Firecrawl
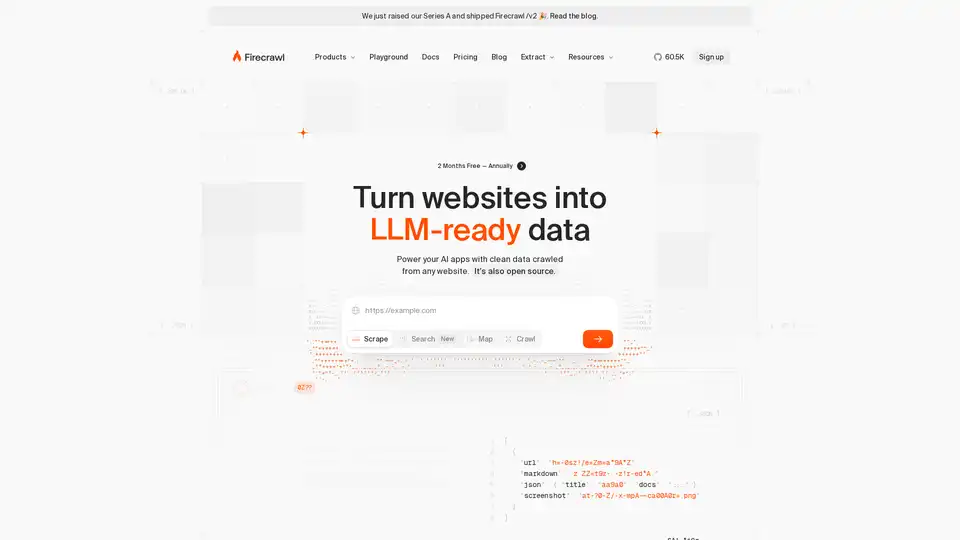
Übersicht von Firecrawl
Was ist Firecrawl?
Firecrawl hebt sich als revolutionäres Web-Daten-API ab, das speziell für AI-Entwickler und -Erbauer entwickelt wurde. In einer Welt, in der AI-Agenten und große Sprachmodelle (LLMs) frische, strukturierte Daten aus dem weiten Internet benötigen, vereinfacht Firecrawl den Prozess des Web-Crawlings, Scrapings und Suchens. Gestartet mit Unterstützung von Y Combinator und vertraut von über 5.000 Unternehmen, wandelt dieses Tool rohe Websites in saubere, Markdown-formatierte, JSON-strukturierte oder sogar Screenshot-bereite Ausgaben um, die sofort für AI-Reasoning und -Anwendungen einsetzbar sind. Ob Sie AI-Chats mit Echtzeit-Web-Kontext verbessern oder Lead-Daten für Verkaufsteams anreichern, Firecrawl beseitigt die traditionellen Kopfschmerzen des Web-Scrapings, wie Proxy-Management oder JavaScript-Rendering-Probleme.
Im Kern ist Firecrawl sowohl eine Open-Source-Bibliothek als auch ein gehosteter API-Dienst, der es für Solo-Entwickler bis hin zu Enterprise-Projekten zugänglich macht. Seine kürzliche Series-A-Finanzierung und die Veröffentlichung von Version 2 unterstreichen sein schnelles Wachstum und seine Hingabe an Innovationen in AI-Daten-Pipelines.
Wie funktioniert Firecrawl?
Firecrawl basiert auf einer Reihe von Kernprinzipien, die konventionelle Scraper übertreffen sollen. Im Gegensatz zu Tools wie Puppeteer oder cURL, die mit modernen, dynamischen Websites kämpfen, deckt Firecrawl 96 % des Webs ab – einschließlich JavaScript-lastiger Seiten und geschützter Inhalte – ohne auf Proxies oder Headless-Browser angewiesen zu sein. Dieser „no proxy headaches“-Ansatz gewährleistet Zuverlässigkeit und Geschwindigkeit und liefert Ergebnisse in unter 1 Sekunde für die meisten Anfragen, ideal für Echtzeit-AI-Agenten.
Der Workflow ist unkompliziert:
- Geben Sie eine URL oder Abfrage ein: Beginnen Sie mit einer einzelnen URL für Scraping, einer Site-Domain für Crawling oder einer Suchabfrage für webweite Erkundung.
- Intelligente Verarbeitung: Firecrawl verwendet smarte Warte-Mechanismen, um dynamischen Inhalt zu laden, behandelt Media-Parsing für PDFs und DOCX-Dateien und setzt Stealth-Modus ein, um echtes Benutzerverhalten nachzuahmen, Blöcke und CAPTCHAs zu vermeiden.
- Strukturierte Daten ausgeben: Erhalten Sie LLM-bereite Formate wie sauberes Markdown (frei von Werbung und Navigations-Unordnung), JSON mit extrahierten Metadaten oder Screenshots. Beim Crawling mappt es gesamte Sites und respektiert robots.txt, während es Daten aus allen zugänglichen Seiten extrahiert.
- Einfache Integration: Mit SDKs für Python, Node.js und sogar curl-Befehlen ist die Integration Entwickler-freundlich. Zum Beispiel kann ein einfaches Python-Skript eine Site wie firecrawl.dev in Sekunden scrapen.
Diese Effizienz resultiert aus seiner von Grund auf neuen Architektur, die Geschwindigkeit und Sauberkeit priorisiert. Benchmarks zeigen, dass Firecrawl Aufgaben in 49-52 ms abschließt, was Konkurrenten bei Weitem übertrifft und es perfekt für dynamische Apps macht, die sofortige Web-Einblicke benötigen.
Schlüsselfunktionen von Firecrawl
Firecrawl bietet eine Reihe von Funktionen, die es zur ersten Wahl für AI-Datenextraktion machen:
- Scrape: Extrahieren Sie vollständigen Inhalt von jeder URL in mehreren Formaten. Erhalten Sie Markdown ohne Boilerplate, JSON-Schemata für strukturierte Daten (z. B. Titel, Docs) und sogar Screenshots für visuelle Überprüfung.
- Crawl: Automatisch alle Seiten auf einer Website entdecken und scrapen, um einen umfassenden Index ohne manuelle Sitemaps aufzubauen. Sein selektives Caching ermöglicht Kontrolle über Speicherung und Frische.
- Search (Neu): Führen Sie Web-Suchen durch und rufen Sie vollständigen, kontextuellen Inhalt aus den Ergebnissen ab, um semantische Suchen oder Wissensbasen zu unterstützen.
- Map: Visualisieren Sie Site-Strukturen für bessere Navigation in großen Crawls.
- Actions for Interactive Scraping: Simulieren Sie Benutzerinteraktionen wie Klicken, Scrollen, Tippen oder Warten – entscheidend für Single-Page-Applications (SPAs).
- Media and Document Parsing: Behandeln Sie PDFs, DOCX und andere auf dem Web gehostete Dateien und geben Sie geparsten Text aus, der für AI-Verarbeitung bereit ist.
- Zero Configuration: Kein Bedarf, rotierende Proxies, Rate-Limits oder Orchestrierung zu managen – Firecrawl erledigt alles im Hintergrund.
- Open-Source Transparency: Die Kernbibliothek ist öffentlich auf GitHub verfügbar mit 60.5K Sternen, was Community-Beiträge und benutzerdefinierte Anpassungen ermöglicht.
Diese Funktionen gewährleisten Daten-Sauberkeit: Firecrawl entfernt intelligent Rauschen, erzwingt ethisches Scraping durch Respektierung von robots.txt und skaliert für große Projekte, ohne an Edge-Cases wie Authentifizierung oder CAPTCHAs zu scheitern (obwohl fortgeschrittene Setups benutzerdefinierte Handhabung erfordern können).
Primäre Anwendungsfälle für Firecrawl
Firecrawl glänzt in Szenarien, in denen AI hochwertige Web-Daten benötigt. So transformiert es Branchen:
- Smartere AI-Chats mit Kontext: Integrieren Sie Echtzeit-Web-Daten in Chatbots oder Assistenten. Zum Beispiel versorgen Sie ein AI wie Claude oder Cursor mit aktuellen Infos, um sicherzustellen, dass Antworten genau und aktuell sind. Entwickler berichten von 50x schnellerer Leistung im Vergleich zu Alternativen wie Apify.
- Lead-Enrichment und Sales Intelligence: Scrapen Sie Verzeichnisse, um CRM-Daten mit Kontaktdaten, Finanzierungsstadien und Entscheidungsträger-Details anzureichern. Verkaufsteams nutzen es, um „your leads zu kennen“, indem sie strukturierte Einblicke aus Unternehmensseiten ziehen.
- Tiefe Recherche und Wissensextraktion: Für akademische oder Markt-Recherche crawlen Sie Sites für Papers, News, Expertenmeinungen und Branchendaten. Bauen Sie benutzerdefinierte Suchtools, die umfassende, nicht verpasste Einblicke liefern.
- AI-Plattformen und Agent-Building: Lassen Sie Nutzer Apps mit Web-Daten über Integrationen wie Mendable.ai oder Code-Editoren (Claude Code, Cursor, Windsurf) erstellen. Es ist ideal für Plattformen, auf denen Kunden AI-Workflows bauen.
- SEO und Content Optimization: Extrahieren Sie Web-Daten für Keyword-Analyse oder Konkurrenz-Recherche, die in AI-gestützte SEO-Tools eingespeist werden.
Reale Beispiele umfassen Startups, die Firecrawl für die Verfolgung von Finanzierungsrunden nutzen, oder E-Commerce-Sites, die Produktinfos für Preis-Intelligence scrapen.
Warum Firecrawl gegenüber anderen Scrapern wählen?
In einem überfüllten Markt differenziert sich Firecrawl durch Leistung und Benutzerfreundlichkeit. Traditionelle Scraper scheitern oft an JS-gerenderten Seiten oder erfordern komplexe Setups, aber Firecrawls 96 % Abdeckung und Sub-Sekunden-Geschwindigkeiten machen es zuverlässig für AI-Pipelines. Es ist SOC 2 Type 2 konform für Sicherheit, bietet kostenlose Tarife ohne Kreditkarte und skaliert nahtlos – Credits für Scraping und Crawling sind kosteneffektiv, mit Pay-per-Use-Optionen.
Benutzer-Testimonials heben seinen Einfluss hervor: Morgan Linton nennt es „mind-blowing“ für AI-Coding, während Alex Reibman von Apify zu 50x Geschwindigkeitsgewinnen wechselte. Chris DeWeese wünscht, er hätte es früher entdeckt, und die Community lobt seine responsive Entwicklung, wie die Hinzufügung von TypeScript-Support in unter einer Stunde.
Preise starten kostenlos (2 Monate bei Jahresplänen), mit Plänen, die nach Credits skalieren – Scraping kostet minimal pro Anfrage, und fehlgeschlagene werden nicht berechnet. Kein Roll-over, aber flexible monatliche Abrechnung über Standardmethoden.
Für wen ist Firecrawl?
Firecrawl richtet sich an AI-Erbauer, Entwickler und Data Scientists, die Web-Daten ohne Aufwand benötigen. Es ist perfekt für:
- Solo-Entwickler und Startups: Schnelle Integration via SDKs für Prototypen.
- AI/ML-Engineers: LLMs mit sauberen Datensätzen für Training oder Inferenz füttern.
- Product Teams: Features wie Recherche-Tools oder Lead-Gen-Apps bauen.
- Enterprises: Große Crawls mit Compliance und Zuverlässigkeit.
Wenn Sie müde von brüchigen Scrapern sind, macht Firecrawls Open-Source-Ethos und bewährte Benchmarks es zum besten Weg, Web-Daten für AI-Innovationen zu nutzen.
Erste Schritte mit Firecrawl
Melden Sie sich kostenlos bei firecrawl.dev an – keine Kreditkarte erforderlich. Holen Sie sich Ihren API-Key aus dem Dashboard, installieren Sie das SDK (z. B. pip install firecrawl-py) und führen Sie ein einfaches Scrape aus:
from firecrawl import Firecrawl
app = Firecrawl(api_key="fc-YOUR_API_KEY")
result = app.scrape_url('https://example.com')
print(result['markdown'])
Erkunden Sie die Docs für fortgeschrittene Features wie Caching-Muster oder Action-Ketten. Treten Sie dem Discord oder GitHub-Community bei für Support und schauen Sie im Blog nach Updates wie der v2-Veröffentlichung.
Zusammenfassend ist Firecrawl nicht nur ein Scraper – es ist die Brücke, die das Internet zu AI bringt und smartere, schnellere Anwendungen mit minimalem Aufwand ermöglicht. Ob für Recherche, Enrichment oder agentische Workflows, es ist das Tool, das Web-Daten zugänglich und handlungsrelevant macht.
Beste Alternativwerkzeuge zu "Firecrawl"
SheetMagic bringt unbegrenzte KI-Power und Web Scraping direkt in Google Sheets. Generieren Sie Inhalte, extrahieren Sie Daten und automatisieren Sie Aufgaben mühelos mit der ChatGPT-Integration und einer Reihe von Scraping-Funktionen.

Olostep ist eine Webdaten-API für KI und Forschungsagenten. Sie ermöglicht es Ihnen, strukturierte Webdaten von jeder Website in Echtzeit zu extrahieren und Ihre Web-Research-Workflows zu automatisieren. Anwendungsfälle sind Daten für KI, Tabellenkalkulationsanreicherung, Leadgenerierung und mehr.
Agenty® ist eine No-Code-Web-Scraping-Software, die Datenerfassung, Änderungsüberwachung und Browserautomatisierung automatisiert. Extrahieren Sie mit KI wertvolle Informationen von Websites, verbessern Sie die Forschung und gewinnen Sie Einblicke.
Topicfinder ist ein KI-gestütztes Wettbewerbsforschungstool, das Tausende von hochwertigen Inhaltsthemen in Minuten mit SEO-Metriken, Filterung und KI-generierten optimierten Titeln findet.
Open Lovable ist ein kostenloses Open-Source AI Tool, das jede Website in Sekundenschnelle in React/Next.js Apps verwandelt. Klonen Sie Websites, generieren Sie sauberen Code und behalten Sie die volle Eigentümerschaft. Die beste Lovable.ai Alternative für Entwickler.
Hystruct AI vereinfacht Web Scraping mit KI-gestützter Automatisierung und bietet strukturierte Datenextraktion für Stellenanzeigen, E-Commerce-Produkte und benutzerdefinierte Schemata. Starten Sie mit 100 kostenlosen Credits monatlich.
PayPerQ (PPQ.AI) bietet sofortigen Zugriff auf führende KI-Modelle wie GPT-4o mit Bitcoin und Crypto. Bezahlen pro Abfrage ohne Abonnements oder Registrierung, unterstützt Text-, Bild- und Videogenerierung.

Rapture Parser: Eine KI-gestützte Web Scraping API, die Webseiten in strukturierte Daten umwandelt. Extrahieren Sie Text, Metadaten und umgehen Sie mühelos Anti-Scraping-Maßnahmen.
Scrapingdog ist eine Web-Scraping-API, die Proxys und Headless-Browser verwaltet und eine mühelose Datenextraktion ermöglicht.
Verwandeln Sie jede Website mit Skrape.ai in saubere, strukturierte Daten. Unsere KI-gestützte API extrahiert Daten in Ihrem bevorzugten Format für KI-Training.
WebScraping.AI ist eine KI-gestützte Scraping-API, die Proxys, Browser und HTML-Parsing für einfaches Web Scraping verwaltet.
ScrapeGraphAI: Extrahieren Sie strukturierte Daten von jeder Website mit unserer leistungsstarken LLM-gesteuerten Web-Scraping-API. Perfekt für Entwickler und Datenwissenschaftler.
Chat Data ist ein KI-Chatbot-Erstellungstool für Websites, Discord, Slack, Shopify, WordPress und mehr. Einmal trainieren, überall einsetzen. Anpassen, verbinden und teilen.
Automatisieren Sie die Produkt Datenextraktion mit Product Fetcher, einer KI-gestützten API. Scrapen Sie Preise, Bewertungen und SKUs von jeder Website ohne Programmierung, IP-Sperren oder CAPTCHAS. Starten Sie kostenlos!