BenchLLM
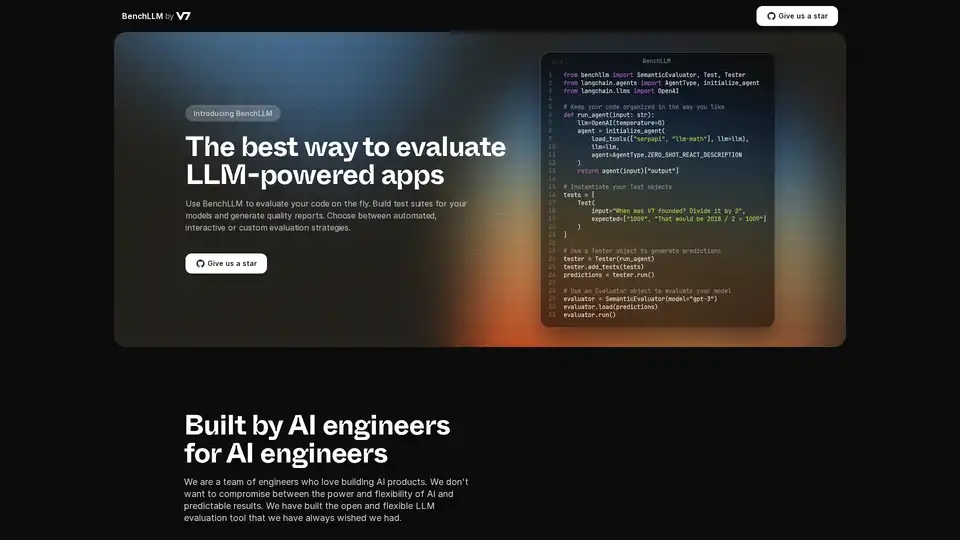
Overview of BenchLLM
What is BenchLLM?
BenchLLM is a tool designed to evaluate the performance and quality of applications powered by Large Language Models (LLMs). It provides a flexible and comprehensive framework for building test suites, generating quality reports, and monitoring model performance. Whether you need automated, interactive, or custom evaluation strategies, BenchLLM offers the features and capabilities to ensure your AI models meet the required standards.
How does BenchLLM work?
BenchLLM works by allowing users to define tests, run models against those tests, and then evaluate the results. Here’s a detailed breakdown:
- Define Tests Intuitively: Tests can be defined in JSON or YAML format, making it easy to set up and manage test cases.
- Organize Tests into Suites: Organize tests into suites for easy versioning and management. This helps in maintaining different versions of tests as the models evolve.
- Run Tests: Use the powerful CLI or flexible API to run tests against your models. BenchLLM supports OpenAI, Langchain, and any other API out of the box.
- Evaluate Results: BenchLLM provides multiple evaluation strategies to assess the performance of your models. It helps identify regressions in production and monitor model performance over time.
- Generate Reports: Generate evaluation reports and share them with your team. These reports provide insights into the strengths and weaknesses of your models.
Example Code Snippets:
Here’s an example of how to use BenchLLM with Langchain:
from benchllm import SemanticEvaluator, Test, Tester
from langchain.agents import AgentType, initialize_agent
from langchain.llms import OpenAI
## Keep your code organized in the way you like
def run_agent(input: str):
llm=OpenAI(temperature=0)
agent = initialize_agent(
load_tools(["serpapi", "llm-math"], llm=llm),
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
return agent(input)["output"]
## Instantiate your Test objects
tests = [
Test(
input="When was V7 founded? Divide it by 2",
expected=["1009", "That would be 2018 / 2 = 1009"]
)
]
## Use a Tester object to generate predictions
tester = Tester(run_agent)
tester.add_tests(tests)
predictions = tester.run()
## Use an Evaluator object to evaluate your model
evaluator = SemanticEvaluator(model="gpt-3")
evaluator.load(predictions)
evaluator.run()
Here’s an example of how to use BenchLLM with OpenAI’s ChatCompletion API:
import benchllm
from benchllm.input_types import ChatInput
import openai
def chat(messages: ChatInput):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0].message.content.strip()
@benchllm.test(suite=".")
def run(input: ChatInput):
return chat(input)
Key Features and Benefits
- Flexible API: Test code on the fly with support for OpenAI, Langchain, and other APIs.
- Powerful CLI: Run and evaluate models with simple CLI commands, ideal for CI/CD pipelines.
- Easy Evaluation: Define tests intuitively in JSON or YAML format.
- Automation: Automate evaluations within a CI/CD pipeline to ensure continuous quality.
- Insightful Reports: Generate and share evaluation reports to monitor model performance.
- Performance Monitoring: Detect regressions in production by monitoring model performance.
How to use BenchLLM?
- Installation: Download and install BenchLLM.
- Define Tests: Create test suites in JSON or YAML.
- Run Evaluations: Use the CLI or API to run tests against your LLM applications.
- Analyze Reports: Review the generated reports to identify areas for improvement.
Who is BenchLLM for?
BenchLLM is designed for AI engineers and developers who want to ensure the quality and reliability of their LLM-powered applications. It is particularly useful for:
- AI Engineers: Those building and maintaining AI products.
- Developers: Integrating LLMs into their applications.
- Teams: Looking to monitor and improve the performance of their AI models.
Why choose BenchLLM?
BenchLLM provides a comprehensive solution for evaluating LLM applications, offering flexibility, automation, and insightful reporting. It is built by AI engineers who understand the need for powerful and flexible tools that deliver predictable results. By using BenchLLM, you can:
- Ensure the quality of your LLM applications.
- Automate the evaluation process.
- Monitor model performance and detect regressions.
- Improve collaboration with insightful reports.
By choosing BenchLLM, you are opting for a robust and reliable solution to evaluate your AI models and ensure they meet the highest standards of performance and quality.
Best Alternative Tools to "BenchLLM"

Confident AI is an LLM evaluation platform built on DeepEval, enabling engineering teams to test, benchmark, safeguard, and enhance LLM application performance. It provides best-in-class metrics, guardrails, and observability for optimizing AI systems and catching regressions.
Maxim AI is an end-to-end evaluation and observability platform that helps teams ship AI agents reliably and 5x faster with comprehensive testing, monitoring, and quality assurance tools.
Explore Qwen3 Coder, Alibaba Cloud's advanced AI code generation model. Learn about its features, performance benchmarks, and how to use this powerful, open-source tool for development.
EvalMy.AI automates AI answer verification & RAG assessment, streamlining LLM testing. Ensure accuracy, configurability & scalability with an easy-to-use API.
Refact.ai, the #1 open-source AI agent for software development, automates coding, debugging, and testing with full context awareness. An open-source alternative to Cursor and Copilot.

Openlayer is an enterprise AI platform providing unified AI evaluation, observability, and governance for AI systems, from ML to LLMs. Test, monitor, and govern AI systems throughout the AI lifecycle.
Parea AI is the ultimate experimentation and human annotation platform for AI teams, enabling seamless LLM evaluation, prompt testing, and production deployment to build reliable AI applications.
Athina is a collaborative AI platform that helps teams build, test, and monitor LLM-based features 10x faster. With tools for prompt management, evaluations, and observability, it ensures data privacy and supports custom models.
Gentrace helps trace, evaluate, and analyze errors for AI agents. Chat with AI to debug traces, automate evaluations, and fine-tune LLM products for reliable performance. Start free today!
Weco AI automates machine learning experiments using AIDE ML technology, optimizing ML pipelines through AI-driven code evaluation and systematic experimentation for improved accuracy and performance metrics.
Vivgrid is an AI agent infrastructure platform that helps developers build, observe, evaluate, and deploy AI agents with safety guardrails and low-latency inference. It supports GPT-5, Gemini 2.5 Pro, and DeepSeek-V3.
PromptPoint helps you design, test and deploy prompts fast with automated prompt testing. Turbo charge your team’s prompt engineering with high-quality LLM outputs.
UpTrain is a full-stack LLMOps platform providing enterprise-grade tooling to evaluate, experiment, monitor, and test LLM applications. Host on your own secure cloud environment and scale AI confidently.
Freeplay is an AI platform designed to help teams build, test, and improve AI products through prompt management, evaluations, observability, and data review workflows. It streamlines AI development and ensures high product quality.