
Baseten 概述
什么是 Baseten?
Baseten 是一个旨在简化 AI 模型在生产环境中部署和扩展的平台。它提供了将 AI 产品快速推向市场所需的基础设施、工具和专业知识。
Baseten 如何工作?
Baseten 的平台围绕 Baseten Inference Stack 构建,其中包括前沿的性能研究、云原生基础设施以及为推理而设计的开发者体验。
以下是主要组件的细分:
- 模型 API: 快速测试新的工作负载、原型产品,并评估具有生产级性能的最新模型。
- 在 Baseten 上训练: 使用推理优化的基础设施训练模型,没有限制或开销。
- 应用性能研究: 利用自定义内核、解码技术和高级缓存来优化模型性能。
- 云原生基础设施: 跨任何区域和云(Baseten Cloud 或您自己的)扩展工作负载,具有快速的冷启动和高正常运行时间。
- 开发者体验 (DevEx): 通过生产就绪的开发者体验来部署、优化和管理模型以及复合 AI 解决方案。
主要特性和优势
- 专用部署: 专为高规模工作负载而设计,允许您在为生产构建的基础设施上提供开源、自定义和微调的 AI 模型。
- 多云容量管理: 在 Baseten Cloud 上运行工作负载、自托管或按需灵活调整。该平台与任何云提供商兼容。
- 自定义模型部署: 部署任何具有开箱即用性能优化的自定义或专有模型。
- 支持 Gen AI: 针对 Gen AI 应用量身定制的自定义性能优化。
- 模型库: 轻松浏览和部署预构建的模型。
具体应用
Baseten 适用于各种 AI 应用,包括:
- 图像生成: 提供自定义模型或 ComfyUI 工作流程,针对您的用例进行微调,或在几分钟内部署任何开源模型。
- 转录: 利用定制的 Whisper 模型进行快速、准确且经济高效的转录。
- 文本转语音: 支持实时音频流,用于低延迟 AI 电话呼叫、语音代理、翻译等。
- 大型语言模型 (LLMs): 通过专用部署,为 DeepSeek、Llama 和 Qwen 等模型实现更高的吞吐量和更低的延迟。
- 嵌入: 提供 Baseten 嵌入推理 (BEI),与其他解决方案相比,具有更高的吞吐量和更低的延迟。
- 复合 AI: 为复合 AI 实现精细的硬件和自动缩放,从而提高 GPU 使用率并降低延迟。
为什么选择 Baseten?
以下是 Baseten 脱颖而出的几个原因:
- 性能: 优化的基础设施,可实现快速的推理时间。
- 可扩展性: 在 Baseten 的云或您自己的云中无缝扩展。
- 开发者体验: 专为生产环境设计的工具和工作流程。
- 灵活性: 支持各种模型,包括开源、自定义和微调的模型。
- 成本效益: 优化资源利用率以降低成本。
Baseten 适合哪些人?
Baseten 非常适合:
- 机器学习工程师: 简化模型部署和管理。
- AI 产品团队: 加速 AI 产品上市时间。
- 公司: 寻求可扩展且可靠的 AI 基础设施。
客户评价
- Nathan Sobo,联合创始人:Baseten 为用户和公司提供了最佳体验。
- Sahaj Garg,联合创始人兼 CTO:通过 Baseten 的团队获得了对推理管道的很大控制权,并优化了每个步骤。
- Lily Clifford,联合创始人兼 CEO:Rime 最先进的延迟和正常运行时间是由与 Baseten 共同关注基础知识所驱动的。
- Isaiah Granet,CEO 兼联合创始人:实现了惊人的收入数字,而无需担心 GPU 和扩展。
- Waseem Alshikh,Writer 的 CTO 兼联合创始人:为定制构建的 LLM 实现了经济高效、高性能的模型服务,而无需增加内部工程团队的负担。
Baseten 提供了一个全面的解决方案,用于在生产环境中部署和扩展 AI 模型,提供高性能、灵活性和用户友好的开发者体验。无论您是使用图像生成、转录、LLM 还是自定义模型,Baseten 旨在简化整个过程。
"Baseten"的最佳替代工具

Cloudflare Workers AI 允许您在 Cloudflare 全球网络的预训练机器学习模型上运行无服务器 AI 推理任务,提供各种模型并与其他 Cloudflare 服务无缝集成。
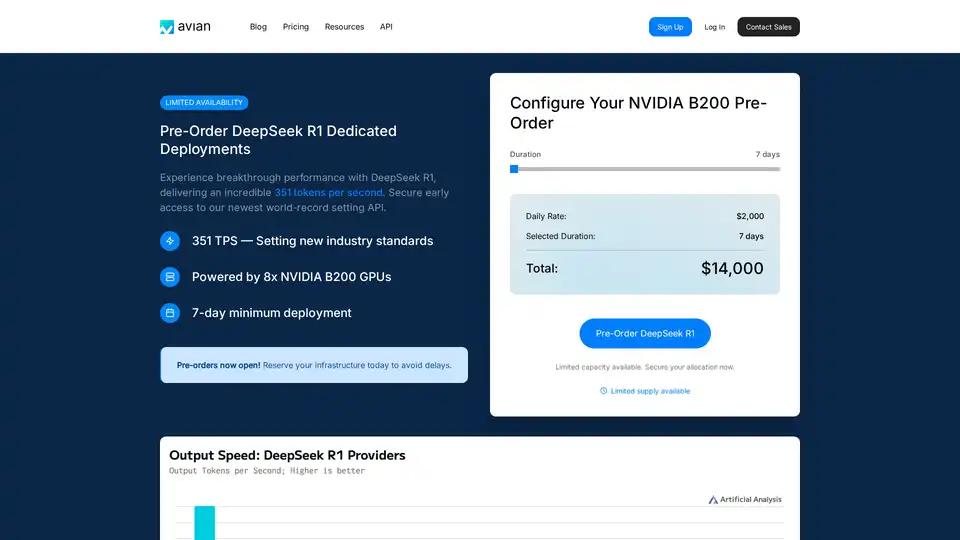
Avian API为开源LLM提供最快的AI推理,在DeepSeek R1上实现351 TPS。使用兼容OpenAI的API以3-10倍的速度部署任何HuggingFace LLM。企业级性能和隐私。
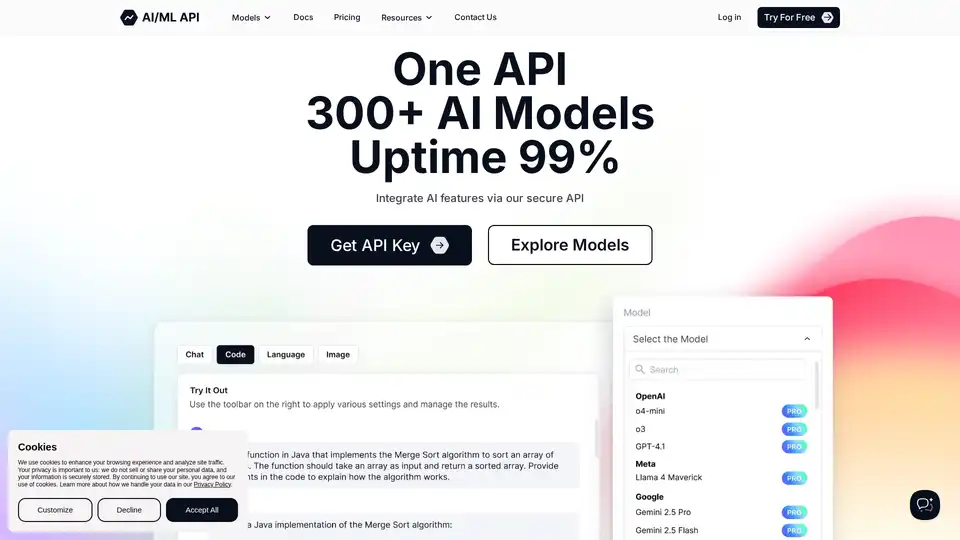
AIMLAPI 通过单一、低延迟的API提供对300+ AI模型的访问。与OpenAI相比,节省高达80%的成本,为机器学习提供快速、经济高效的AI解决方案。
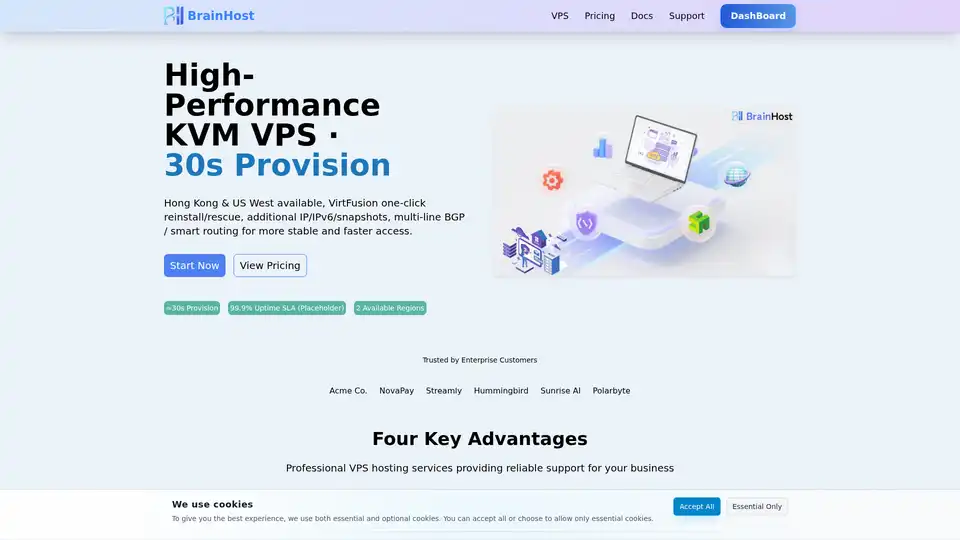
BrainHost VPS 提供高性能 KVM 虚拟服务器,配备 NVMe 存储,适用于 AI 推理、网站和电商。香港和美西 30 秒快速部署,确保可靠的全球访问。

探索 NVIDIA NIM API,优化领先 AI 模型的推理和部署。使用无服务器 API 构建企业级生成式 AI 应用,或在您的 GPU 基础设施上进行自托管。


GPUX是一个无服务器GPU推理平台,可为StableDiffusionXL、ESRGAN和AlpacaLLM等AI模型实现1秒冷启动,具有优化的性能和P2P功能。

Inferless提供快速的无服务器GPU推理,用于部署ML模型。它具有自动扩展、动态批处理和企業级安全等功能,可实现可扩展、轻松的自定义机器学习模型部署。



无需设置任何服务器,即可立即运行HuggingFace中的任何Llama模型。提供超过11,900种模型。起价为每月10美元,无限制访问。
Batteries Included是一个自托管的AI平台,简化了LLM、向量数据库和Jupyter Notebook的部署。在您的基础设施上构建世界一流的AI应用。