Deep Infra
Overview of Deep Infra
What is Deep Infra?
Deep Infra is a powerful platform specializing in AI inference for machine learning models, delivering low-cost, fast, simple, and reliable access to over 100 production-ready deep learning models. Whether you're running large language models (LLMs) like DeepSeek-V3.2 or specialized OCR tools, Deep Infra's developer-friendly APIs make it easy to integrate high-performance AI into your applications without the hassle of managing infrastructure. Built on cutting-edge, inference-optimized hardware in secure US-based data centers, it supports scaling to trillions of tokens while prioritizing cost-efficiency, privacy, and performance.
Ideal for startups and enterprises alike, Deep Infra eliminates long-term contracts and hidden fees with its pay-as-you-go pricing, ensuring you only pay for what you use. With SOC 2 and ISO 27001 certifications, plus a strict zero-retention policy, your data stays private and secure.
Key Features of Deep Infra
Deep Infra stands out in the crowded machine learning infrastructure landscape with these core capabilities:
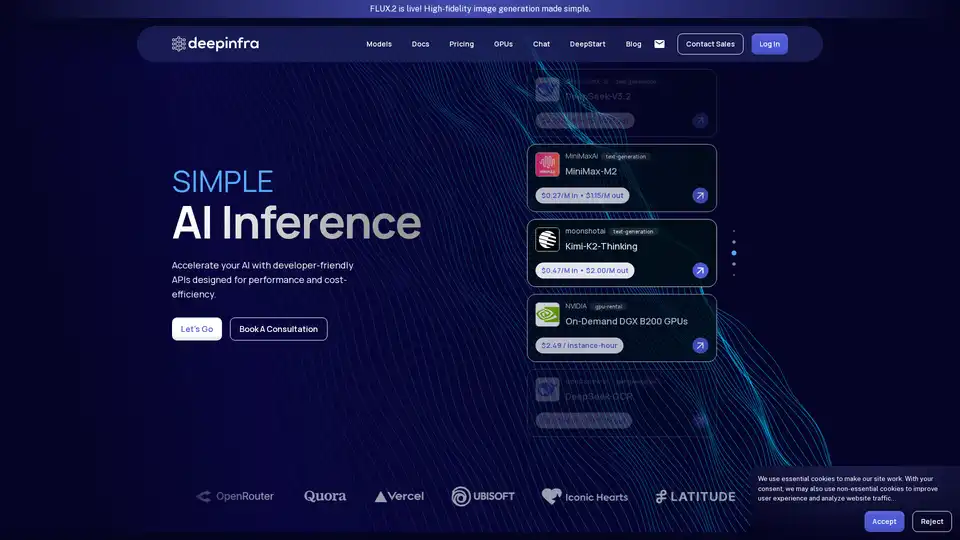
Vast Model Library: Access 100+ models across categories like text-generation, automatic-speech-recognition, text-to-speech, and OCR. Featured models include:
- DeepSeek-V3.2: Efficient LLM with sparse attention for long-context reasoning.
- MiniMax-M2: Compact 10B parameter model for coding and agentic tasks.
- Qwen3 series: Scalable models for instruction-following and thinking modes.
- OCR specialists like DeepSeek-OCR, olmOCR-2-7B, and PaddleOCR-VL for document parsing.
Cost-Effective Pricing: Ultra-low rates, e.g., $0.03/M input for DeepSeek-OCR, $0.049/M for gpt-oss-120b. Cached pricing further reduces costs for repeated queries.
Scalable Performance: Handles trillions of tokens with metrics like 0ms time-to-first-token (in live demos) and exaFLOPS compute. Supports up to 256k context lengths.
GPU Rentals: On-demand NVIDIA DGX B200 GPUs at $2.49/instance-hour for custom workloads.
Security & Compliance: Zero input/output retention, SOC 2 Type II, ISO 27001 certified.
Customization: Tailored inference for latency, throughput, or scale priorities, with hands-on support.
| Model Example | Type | Pricing (in/out per 1M tokens) | Context Length |
|---|---|---|---|
| DeepSeek-V3.2 | text-generation | $0.27 / $0.40 | 160k |
| gpt-oss-120b | text-generation | $0.049 / $0.20 | 128k |
| DeepSeek-OCR | text-generation | $0.03 / $0.10 | 8k |
| DGX B200 GPUs | gpu-rental | $2.49/hour | N/A |
How Does Deep Infra Work?
Getting started with Deep Infra is straightforward:
Sign Up and API Access: Create a free account, get your API key, and integrate via simple RESTful endpoints—no complex setup required.
Select Models: Choose from the catalog (e.g., via dashboard or docs) supporting providers like DeepSeek-AI, OpenAI, Qwen, and MoonshotAI.
Run Inference: Send prompts via API calls. Models like DeepSeek-V3.1-Terminus support configurable reasoning modes (thinking/non-thinking) and tool-use for agentic workflows.
Scale & Monitor: Live metrics track tokens/sec, TTFT, RPS, and spend. Host your own models on their servers for privacy.
Optimize: Leverage optimizations like FP4/FP8 quantization, sparse attention (e.g., DSA in DeepSeek-V3.2), and MoE architectures for efficiency.
The platform's proprietary infrastructure ensures low latency and high reliability, outperforming generic cloud providers for deep learning inference.
Use Cases and Practical Value
Deep Infra excels in real-world AI applications:
Developers & Startups: Rapid prototyping of chatbots, code agents, or content generators using affordable LLMs.
Enterprises: Production-scale deployments for OCR in document processing (e.g., PDFs with tables/charts via PaddleOCR-VL), financial analysis, or custom agents.
Researchers: Experiment with frontier models like Kimi-K2-Thinking (gold-medal IMO performance) without hardware costs.
Agentic Workflows: Models like DeepSeek-V3.1 support tool-calling, code synthesis, and long-context reasoning for autonomous systems.
Users report 10x cost savings vs. competitors, with seamless scaling—perfect for handling peak loads in SaaS apps or batch processing.
Who is Deep Infra For?
AI/ML Engineers: Needing reliable model hosting and APIs.
Product Teams: Building AI features without infra overhead.
Cost-Conscious Innovators: Startups optimizing burn rate on high-compute tasks.
Compliance-Focused Orgs: Handling sensitive data with zero-retention guarantees.
Why Choose Deep Infra Over Alternatives?
Unlike hyperscalers with high minimums or self-hosting pains, Deep Infra combines OpenAI-level ease with 50-80% lower costs. No vendor lock-in, global accessibility, and active model updates (e.g., FLUX.2 for images). Backed by real metrics and user success in coding benches (LiveCodeBench), reasoning (GPQA), and tool-use (Tau2).
Ready to accelerate? Book a consultation or dive into docs for scalable AI infrastructure today. Deep Infra powers the next wave of efficient, production-grade AI.
Tags Related to Deep Infra
