Firecrawl
Visão geral de Firecrawl
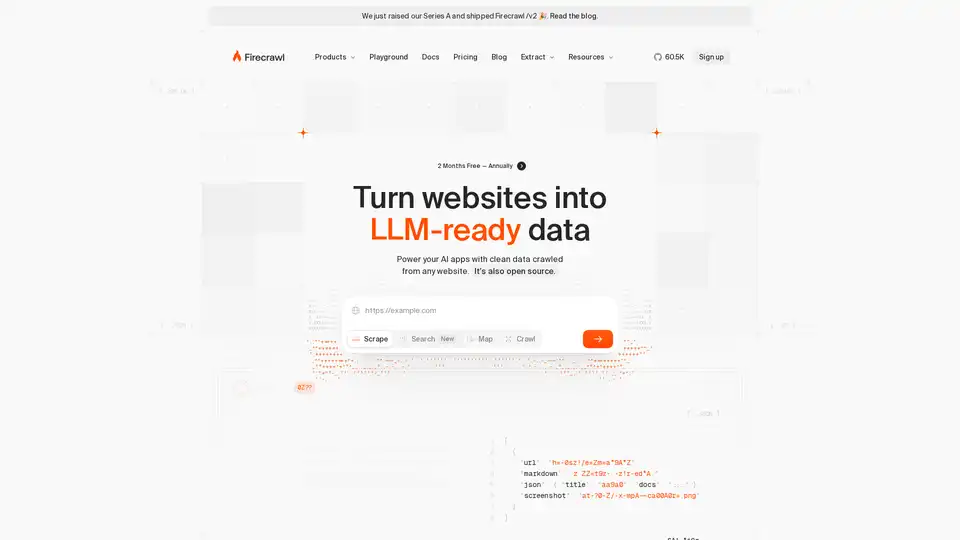
O que é o Firecrawl?
O Firecrawl se destaca como uma API revolucionária de dados web desenvolvida especificamente para desenvolvedores e construtores de IA. Em um mundo onde agentes de IA e grandes modelos de linguagem (LLMs) buscam dados frescos e estruturados da vasta internet, o Firecrawl simplifica o processo de crawling web, scraping e busca. Lançado com o apoio da Y Combinator e confiado por mais de 5.000 empresas, esta ferramenta transforma sites brutos em saídas limpas, formatadas em markdown, estruturadas em JSON ou até prontas para capturas de tela, que são imediatamente utilizáveis para raciocínio de IA e aplicações. Seja aprimorando chats de IA com contexto web em tempo real ou enriquecendo dados de leads para equipes de vendas, o Firecrawl elimina as dores de cabeça tradicionais do scraping web, como gerenciamento de proxies ou problemas de renderização JavaScript.
Em seu núcleo, o Firecrawl é tanto uma biblioteca open-source quanto um serviço de API hospedado, tornando-o acessível para desenvolvedores solo até projetos em escala empresarial. Seu recente financiamento Série A e o lançamento da versão 2 destacam seu rápido crescimento e compromisso com a inovação em pipelines de dados de IA.
Como o Firecrawl funciona?
O Firecrawl opera com base em um conjunto de princípios fundamentais projetados para superar os scrapers convencionais. Diferente de ferramentas como Puppeteer ou cURL que lutam com sites modernos e dinâmicos, o Firecrawl cobre 96% da web — incluindo páginas com muito JavaScript e conteúdo protegido — sem depender de proxies ou navegadores headless. Essa abordagem de "sem dores de cabeça com proxies" garante confiabilidade e velocidade, entregando resultados em menos de 1 segundo para a maioria das requisições, ideal para agentes de IA em tempo real.
O fluxo de trabalho é direto:
- Insira uma URL ou consulta: Comece com uma única URL para scraping, um domínio de site para crawling ou uma consulta de busca para exploração web ampla.
- Processamento inteligente: O Firecrawl usa mecanismos de espera inteligente para carregar conteúdo dinâmico, lida com análise de mídia para arquivos PDF e DOCX, e emprega modo stealth para imitar o comportamento de usuários reais, evitando bloqueios e CAPTCHAs.
- Saída de dados estruturados: Receba formatos prontos para LLM como markdown limpo (livre de anúncios e bagunça de navegação), JSON com metadados extraídos ou capturas de tela. Para crawling, mapeia sites inteiros, respeitando robots.txt enquanto extrai dados de todas as páginas acessíveis.
- Facilidade de integração: Com SDKs para Python, Node.js e até comandos curl, a integração é amigável para desenvolvedores. Por exemplo, um simples script Python pode raspar um site como firecrawl.dev em segundos.
Essa eficiência vem de sua arquitetura desde o início, que prioriza velocidade e limpeza. Benchmarks mostram que o Firecrawl completa tarefas em 49-52 ms, superando amplamente os concorrentes, tornando-o perfeito para apps dinâmicos que precisam de insights web instantâneos.
Principais características do Firecrawl
O Firecrawl oferece um conjunto de recursos que o tornam a escolha principal para extração de dados de IA:
- Scrape: Extraia o conteúdo completo de qualquer URL em múltiplos formatos. Obtenha markdown despojado de boilerplate, esquemas JSON para dados estruturados (ex.: títulos, docs) e até capturas de tela para verificação visual.
- Crawl: Descubra e raspe automaticamente todas as páginas de um site web, construindo um índice abrangente sem mapas de site manuais. Seu cache seletivo permite controlar o armazenamento e a frescura.
- Search (Novo): Realize buscas web e recupere conteúdo completo e contextual dos resultados, impulsionando buscas semânticas ou bases de conhecimento.
- Map: Visualize estruturas de sites para melhor navegação em crawls grandes.
- Actions para scraping interativo: Simule interações de usuário como cliques, rolagem, digitação ou espera — crucial para aplicações single-page (SPAs).
- Análise de mídia e documentos: Lide com PDFs, DOCX e outros arquivos hospedados na web, produzindo texto analisado pronto para processamento de IA.
- Zero configuração: Não precisa gerenciar proxies rotativos, limites de taxa ou orquestração — o Firecrawl cuida de tudo nos bastidores.
- Transparência open-source: A biblioteca principal está publicamente disponível no GitHub com 60.5K estrelas, permitindo contribuições da comunidade e ajustes personalizados.
Esses recursos garantem a limpeza de dados: o Firecrawl remove inteligentemente o ruído, impõe scraping ético respeitando robots.txt e escala para projetos grandes sem falhar em casos de borda como autenticação ou CAPTCHAs (embora configurações avançadas possam exigir tratamento personalizado).
Principais casos de uso para o Firecrawl
O Firecrawl brilha em cenários onde a IA precisa de dados web de alta qualidade. Veja como está transformando indústrias:
- Chats de IA mais inteligentes com contexto: Integre dados web em tempo real em chatbots ou assistentes. Por exemplo, alimente uma IA como Claude ou Cursor com infos atualizadas, garantindo respostas precisas e atuais. Desenvolvedores relatam performance 50x mais rápida comparada a alternativas como Apify.
- Enriquecimento de leads e inteligência de vendas: Raspe diretórios para enriquecer dados de CRM com infos de contato, estágios de financiamento e detalhes de tomadores de decisão. Equipes de vendas o usam para "conhecer seus leads" extraindo insights estruturados de sites de empresas.
- Pesquisa profunda e extração de conhecimento: Para pesquisa acadêmica ou de mercado, crawl sites para papers, notícias, opiniões de especialistas e dados industriais. Construa ferramentas de busca personalizadas que entregam insights abrangentes sem falhas.
- Plataformas de IA e construção de agentes: Permita que usuários criem apps com dados web via integrações como Mendable.ai ou editores de código (Claude Code, Cursor, Windsurf). É ideal para plataformas onde clientes constroem workflows de IA.
- SEO e otimização de conteúdo: Extraia dados web para análise de palavras-chave ou pesquisa de concorrentes, alimentando ferramentas de SEO impulsionadas por IA.
Exemplos do mundo real incluem startups usando Firecrawl para rastrear rodadas de financiamento ou sites de e-commerce raspando infos de produtos para inteligência de preços.
Por que escolher o Firecrawl sobre outros scrapers?
Em um mercado lotado, o Firecrawl se diferencia por performance e facilidade. Scrapers tradicionais frequentemente falham em páginas renderizadas com JS ou exigem setups complexos, mas a cobertura de 96% do Firecrawl e velocidades sub-segundo o tornam confiável para pipelines de IA. É compatível com SOC 2 Type 2 para segurança, oferece tiers gratuitos sem cartão de crédito necessário, e escala perfeitamente — créditos para scraping e crawling são custo-efetivos, com opções pay-per-use.
Testemunhos de usuários destacam seu impacto: Morgan Linton o chama de "surpreendente" para codificação de IA, enquanto Alex Reibman trocou do Apify por ganhos de velocidade 50x. Chris DeWeese deseja ter descoberto mais cedo, e a comunidade elogia seu desenvolvimento responsivo, como adicionar suporte TypeScript em menos de uma hora.
O preço começa grátis (2 meses em planos anuais), com planos escalando por créditos — scraping custa mínimo por requisição, e falhas não são cobradas. Sem rollover, mas cobrança mensal flexível via métodos padrão.
Para quem é o Firecrawl?
O Firecrawl é direcionado a construtores de IA, desenvolvedores e cientistas de dados que precisam de dados web sem complicações. É perfeito para:
- Desenvolvedores solo e startups: Integração rápida via SDKs para protótipos.
- Engenheiros de IA/ML: Alimentando LLMs com datasets limpos para treinamento ou inferência.
- Equipes de produto: Construindo features como ferramentas de pesquisa ou apps de lead gen.
- Empresas: Crawling em grande escala com compliance e confiabilidade.
Se você está cansado de scrapers frágeis, o ethos open-source do Firecrawl e seus benchmarks comprovados o tornam a melhor maneira de aproveitar dados web para inovação em IA.
Primeiros passos com o Firecrawl
Cadastre-se grátis em firecrawl.dev — sem cartão de crédito necessário. Pegue sua chave API do dashboard, instale o SDK (ex.: pip install firecrawl-py) e execute um scrape simples:
from firecrawl import Firecrawl
app = Firecrawl(api_key="fc-YOUR_API_KEY")
result = app.scrape_url('https://example.com')
print(result['markdown'])
Explore a documentação para features avançadas como padrões de cache ou chains de ações. Junte-se à comunidade Discord ou GitHub para suporte, e confira o blog para atualizações como o lançamento v2.
Em resumo, o Firecrawl não é só um scraper — é a ponte que entrega a internet para a IA, permitindo aplicações mais inteligentes e rápidas com esforço mínimo. Seja para pesquisa, enriquecimento ou workflows agenticos, é a ferramenta que torna os dados web acessíveis e acionáveis.
Melhores ferramentas alternativas para "Firecrawl"
MrScraper é um raspador da web alimentado por IA que extrai dados de sites facilmente e sem ser bloqueado. Simplifica a raspagem de dados e a automação, tornando os dados acessíveis a todos.
Kadoa é uma ferramenta de web scraping baseada em IA que automatiza a extração de dados em escala sem código. Ele oferece recursos como monitoramento em tempo real, raspagem de agentes de IA e segurança de nível empresarial.
Agenty® é um software de web scraping sem código que automatiza a coleta de dados, o monitoramento de mudanças e a automação do navegador. Extraia informações valiosas de sites com IA, aprimorando a pesquisa e obtendo insights.

A Kong.ai fornece chatbots conversacionais com tecnologia de IA e agentes de IA para automatizar o suporte ao cliente, vendas, RH e fluxos de trabalho de marketing, ajudando as empresas a escalar como as empresas da Fortune 500.
ZeroWork é uma ferramenta RPA sem código amigável ao usuário que automatiza raspagem web, geração de leads e tarefas de redes sociais com recursos de IA integrados. Evite bots, enriqueça dados e escale operações sem esforço para economizar horas diárias.
BulkGPT é uma ferramenta sem código para automação de fluxos de trabalho IA em massa, permitindo raspagem web rápida e processamento em lotes de ChatGPT para criar conteúdo SEO, descrições de produtos e materiais de marketing sem esforço.
UseScraper é uma API de web scraping e crawling hiper-rápida. Raspe qualquer URL instantaneamente, rastreie sites inteiros e exporte dados em texto simples, HTML ou Markdown. As primeiras 1.000 páginas são gratuitas.
Scrapingdog é uma API de web scraping que gerencia proxies e navegadores headless, permitindo a extração de dados sem esforço.
Transforme qualquer site em dados limpos e estruturados com Skrape.ai. Nossa API baseada em IA extrai dados em seu formato preferido para treinamento de IA.
WebScraping.AI é uma API de scraping com tecnologia de IA que lida com proxies, navegadores e análise HTML para facilitar o web scraping.
Scout é um kit de ferramentas para escalar agentes e fluxos de trabalho habilitados para IA em todas as organizações. Crie, lance e dimensione soluções de IA mais rapidamente.
Scrap.so é uma ferramenta de coleta de dados com tecnologia de IA que navega em sites, coleta dados e os envia para onde você precisar. Ideal para geração de leads, pesquisa de mercado e análise da concorrência.
Chat Data é uma ferramenta de criação de chatbot de IA para sites, Discord, Slack, Shopify, WordPress e muito mais. Treine uma vez, implemente em todos os lugares. Personalize, conecte e compartilhe.
Experimente o futuro do web scraping com Webtap.ai. Utilize nossa IA de dados para soluções de scraping eficientes e ilimitadas.