DataChain
Übersicht von DataChain
Was ist DataChain?
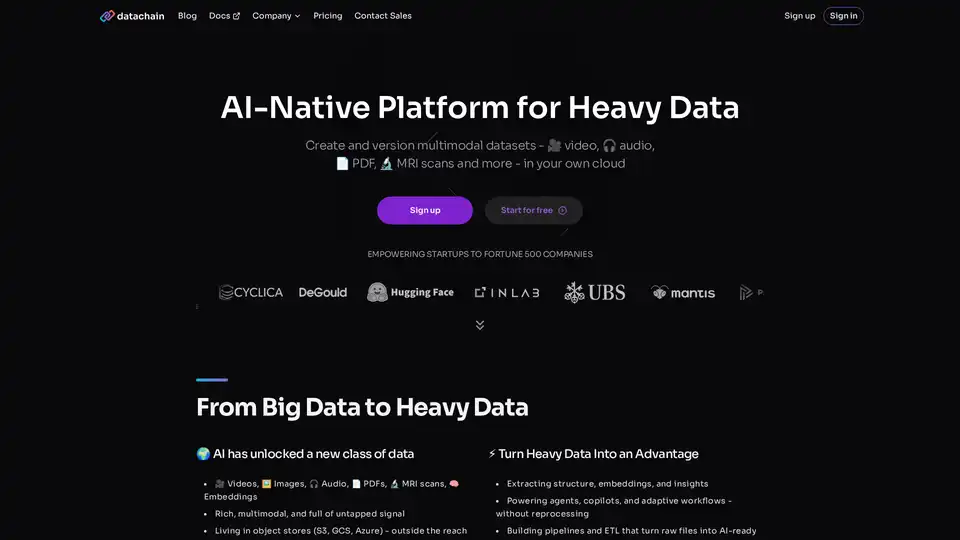
DataChain ist eine KI-native Plattform, die für den Umgang mit den Komplexitäten von Heavy Data im Zeitalter des fortgeschrittenen maschinellen Lernens und der künstlichen Intelligenz entwickelt wurde. Sie zeichnet sich durch eine zentralisierte Registry für multimodale Datensätze aus, einschließlich Videos, Audiodateien, PDFs, Bildern, MRT-Scans und sogar Embeddings. Im Gegensatz zu traditionellen SQL-basierten Tools, die mit unstrukturierten oder großvolumigen Daten in Object Stores wie S3, GCS oder Azure kämpfen, überbrückt DataChain die Lücke zwischen entwicklerfreundlichen Workflows und Unternehmens-scale-Verarbeitung. Diese Plattform befähigt Startups bis hin zu Fortune-500-Unternehmen, ihre Datensätze effizient zu kuratieren, anzureichern und zu versionieren, um rohe, multimodale Eingaben in verwertbares KI-Wissen zu verwandeln.
Im Kern adressiert DataChain den Wandel von Big Data zu dem, was es als „Heavy Data“ bezeichnet – reichhaltige, unstrukturierte Formate, die voller ungenutzten Potenzials für KI-Anwendungen stecken. Egal, ob Sie Agents, Copilots oder adaptive Workflows entwickeln, DataChain stellt sicher, dass Ihre Datenpipeline keine ständige Neuverarbeitung erfordert, spart Zeit und Ressourcen und erschließt gleichzeitig tiefere Einblicke.
Wie funktioniert DataChain?
DataChain operiert nach einer Developer-First-Philosophie und vereint die Einfachheit von Python mit der Skalierbarkeit von SQL-ähnlichen Operationen. Hier eine Aufschlüsselung der Schlüsselmechanismen:
Zentralisierte Dataset-Registry: Alle Datensätze werden mit vollständiger Lineage, Metadaten und Versionierung nachverfolgt. Sie können sie nahtlos über eine Benutzeroberfläche (UI), Chat-Oberflächen, integrierte Entwicklungsumgebungen (IDEs) oder sogar KI-Agents via Model Control Protocol (MCP) zugreifen. Diese Registry dient als Single Source of Truth, was das Management von Abhängigkeiten und die Reproduzierbarkeit von Ergebnissen erleichtert.
Python-Einfachheit trifft auf SQL-Skala: Entwickler schreiben in einer vertrauten Sprache – Python – für sowohl Code- als auch Datenoperationen. Dies beseitigt die Silos, die durch separate SQL-Tools entstehen, und verbessert die Integration mit IDEs und KI-Agents. Beispielsweise können Sie Heavy Data abfragen und manipulieren, ohne den Kontext wechseln zu müssen, und so Ihren Workflow optimieren.
Lokale Entwicklung und Cloud-Skalierung: Beginnen Sie mit dem Aufbau und Testen von Datenpipelines in Ihrer lokalen IDE für schnelle Iteration. Wenn bereit, skaliere mühelos auf Hunderte von GPUs in der Cloud ohne Code-Anpassungen. Dieser hybride Ansatz maximiert die Produktivität, ohne die Leistung bei großvolumigen Tasks zu beeinträchtigen.
Zero Data Copy und Lock-In: Ihre Originaldateien – Videos, Bilder, Audio – verbleiben in ihrem nativen Storage wie S3. DataChain referenziert und tracked lediglich Versionen, vermeidet unnötige Duplizierung oder Vendor-Lock-in. Dies reduziert nicht nur Kosten, sondern gewährleistet auch Data Sovereignty und Flexibilität.
Die Plattform nutzt Large Language Models (LLMs) und Machine-Learning-Modelle, um Struktur, Embeddings und Insights aus unstrukturierten Quellen zu extrahieren. Beispielsweise kann sie Modelle auf Videos oder PDFs während ETL (Extract, Transform, Load)-Prozessen anwenden und Chaos in KI-ready Formate organisieren.
Kernfeatures von DataChain
DataChain's Suite von Tools deckt jede Phase der Datenverwaltung für KI-Projekte ab. Wichtige Features umfassen:
Multimodale Datenbeherrschung: Verwalten Sie diverse Formate wie Video (🎥), Audio (🎧), PDFs (📄), Bilder (🖼️) und medizinische Scans (🔬 MRT) an einem Ort. Extrahieren Sie Insights mit LLMs, um unstrukturierte Inhalte mühelos zu verarbeiten.
Nahtlose ETL-Pipelines: Bauen Sie automatisierte Workflows, um Rohdateien in angereicherte Datensätze zu verwandeln. Filtern, joinen und aktualisieren Sie Daten im großen Maßstab, alles antreibend von Experiment-Tracking bis Model-Versioning.
Data Lineage und Reproduzierbarkeit: Verfolgen Sie jede Abhängigkeit zwischen Code, Daten und Modellen. Reproduzieren Sie Datensätze on-demand und automatisieren Sie Updates, was für reproduzierbare ML-Forschung und Compliance entscheidend ist.
Großvolumige Verarbeitung: Verwalten Sie Millionen oder Milliarden von Dateien ohne Engpässe. Berechnen Sie Updates effizient und nutzen Sie ML für erweiterte Filterung, ideal für Heavy-Data-Szenarien.
Integration und Zugänglichkeit: Unterstützt UI, Chat, IDEs und Agents. Open-Source-Elemente via GitHub-Repository ermöglichen Customization, während cloudbasiertes Studio eine ready-to-use Umgebung bietet.
Diese Features werden durch vertrauenswürdige Partnerschaften mit globalen Branchenführern untermauert, was Zuverlässigkeit für hochriskante KI-Implementierungen sicherstellt.
Wie verwendet man DataChain?
Der Einstieg in DataChain ist unkompliziert und zunächst kostenlos:
Registrieren: Erstellen Sie ein Konto auf der DataChain-Website, um auf die Plattform zuzugreifen. Keine Vorabkosten – beginnen Sie sofort mit der Erkundung.
Einrichten Ihrer Umgebung: Verbinden Sie Ihren Object Storage (z.B. S3) und importieren Sie Datensätze. Nutzen Sie die intuitive UI oder Python SDK, um mit der Datenkuratierung zu beginnen.
Pipelines aufbauen: Entwickeln Sie in Ihrer lokalen IDE mit Python. Wenden Sie ML-Modelle zur Anreicherung an, dann deployen Sie in die Cloud zur Skalierung.
Versionieren und Tracken: Registrieren Sie Datensätze mit Metadaten und Lineage. Nutzen Sie MCP für Agent-Interaktionen oder Abfragen via natürlicher Sprache.
Überwachen und Iterieren: Nutzen Sie die Registry, um Ergebnisse zu reproduzieren, Datensätze via ETL zu aktualisieren und Insights für Ihre KI-Modelle zu analysieren.
Dokumentation, ein Quick-Start-Guide und Discord-Community-Support machen das Onboarding reibungslos. Für Enterprise-Bedürfnisse, kontaktieren Sie Sales für Preise und Features, die auf Ihre Skala zugeschnitten sind.
Warum DataChain wählen?
In einer Landschaft, in der KI immer größere, komplexere Datensätze verlangt, verschafft DataChain einen Wettbewerbsvorteil, indem es Heavy Data zugänglich und handhabbar macht. Traditionelle Tools versagen bei unstrukturierten Formaten, was zu Silos und Ineffizienzen führt. DataChain beseitigt diese Pain Points mit seinem Zero-Copy-Ansatz, der Speicherkosten in einigen Fällen um bis zu 100% reduziert, und sein entwicklerzentriertes Design beschleunigt Time-to-Insight.
Teams, die DataChain nutzen, berichten von schnellerem Experiment-Tracking, nahtlosem Model-Versioning und robuster Pipeline-Automatisierung. Es ist besonders wertvoll, um Neuverarbeitung in iterativer KI-Entwicklung zu vermeiden, wo Änderungen in Daten oder Modellen sonst zu Stunden von Rework führen können. Plus, ohne Lock-in behalten Sie die Kontrolle über Ihre Infrastruktur.
Im Vergleich zu Alternativen hebt DataChains Fokus auf multimodale Heavy Data es ab – es ist nicht nur ein weiteres Datenmanagement-Tool; es ist gebaut für die nächste KI-Welle, von generativen Modellen bis Echtzeit-Agents.
Für wen ist DataChain?
DataChain ist ideal für eine breite Palette von Nutzern im KI-Ökosystem:
Entwickler und Data Scientists: Diejenigen, die ML-Pipelines bauen und Python-native Tools für multimodale Daten ohne SQL-Hürden benötigen.
KI/ML-Teams in Startups und Unternehmen: Von frühen Innovatoren bis Fortune-500-Unternehmen, die mit Videoanalyse, Audiotranskription oder medizinischer Bildgebung umgehen.
Forscher und Analysten: Jeder, der reproduzierbare Datensätze mit vollständiger Lineage für Experimente in Computer Vision, NLP oder multimodaler KI benötigt.
Produktentwickler: Erstellen von Copilots, Agents oder adaptiven Systemen, die auf angereicherte, versionierte Wissensbasen angewiesen sind.
Wenn Sie mit unstrukturierten Daten in Object Storage kämpfen und diese für KI nutzen möchten ohne Overhead, ist DataChain Ihre Go-to-Lösung.
Praktischer Wert und Use Cases
DataChain liefert greifbaren Wert, indem es Heavy Data in einen strategischen Asset verwandelt. Betrachten Sie diese realen Anwendungen:
Medien und Unterhaltung: Verarbeiten Sie Video- und Audio-Bibliotheken, um Embeddings für Empfehlungsengines oder Content-Moderation zu extrahieren.
Gesundheitswesen: Versionieren Sie MRT-Scans und PDFs für KI-gestützte Diagnostik, mit Compliance durch Data-Lineage-Tracking.
E-Commerce: Reichern Sie Produktbilder und -beschreibungen mit LLMs an, um personalisierte Suche und Virtual-Try-On-Features zu bauen.
Forschungslabore: Automatisieren Sie ETL für großvolumige Datensätze im multimodalen Lernen, um Model-Training-Zyklen zu beschleunigen.
Nutzer loben die Skalierbarkeit – müheloses Handling von Milliarden Dateien – und den Produktivitätsschub durch IDE-Integration. Während Preisdetails auf Anfrage verfügbar sind, senkt die Free Tier Barrieren für Experimente.
Zusammenfassend redefiniert DataChain Datenmanagement für KI im großen Maßstab. Durch kuratieren, anreichern und versionieren multimodaler Datensätze mit minimaler Reibung befähigt es effiziente Teams, in der Heavy-Data-Revolution zu führen. Bereit, Ihre Daten in einen KI-Vorteil zu verwandeln? Registrieren Sie sich noch heute und erkunden Sie GitHub für Open-Source-Beiträge.
Beste Alternativwerkzeuge zu "DataChain"
Dataloop ist ein KI-fähiger Datenstapel, der Datenmanagement, Automatisierungspipelines und eine Datenkennzeichnungsplattform bietet. Es beschleunigt KI-Projekte durch die Straffung von Daten-Workflows und die Integration von menschlichem Feedback.
Robi Labs ist ein KI-Forschungsunternehmen, das sich auf die Entwicklung von KI-Modellen, -Tools und -Plattformen konzentriert. Ziel ist es, Einzelpersonen durch zugängliche und leistungsstarke Technologie in den Bereichen Lernen, Kreativität und Innovation zu fördern.

Nomic Atlas ist eine KI-native Datenplattform, die große, unstrukturierte Datensätze für KI-Anwendungen, Datenanalysen und Workflows operationalisiert. Sie bietet Tools für die Datenerkundung, Zusammenarbeit und Integration.

Roboto ist eine Analyse-Engine, die für Robotik und physische KI entwickelt wurde und es Teams ermöglicht, multimodale Daten von Robotern effizient in großem Maßstab zu suchen, zu transformieren und zu analysieren, Anomalien zu identifizieren und die Analyse zu automatisieren.
Future AGI ist eine einheitliche LLM-Observability- und KI-Agenten-Evaluierungsplattform, die Unternehmen dabei hilft, durch umfassende Test-, Evaluierungs- und Optimierungswerkzeuge 99% Genauigkeit in KI-Anwendungen zu erreichen.

Blitzschnelle KI-Plattform für Entwickler. Bereitstellen, Feinabstimmen und Ausführen von über 200 optimierten LLMs und multimodalen Modellen mit einfachen APIs - SiliconFlow.
Falcon LLM ist eine Open-Source-Familie generativer großer Sprachmodelle von TII, mit Modellen wie Falcon 3, Falcon-H1 und Falcon Arabic für mehrsprachige, multimodale KI-Anwendungen, die effizient auf Alltagsgeräten laufen.

GPT-4 ist das neueste multimodale KI-Modell von OpenAI, das Bild- und Texteingaben akzeptiert und Textausgaben ausgibt. Es zeigt eine Leistung auf menschlichem Niveau bei professionellen und akademischen Benchmarks.
FiftyOne ist die führende Open-Source-Datenplattform für visuelle KI und Computer Vision, der Top-Unternehmen vertrauen, um die KI-Leistung mit besseren Daten zu maximieren. Datenkuration, intelligentere Annotation, Modellbewertung.
Innovatiana bietet Experten-Datenbeschriftung und erstellt hochwertige KI-Datensätze für ML, DL, LLM, VLM, RAG und RLHF, um ethische und wirkungsvolle KI-Lösungen zu gewährleisten.
Entdecken Sie die Welt von GPT6, einer superintelligenten KI mit Humor und fortschrittlichen Fähigkeiten, einschließlich multimodaler Unterstützung und Echtzeit-Lernen. Chatten Sie mit GPT6 und erleben Sie die Zukunft der KI!
Ocular AI ist eine multimodale Data-Lakehouse-Plattform, mit der Sie benutzerdefinierte KI-Modelle auf unstrukturierten Daten erfassen, kuratieren, suchen, mit Anmerkungen versehen und trainieren können. Entwickelt für die multimodale KI-Ära.

Bakery vereinfacht die Feinabstimmung und Monetarisierung von KI-Modellen. Perfekt für KI-Startups, ML-Ingenieure und Forscher. Entdecken Sie leistungsstarke Open-Source-KI-Modelle für Sprach-, Bild- und Videogenerierung.
ezML automatisiert visuelle Aufgaben mit Computer Vision in verschiedenen Branchen. Stellen Sie vorgefertigte Lösungen bereit oder lassen Sie sich eine individuelle Computer-Vision-Entwicklung erstellen.