IA que aproveita a inteligência humana para criar conjuntos de dados de alta qualidade para IA avançada. Possui um motor de dados, um recrutador de IA Zara e um laboratório de pesquisa focado em recrutamento assistido por IA.

Roboto é um motor de análise projetado para robótica e IA física, permitindo que as equipes pesquisem, transformem e analisem eficientemente dados multimodais de robôs em escala, identifiquem anomalias e automatizem a análise.
Maxim AI é uma plataforma completa de avaliação e observabilidade que ajuda as equipes a implantar agentes de IA de forma confiável e 5 vezes mais rápido com ferramentas abrangentes de teste, monitoramento e garantia de qualidade.

Plataforma de IA ultrarrápida para desenvolvedores. Implante, ajuste e execute mais de 200 LLMs e modelos multimodais otimizados com APIs simples - SiliconFlow.
Hive oferece modelos de IA de ponta para entender, pesquisar e gerar conteúdo. Ideal para moderação, proteção de marca e tarefas generativas com integração API.
Qwen Image é um gerador de imagens avançado de 20B parâmetros com capacidades inovadoras de renderização de texto, suportando geração de texto complexo em chinês e inglês, edição precisa de imagens e criação multimodal.
FiftyOne é a principal plataforma de dados de visão computacional e IA visual de código aberto, confiável pelas principais empresas para maximizar o desempenho da IA com melhores dados. Curadoria de dados, anotação mais inteligente, avaliação de modelos.
Syntonym capacita a visão de máquina, fornecendo anonimização sem perdas, protegendo dados pessoais e mantendo a utilidade dos dados para modelos de IA. Garanta a privacidade e a conformidade com soluções de anonimização em tempo real.
Innovatiana oferece rotulagem de dados especializada e cria conjuntos de dados de IA de alta qualidade para ML, DL, LLM, VLM, RAG e RLHF, garantindo soluções de IA éticas e impactantes.
Ocular AI é uma plataforma de data lakehouse multimodal que permite ingerir, selecionar, pesquisar, anotar e treinar modelos de IA personalizados em dados não estruturados. Construído para a era da IA multimodal.
Your Personal AI é especializada em soluções de IA e aprendizado de máquina personalizadas para empresas. Desde a coleta de dados até o desenvolvimento de modelos de IA, capacite sua empresa com ferramentas inovadoras. Serviços de alta qualidade e em conformidade com o GDPR.