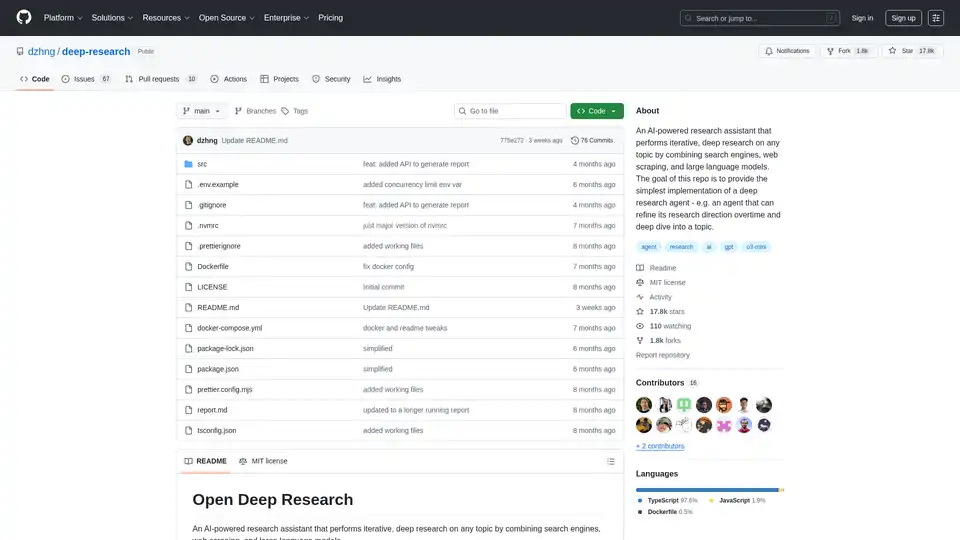
Deep Research
Overview of Deep Research
Deep Research: An AI-Powered Research Assistant
What is Deep Research? Deep Research is an open-source AI-powered research assistant designed to perform iterative, deep research on any topic. It combines the power of search engines, web scraping, and large language models (LLMs) to provide users with a comprehensive understanding of their chosen subject matter.
This project aims to offer the simplest implementation of a deep research agent, allowing it to refine its research direction over time and delve deeply into a topic. The goal is to maintain a compact codebase, making it easy to understand and build upon.
How does Deep Research work?
Deep Research leverages several key components to deliver its research capabilities:
- Search Engines: Utilizes search engines to gather initial information and identify relevant sources.
- Web Scraping: Extracts content from web pages to gather detailed information and data.
- Large Language Models (LLMs): Employs LLMs to generate targeted search queries, process results, and identify new research directions.
Key Features of Deep Research
- Iterative Research: Conducts in-depth research by iteratively generating search queries, processing results, and diving deeper based on findings.
- Intelligent Query Generation: Uses LLMs to generate targeted search queries based on research goals and previous findings.
- Depth & Breadth Control: Offers configurable parameters to control the scope (breadth) and depth of the research.
- Smart Follow-up: Generates follow-up questions to refine research needs and uncover new insights.
- Comprehensive Reports: Produces detailed markdown reports with findings and sources, providing a clear and organized overview of the research.
- Concurrent Processing: Handles multiple searches and result processing in parallel for efficiency, reducing research time.
How to use Deep Research?
To get started with Deep Research, follow these steps:
- Requirements
- Node.js environment
- API keys for:
- Firecrawl API (for web search and content extraction)
- OpenAI API (for o3 mini model)
- Setup
- Clone the repository:
git clone [repository_url] - Install dependencies:
npm install - Set up environment variables in a
.env.localfile:FIRECRAWL_KEY="your_firecrawl_key" # If you want to use your self-hosted Firecrawl, add the following below: # FIRECRAWL_BASE_URL="http://localhost:3002" OPENAI_KEY="your_openai_key" - To use local LLM, comment out
OPENAI_KEYand instead uncommentOPENAI_ENDPOINTandOPENAI_MODEL:- Set
OPENAI_ENDPOINTto the address of your local server (e.g., "http://localhost:1234/v1") - Set
OPENAI_MODELto the name of the model loaded in your local server.
- Set
- Clone the repository:
- Usage
- Run the research assistant:
npm start - You'll be prompted to:
- Enter your research query
- Specify research breadth (recommended: 3-10, default: 4)
- Specify research depth (recommended: 1-5, default: 2)
- Answer follow-up questions to refine the research direction
- The system will then:
- Generate and execute search queries
- Process and analyze search results
- Recursively explore deeper based on findings
- Generate a comprehensive markdown report
- The final report will be saved as
report.mdoranswer.mdin your working directory, depending on the selected modes.
- Run the research assistant:
Concurrency
If you have a paid version of Firecrawl or a local version, increase the ConcurrencyLimit by setting the CONCURRENCY_LIMIT environment variable to improve speed. Free users may encounter rate limit errors and should reduce the limit to 1.
DeepSeek R1
Deep Research performs well with the R1 model. To use R1, set a Fireworks API key:
FIREWORKS_KEY="api_key"
The system will automatically switch to R1 instead of o3-mini when the key is detected.
Custom Endpoints and Models
You can also tweak the endpoint (for other OpenAI compatible APIs like OpenRouter or Gemini) as well as the model string using these environment variables:
OPENAI_ENDPOINT="custom_endpoint"
CUSTOM_MODEL="custom_model"
Who is Deep Research For?
Deep Research is suitable for:
- Researchers who need to gather in-depth information on a specific topic.
- Students who need to conduct research for academic projects.
- Professionals who need to stay up-to-date on industry trends and developments.
- Anyone who wants to quickly and efficiently explore a topic in detail.
Why Choose Deep Research?
- Simplifies Complex Research: Automates the process of gathering and analyzing information, saving time and effort.
- Uncovers Hidden Insights: Explores a topic in depth, uncovering insights that might be missed with traditional research methods.
- Provides Comprehensive Reports: Generates detailed reports that summarize findings and provide a clear overview of the research.
- Customizable and Flexible: Offers configurable parameters to tailor the research process to specific needs.
License
Deep Research is released under the MIT License, allowing users to freely use and modify the code as needed.
Deep Research streamlines in-depth topic analysis. By automating search, web scraping, and leveraging LLMs for intelligent query generation, it simplifies complex research processes. Researchers, students, and professionals can use this tool to quickly gather comprehensive information, uncover insights, and generate detailed reports, all while maintaining a clear, readable format. What sets Deep Research apart is its ability to iteratively refine its research direction, diving deeper into a topic with each iteration.
Best Alternative Tools to "Deep Research"
InfraNodus is an AI text analysis tool that leverages knowledge graphs to visualize texts, uncover content gaps, and generate new insights for research, ideation, and SEO optimization.
Simplescraper simplifies web scraping, turning websites into APIs. Extract data with a free Chrome extension or cloud platform. Automate data extraction and integration effortlessly.
Automate web scraping, WordPress data migration, eCommerce product imports, and booking automation with Firecrawl. Use AI-powered solutions to save time, reduce errors, and scale your business effortlessly!
Simplescraper is a web scraping tool that simplifies data extraction. It offers a Chrome extension and cloud platform to turn websites into structured data and LLM-ready content, accessible via a no-code dashboard or API.
Apify is a full-stack cloud platform for web scraping, browser automation, and AI agents. Use pre-built tools or build your own Actors for data extraction and workflow automation.
Hunch is an AI-first workspace that empowers teams to use top AI models, manage complex projects, and boost productivity. Features include templates, batch processing, web scraping, and code execution.
Gentables is an AI agent that transforms unstructured data into organized tables. Generate tables from prompts or files, extract tables from documents/images, automate workflows, search tables, and generate insights effortlessly.
BestProxy offers unlimited residential proxies with high-quality residential IPs and no data limits, ideal for high-volume data scraping, AI training data collection, and privacy protection.
Summer AI is an AI-powered audio tour guide app for discovering nearby stories, points of interest, and local events. Available on the iOS App Store.

Olostep is a web data API for AI and research agents. It allows you to extract structured web data from any website in real-time and automate your web research workflows. Use cases include data for AI, spreadsheet enrichment, lead generation, and more.
Firecrawl is the leading web crawling, scraping, and search API designed for AI applications. It turns websites into clean, structured, LLM-ready data at scale, powering AI agents with reliable web extraction without proxies or headaches.
WebScraping.AI is an AI-powered scraping API that handles proxies, browsers, and HTML parsing for easy web scraping.
BrowserAct is an AI-powered web scraper and automation tool that allows you to extract data from any site without coding. Automate workflows and integrate with tools like n8n and Make.
Scrapingdog offers a web scraping API & dedicated APIs for extracting search, social, and e-commerce data. It manages complexities, providing blockage-free data with real browser rendering and rotating proxies.