Deep Infra
Visão geral de Deep Infra
O que é Deep Infra?
Deep Infra é uma plataforma poderosa especializada em inferência de IA para modelos de machine learning, oferecendo acesso de baixo custo, rápido, simples e confiável a mais de 100 modelos de deep learning prontos para produção. Seja executando modelos de linguagem grandes (LLMs) como DeepSeek-V3.2 ou ferramentas especializadas de OCR, as APIs amigáveis para desenvolvedores da Deep Infra facilitam a integração de IA de alto desempenho em suas aplicações sem o incômodo de gerenciar infraestrutura. Construída sobre hardware de ponta otimizado para inferência em data centers seguros baseados nos EUA, ela suporta escalabilidade para trilhões de tokens, priorizando eficiência de custos, privacidade e desempenho.
Ideal para startups e empresas, Deep Infra elimina contratos de longo prazo e taxas ocultas com sua precificação pay-as-you-go, garantindo que você pague apenas pelo que usa. Com certificações SOC 2 e ISO 27001, mais uma política rigorosa de retenção zero, seus dados permanecem privados e seguros.
Principais Recursos do Deep Infra
Deep Infra se destaca no saturado cenário de infraestrutura de machine learning com essas capacidades principais:
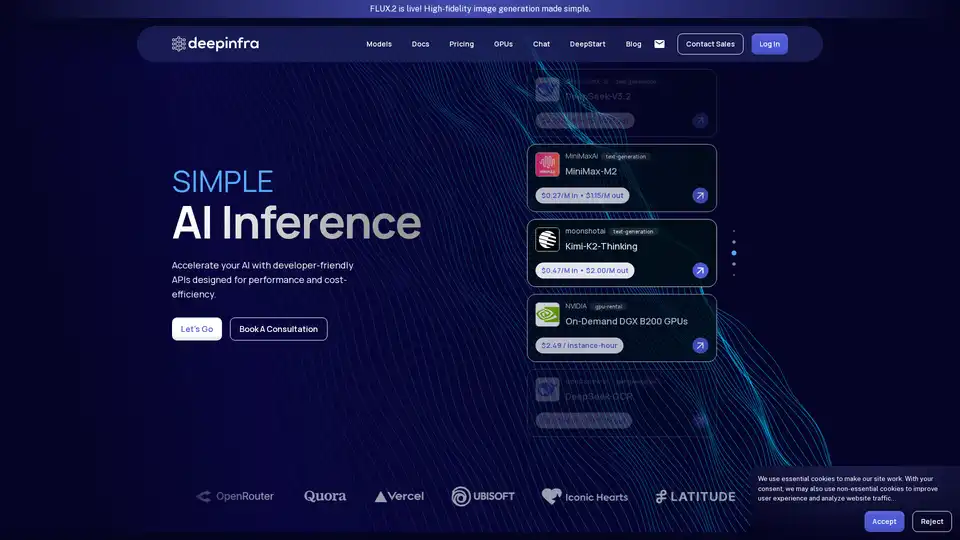
Vasta Biblioteca de Modelos: Acesse mais de 100 modelos em categorias como geração de texto, reconhecimento automático de fala, texto para fala e OCR. Modelos em destaque incluem:
- DeepSeek-V3.2: LLM eficiente com atenção esparsa para raciocínio em contexto longo.
- MiniMax-M2: Modelo compacto de 10B parâmetros para tarefas de codificação e agenticas.
- Série Qwen3: Modelos escaláveis para modos de seguimento de instruções e pensamento.
- Especialistas em OCR como DeepSeek-OCR, olmOCR-2-7B e PaddleOCR-VL para análise de documentos.
Precificação Econômica: Taxas ultrabaixas, ex.: $0.03/M de entrada para DeepSeek-OCR, $0.049/M para gpt-oss-120b. Precificação em cache reduz ainda mais os custos para consultas repetidas.
Desempenho Escalável: Lida com trilhões de tokens com métricas como 0ms tempo-para-primeiro-token (em demos ao vivo) e computação exaFLOPS. Suporta até 256k de comprimento de contexto.
Aluguel de GPUs: GPUs NVIDIA DGX B200 sob demanda a $2.49/hora de instância para cargas de trabalho personalizadas.
Segurança & Conformidade: Retenção zero de entrada/saída, SOC 2 Type II, certificado ISO 27001.
Personalização: Inferência sob medida para prioridades de latência, throughput ou escala, com suporte prático.
| Exemplo de Modelo | Tipo | Precificação (entrada/saída por 1M tokens) | Comprimento de Contexto |
|---|---|---|---|
| DeepSeek-V3.2 | text-generation | $0.27 / $0.40 | 160k |
| gpt-oss-120b | text-generation | $0.049 / $0.20 | 128k |
| DeepSeek-OCR | text-generation | $0.03 / $0.10 | 8k |
| DGX B200 GPUs | gpu-rental | $2.49/hora | N/A |
Como o Deep Infra Funciona?
Começar com Deep Infra é direto:
Cadastre-se e Acesse a API: Crie uma conta gratuita, obtenha sua chave API e integre via endpoints RESTful simples—sem configuração complexa necessária.
Selecione Modelos: Escolha do catálogo (ex.: via dashboard ou docs) suportando provedores como DeepSeek-AI, OpenAI, Qwen e MoonshotAI.
Execute Inferência: Envie prompts via chamadas de API. Modelos como DeepSeek-V3.1-Terminus suportam modos de raciocínio configuráveis (pensando/não-pensando) e uso de ferramentas para fluxos de trabalho agenticos.
Escala & Monitore: Métricas ao vivo rastreiam tokens/seg, TTFT, RPS e gastos. Hospede seus próprios modelos em seus servidores para privacidade.
Otimize: Aproveite otimizações como quantização FP4/FP8, atenção esparsa (ex.: DSA no DeepSeek-V3.2) e arquiteturas MoE para eficiência.
A infraestrutura proprietária da plataforma garante baixa latência e alta confiabilidade, superando provedores de nuvem genéricos em inferência de deep learning.
Casos de Uso e Valor Prático
Deep Infra se destaca em aplicações reais de IA:
Desenvolvedores & Startups: Prototipagem rápida de chatbots, agentes de código ou geradores de conteúdo usando LLMs acessíveis.
Empresas: Implantações em escala de produção para OCR em processamento de documentos (ex.: PDFs com tabelas/gráficos via PaddleOCR-VL), análise financeira ou agentes personalizados.
Pesquisadores: Experimente com modelos de fronteira como Kimi-K2-Thinking (desempenho medalha de ouro IMO) sem custos de hardware.
Fluxos de Trabalho Agenticos: Modelos como DeepSeek-V3.1 suportam chamadas de ferramentas, síntese de código e raciocínio em contexto longo para sistemas autônomos.
Usuários relatam economia de custos 10x vs. concorrentes, com escalabilidade perfeita—ideal para lidar com picos de carga em apps SaaS ou processamento em lote.
Para Quem é o Deep Infra?
Engenheiros de IA/ML: Precisando de hospedagem de modelos confiável e APIs.
Equipes de Produto: Construindo recursos de IA sem sobrecarga de infraestrutura.
Inovadores Conscientes de Custos: Startups otimizando taxa de queima em tarefas de alto cómputo.
Orgs Focadas em Conformidade: Lidando com dados sensíveis com garantias de retenção zero.
Por Que Escolher Deep Infra em Vez de Alternativas?
Diferente de hyperscalers com mínimos altos ou dores de auto-hospedagem, Deep Infra combina facilidade nível OpenAI com custos 50-80% menores. Sem lock-in de fornecedor, acessibilidade global e atualizações ativas de modelos (ex.: FLUX.2 para imagens). Respaldado por métricas reais e sucesso de usuários em benchmarks de codificação (LiveCodeBench), raciocínio (GPQA) e uso de ferramentas (Tau2).
Pronto para acelerar? Agende uma consulta ou mergulhe nos docs para infraestrutura de IA escalável hoje. Deep Infra impulsiona a próxima onda de IA eficiente e de grau de produção.
Tags Relacionadas a Deep Infra
