llmarena.ai 概述
什么是 llmarena.ai?
llmarena.ai 是一个强大的在线平台,旨在简化比较来自各种 AI 提供商的大型语言模型 (LLMs) 的过程。原名 countless.dev,它已演变为一个更智能、更高效的工具,用于路由和优化 AI 使用,同时控制成本。无论您是开发者、研究人员还是商业专业人士,llmarena.ai 将来自顶级提供商如 OpenAI、Anthropic、Google、xAI、DeepSeek、Qwen 等模型整合到一个中央枢纽中。这使得基于关键指标如定价、上下文窗口、输出能力以及模态来评估选项变得前所未有地简单,帮助用户做出明智决策,而无需浏览散乱的文档。
在其核心,llmarena.ai 解决了快速扩展的 AI 景观中的一个常见痛点:选择正确 LLM 的复杂性。随着 AI 模型快速发展,提供商经常更新功能和定价,使得比较成为一项耗时任务。这个工具通过提供模型性能的实时洞察来简化这一过程,确保您为特定需求选择最具成本效益和合适的选项,无论是编程任务、内容生成还是数据分析。
llmarena.ai 如何工作?
该平台作为一个直观的基于 Web 的比较器运行,直接从提供商拉取数据以显示最新信息。用户可以访问几个关键部分,包括 Pricing Calculator、Versus Comparison 工具,以及分类的模型探索,如 Programming、Roleplay、Marketing、Technology、Science、Translation、Legal、Finance、Health、Trivia、Academia、Multimodal 和 Long Context 模型。
以下是其主要功能的分解:
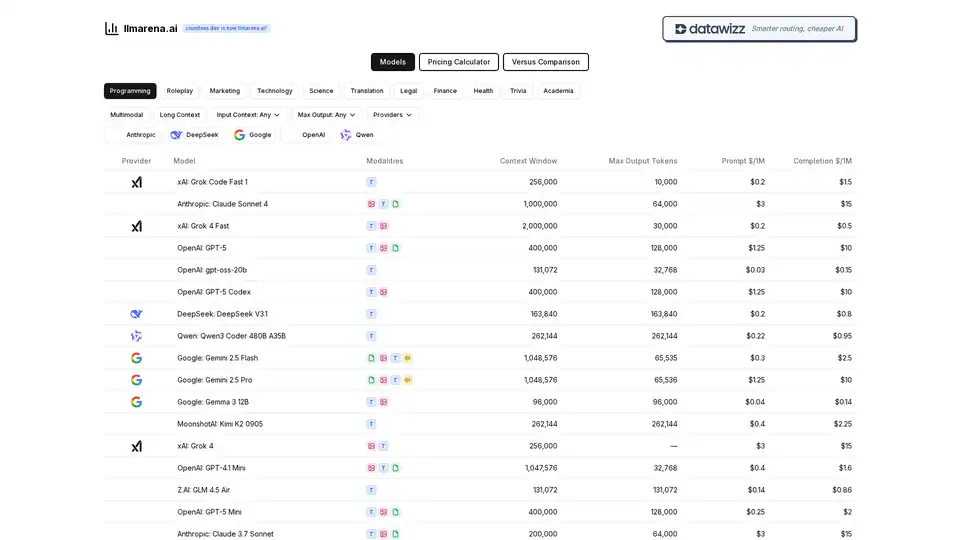
- Model Listings and Specifications:主表格按提供商分类模型,并突出基本规格。例如,它显示模态(主要是 Text,或 'T')、上下文窗口(例如,xAI 的 Grok 4 Fast 最多 2,000,000 个 token)、最大输出 token 以及提示和补全的每百万 token 定价。这允许快速扫描能力——如 Anthropic 的 Claude Sonnet 4 提供 1,000,000 个 token 的巨大上下文窗口,定价为 $3/$15 每百万 token。
- Pricing Calculator:一个交互式工具,用户输入使用场景(例如,输入/输出 token 量)来估计跨模型的成本。这对于预算规划非常宝贵,特别是比较像 Google 的 Gemma 3 12B ($0.04/$0.14) 这样的预算友好选项与像 Anthropic 的 Claude Opus 4.1 ($15/$75) 这样的高级选项时。
- Versus Comparison:两个或更多模型的并排评估,重点关注如输入上下文灵活性 (Any) 和最大输出限制等功能。它非常适合一对一对决,例如将 OpenAI 的 GPT-5 (400,000 上下文,$1.25/$10) 与 Google 的 Gemini 2.5 Pro (1,048,576 上下文,$1.25/$10) 进行比较。
- Categorized Use Cases:模型被标记为特定领域,帮助用户过滤相关应用。例如,在 Programming 下,您可能探索 xAI 的 Grok Code Fast 1 或 OpenAI 的 GPT-5 Codex,两者均针对代码生成优化,并具有竞争力定价。
该平台强调 'smarter routing'——基于您的任务建议最佳模型——同时通过透明的成本分解优先考虑 'cheaper AI'。所有数据以干净的表格格式呈现,便于阅读,无需手动计算。
关键功能和模型亮点
llmarena.ai 以其对领先 LLMs 的全面覆盖脱颖而出。以下是一些特色模型的快照:
| 提供商 | 模型 | 上下文窗口 | 最大输出 Tokens | 提示 $/1M | 补全 $/1M |
|---|---|---|---|---|---|
| xAI | Grok Code Fast 1 | 256,000 | 10,000 | $0.2 | $1.5 |
| Anthropic | Claude Sonnet 4 | 1,000,000 | 64,000 | $3 | $15 |
| OpenAI | GPT-5 | 400,000 | 128,000 | $1.25 | $10 |
| Gemini 2.5 Flash | 1,048,576 | 65,535 | $0.3 | $2.5 | |
| DeepSeek | DeepSeek V3.1 | 163,840 | 163,840 | $0.2 | $0.8 |
| Qwen | Qwen3 Coder 480B A35B | 262,144 | 262,144 | $0.22 | $0.95 |
这些示例说明了多样性:预算模型如 OpenAI 的 gpt-oss-20b ($0.03/$0.15) 用于轻量级任务,或高容量模型如 xAI 的 Grok 4 Fast 用于广泛上下文。像多模态支持(尽管这里主要关注文本)和长上下文处理这样的功能满足高级用例,例如在法律或学术环境中处理大型文档。
该工具还支持灵活输入 (Any) 和输出,使其适用于从快速 Trivia 查询到深入科学分析的一切。
使用场景和实际价值
llmarena.ai 在模型选择影响效率和费用的场景中大放异彩:
- 开发者与程序员:使用 Programming 类别比较代码专注模型如 Qwen3 Coder Plus 或 OpenAI 的 GPT-5 Codex。快速计算迭代编码会话的成本,节省 API 调用。
- 内容创作者与营销人员:对于 Marketing 或 Roleplay 任务,评估像 Claude 3.7 Sonnet 这样的模型用于创意写作,确保高质量输出而不超支。
- 研究人员与学者:在 Science 或 Academia 部分,选择长上下文模型用于分析论文或数据集,像 Gemini 2.5 Pro 这样的工具处理百万 token 输入。
- 商业应用:Finance、Legal 和 Health 类别帮助专业人士选择合规、成本效益高的模型——例如,GLM 4.5 Air 用于多语言操作中的经济翻译。
- 一般 AI 实验:Trivia 或 Multimodal 过滤器允许休闲用户测试多样能力,从有趣提示到复杂多模态集成。
其实际价值在于其节省时间的聚合:无需访问多个提供商站点(OpenAI、Anthropic、Google 等),一切都在一处。用户可以通过发现替代品避免供应商锁定——例如,从昂贵的 Claude Opus 切换到性能相似的更便宜 DeepSeek V3.1。对于团队,定价计算器有助于预测 API 预算,通过优化选择可能将成本降低 50% 或更多。
llmarena.ai 适合谁?
这个工具适合:
- AI 爱好者与业余爱好者:那些在预算内实验 LLMs 的人。
- 软件工程师:需要可靠的编码助手而无高费用。
- 数据科学家:比较机器学习管道的模型。
- 企业用户:在金融或法律领域需要精确、可扩展的 AI。
- 教育者和学生:探索学术专注模型用于研究。
它不适合寻求完整模型训练平台的人,但完美适合部署和选择阶段。
为什么选择 llmarena.ai?
在一个拥挤的 AI 市场中,llmarena.ai 以其对透明度和可用性的关注脱颖而出。基本比较无需注册,界面响应迅速,便于快速移动检查。定期更新确保规格反映最新发布,如 MoonshotAI 或 Z.AI 的新兴模型。通过赋能更智能的路由,它不仅降低成本,还提升生产力——用户报告项目启动更快和资源分配更好。
要获得最佳结果,从 Pricing Calculator 开始您的 workload,然后使用 Versus 进行微调。无论您是优化速度、成本还是上下文长度,llmarena.ai 将 LLM 复杂性转化为清晰度,使高级 AI 对所有人 доступен。
"llmarena.ai"的最佳替代工具
Dialoq AI 是一个统一的 API 平台,使开发人员可以轻松访问和运行 200 多个 AI 模型,从而减少开发时间和成本。 它提供缓存、负载平衡和自动回退等功能,以实现可靠的 AI 应用开发。
Pecan AI是一个预测分析平台,使企业能够使用对话式AI轻松构建和部署预测模型,而无需编码或机器学习专业知识。它可以帮助预测需求、客户流失等。
Think AI Agency 通过 AI 自动化将想法转化为 MVP。快速 MVP 开发、定制 LLM、Web 和移动应用程序开发以及专业的 AI 解决方案。
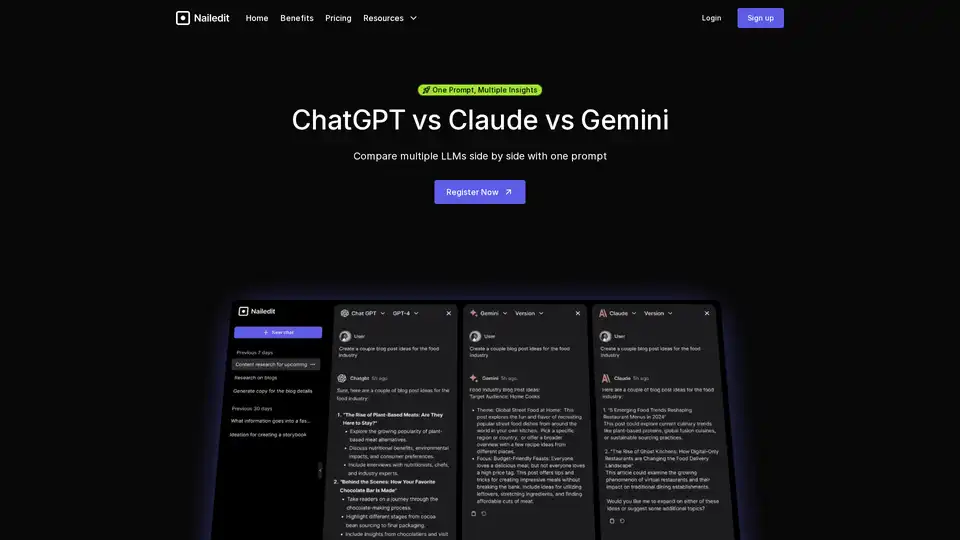
NailedIt 允许您即时比较来自 ChatGPT、Claude 和 Gemini 的响应。通过一个提示简化您的工作流程,并从多个 AI 模型中找到最佳见解。
CrawlQ 以革命性的 ROCC 测量领先内容 ERP 市场。受到财富 500 强信赖,实现 425% 内容资本回报。行业领先平台,将内容转化为增值资产。
Nightwatch是一款AI驱动的SEO监控工具,提供精确的排名追踪、网站审计和报告功能。追踪关键词,监控搜索可见性,并优化您的网站以获得更高的排名。
Infrabase.ai 是一个发现 AI 基础设施工具和服务的目录。查找向量数据库、Prompt 工程工具、推理 API 等,以构建世界一流的 AI 产品。
AiPrice提供了一个用于计算OpenAI token定价的API。准确预估各种LLM模型的prompt token数量。提供免费计划,无需信用卡。
使用AI模型定价比较ChatGPT、Claude、Gemini及更多AI模型的价格。计算成本,找到最适合您需求的经济高效的AI解决方案。
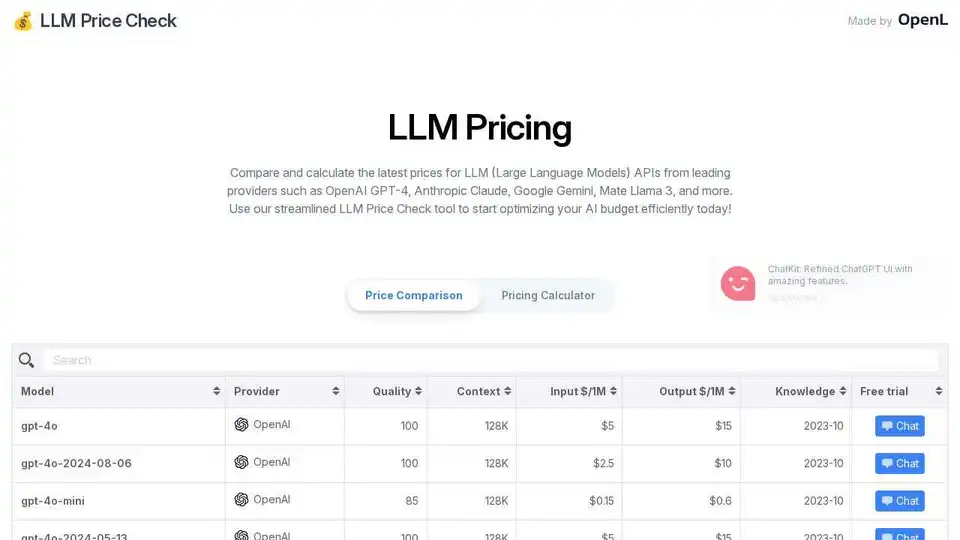
比较来自OpenAI、Anthropic、Google等的LLM API价格。使用LLM Price Check的简化定价计算器优化您的AI预算。
Cabina.AI提供对GPT-4、Claude、LLama等的访问,全部集中在一处。免费开始聊天PDF,分析文件,转录音频,生成视频和图像!