DataChain
Descripción general de DataChain
¿Qué es DataChain?
DataChain es una plataforma nativa de IA diseñada para manejar las complejidades de los datos pesados en la era del aprendizaje automático avanzado y la inteligencia artificial. Se destaca al proporcionar un registro centralizado para conjuntos de datos multimodales, que incluyen videos, archivos de audio, PDFs, imágenes, escáneres de MRI e incluso embeddings. A diferencia de las herramientas tradicionales basadas en SQL que luchan con datos no estructurados o a gran escala almacenados en tiendas de objetos como S3, GCS o Azure, DataChain cierra la brecha entre flujos de trabajo amigables para desarrolladores y procesamiento a escala empresarial. Esta plataforma permite a startups hasta empresas Fortune 500 curar, enriquecer y versionar sus conjuntos de datos de manera eficiente, transformando entradas multimodales crudas en conocimiento accionable de IA.
En su núcleo, DataChain aborda el cambio de big data a lo que llama 'heavy data'—formatos ricos y no estructurados rebosantes de potencial sin explotar para aplicaciones de IA. Ya sea que estés construyendo agentes, copilotos o flujos de trabajo adaptativos, DataChain asegura que tu pipeline de datos no requiera reprocesamiento constante, ahorrando tiempo y recursos mientras desbloquea insights más profundos.
¿Cómo funciona DataChain?
DataChain opera bajo una filosofía centrada en el desarrollador, combinando la simplicidad de Python con la escalabilidad de operaciones similares a SQL. Aquí hay un desglose de sus mecanismos clave:
Registro Centralizado de Conjuntos de Datos: Todos los conjuntos de datos se rastrean con linaje completo, metadatos y versionado. Puedes acceder a ellos de manera fluida a través de una interfaz de usuario (UI), interfaces de chat, entornos de desarrollo integrados (IDEs) o incluso agentes de IA mediante el Protocolo de Control de Modelos (MCP). Este registro actúa como una fuente única de verdad, facilitando la gestión de dependencias y la reproducción de resultados.
Simplicidad de Python Encuentra Escala de SQL: Los desarrolladores escriben en un lenguaje familiar—Python—a lo largo de tanto código como operaciones de datos. Esto elimina los silos creados por herramientas SQL separadas, mejorando la integración con IDEs y agentes de IA. Por ejemplo, puedes consultar y manipular datos pesados sin cambiar de contexto, agilizando tu flujo de trabajo.
Desarrollo Local y Escalado en la Nube: Comienza a construir y probar pipelines de datos en tu IDE local para iteraciones rápidas. Una vez listo, escala sin esfuerzo a cientos de GPUs en la nube con cero reescritura de código. Este enfoque híbrido maximiza la productividad sin comprometer el rendimiento para tareas a gran escala.
Cero Copia de Datos y Bloqueo: Tus archivos originales—videos, imágenes, audio—permanecen en su almacenamiento nativo como S3. DataChain simplemente hace referencia y rastrea versiones, evitando duplicaciones innecesarias o bloqueo de proveedores. Esto no solo reduce costos, sino que también asegura soberanía de datos y flexibilidad.
La plataforma aprovecha modelos de lenguaje grandes (LLMs) y modelos de aprendizaje automático para extraer estructura, embeddings e insights de fuentes no estructuradas. Por ejemplo, puede aplicar modelos a videos o PDFs durante procesos ETL (Extract, Transform, Load), organizando el caos en formatos listos para IA.
Características Principales de DataChain
La suite de herramientas de DataChain cubre cada etapa del manejo de datos para proyectos de IA. Las características clave incluyen:
Dominio de Datos Multimodales: Maneja formatos diversos como video (🎥), audio (🎧), PDFs (📄), imágenes (🖼️) y escáneres médicos (🔬 MRI) en un solo lugar. Extrae insights usando LLMs para procesar contenido no estructurado sin esfuerzo.
Pipelines ETL Sin Fisuras: Construye flujos de trabajo automatizados para convertir archivos crudos en conjuntos de datos enriquecidos. Filtra, une y actualiza datos a escala, impulsando todo desde seguimiento de experimentos hasta versionado de modelos.
Linaje de Datos y Reproducibilidad: Rastrea cada dependencia entre código, datos y modelos. Reproduce conjuntos de datos bajo demanda y automatiza actualizaciones, lo cual es crucial para investigación de ML reproducible y cumplimiento normativo.
Procesamiento a Gran Escala: Maneja millones o miles de millones de archivos sin cuellos de botella. Calcula actualizaciones de manera eficiente y aprovecha ML para filtrado avanzado, lo que lo hace ideal para escenarios de datos pesados.
Integración y Accesibilidad: Soporta UI, chat, IDEs y agentes. Elementos de código abierto a través del repositorio de GitHub permiten personalización, mientras que el Studio basado en la nube proporciona un entorno listo para usar.
Estas características están respaldadas por asociaciones confiables con líderes de la industria global, asegurando confiabilidad para implementaciones de IA de alto riesgo.
Cómo Usar DataChain
Comenzar con DataChain es sencillo y gratuito para empezar:
Regístrate: Crea una cuenta en el sitio web de DataChain para acceder a la plataforma. Sin costos iniciales—comienza a explorar inmediatamente.
Configura Tu Entorno: Conecta tu almacenamiento de objetos (por ejemplo, S3) e importa conjuntos de datos. Usa la UI intuitiva o el SDK de Python para comenzar a curar datos.
Construye Pipelines: Desarrolla en tu IDE local usando Python. Aplica modelos de ML para enriquecimiento, luego despliega a la nube para escalado.
Versiona y Rastrea: Registra conjuntos de datos con metadatos y linaje. Usa MCP para interacciones con agentes o consulta mediante lenguaje natural.
Monitorea e Itera: Aprovecha el registro para reproducir resultados, actualizar conjuntos de datos vía ETL y analizar insights para tus modelos de IA.
La documentación, una guía de inicio rápido y el soporte de la comunidad Discord hacen que la incorporación sea fluida. Para necesidades empresariales, contacta a ventas para precios y características adaptadas a tu escala.
¿Por Qué Elegir DataChain?
En un panorama donde la IA demanda conjuntos de datos cada vez más grandes y complejos, DataChain proporciona una ventaja competitiva al hacer que los datos pesados sean accesibles y manejables. Las herramientas tradicionales fallan en formatos no estructurados, lo que lleva a silos e ineficiencias. DataChain elimina estos puntos de dolor con su enfoque de cero copia, reduciendo costos de almacenamiento hasta un 100% en algunos casos, y su diseño centrado en el desarrollador acelera el tiempo para obtener insights.
Los equipos que usan DataChain reportan un seguimiento de experimentos más rápido, versionado de modelos sin fisuras y automatización robusta de pipelines. Es particularmente valioso para evitar reprocesamiento en desarrollo de IA iterativo, donde cambios en datos o modelos pueden de lo contrario cascadear en horas de reescritura. Además, sin bloqueo, retienes el control sobre tu infraestructura.
En comparación con alternativas, el enfoque de DataChain en datos pesados multimodales lo distingue—no es solo otra herramienta de gestión de datos; está construido para la próxima ola de IA, desde modelos generativos hasta agentes en tiempo real.
¿Para Quién es DataChain?
DataChain es ideal para una amplia gama de usuarios en el ecosistema de IA:
Desarrolladores y Científicos de Datos: Aquellos que construyen pipelines de ML y necesitan herramientas nativas de Python para datos multimodales sin obstáculos de SQL.
Equipos de IA/ML en Startups y Empresas: Desde innovadores en etapas tempranas hasta empresas Fortune 500 que lidian con análisis de video, transcripción de audio o imágenes médicas.
Investigadores y Analistas: Cualquiera que requiera conjuntos de datos reproducibles con linaje completo para experimentos en visión por computadora, NLP o IA multimodal.
Constructores de Productos: Creando copilotos, agentes o sistemas adaptativos que dependen de bases de conocimiento enriquecidas y versionadas.
Si estás lidiando con datos no estructurados en almacenamiento de objetos y quieres aprovecharlos para IA sin el sobrecargo, DataChain es tu solución principal.
Valor Práctico y Casos de Uso
DataChain entrega valor tangible al transformar datos pesados en un activo estratégico. Considera estas aplicaciones del mundo real:
Medios y Entretenimiento: Procesa bibliotecas de video y audio para extraer embeddings para motores de recomendación o moderación de contenido.
Salud: Versiona escáneres de MRI y PDFs para diagnósticos impulsados por IA, asegurando cumplimiento con rastreo de linaje de datos.
Comercio Electrónico: Enriqucece imágenes y descripciones de productos usando LLMs para construir búsqueda personalizada y características de prueba virtual.
Laboratorios de Investigación: Automatiza ETL para conjuntos de datos a gran escala en aprendizaje multimodal, acelerando ciclos de entrenamiento de modelos.
Los usuarios elogian su escalabilidad—manejando miles de millones de archivos sin esfuerzo—y el impulso de productividad de la integración con IDE. Aunque los detalles de precios están disponibles al contactar, el nivel gratuito reduce barreras para experimentación.
En resumen, DataChain redefine la gestión de datos para IA a escala. Al curar, enriquecer y versionar conjuntos de datos multimodales con fricción mínima, empodera a equipos eficientes para liderar en la revolución de datos pesados. ¿Listo para convertir tus datos en una ventaja de IA? Regístrate hoy y explora su GitHub para contribuciones de código abierto.
Mejores herramientas alternativas a "DataChain"
Dataloop es una pila de datos lista para IA que ofrece gestión de datos, pipelines de automatización y una plataforma de etiquetado de datos. Acelera los proyectos de IA agilizando los flujos de trabajo de datos e integrando la retroalimentación humana.
Tafi Avatar, parte de Daz 3D, proporciona conjuntos de datos de personajes y entornos 3D normalizados y generados por procedimientos para el entrenamiento de IA. Ofrece generación de personajes paramétricos a escala, anatomía humana realista y flexibilidad de tuberías.

Nomic Atlas es una plataforma de datos nativa de IA que operacionaliza grandes conjuntos de datos no estructurados para aplicaciones de IA, análisis de datos y flujos de trabajo. Ofrece herramientas para la exploración de datos, la colaboración y la integración.
Stability AI ofrece herramientas de edición y generación de medios multimodales para empresas, lo que permite la creación de activos de alta calidad, experiencias inmersivas y flujos de trabajo personalizados con IA de nivel empresarial.

Roboto es un motor de análisis diseñado para la robótica y la IA física, que permite a los equipos buscar, transformar y analizar de manera eficiente datos multimodales de robots a escala, identificar anomalías y automatizar el análisis.
Maxim AI es una plataforma integral de evaluación y observabilidad que ayuda a los equipos a implementar agentes de IA de manera confiable y 5 veces más rápido con herramientas completas de prueba, monitoreo y garantía de calidad.
Hive ofrece modelos de IA de vanguardia para entender, buscar y generar contenido. Ideal para moderación, protección de marca y tareas generativas con integración API.
Qwen Image es un generador de imágenes avanzado de 20B parámetros con capacidades innovadoras de renderizado de texto, que soporta generación de texto complejo en chino e inglés, edición precisa de imágenes y creación multimodal.
FiftyOne es la plataforma de datos de visión artificial e IA visual de código abierto líder, en la que confían las principales empresas para maximizar el rendimiento de la IA con mejores datos. Curación de datos, anotación más inteligente, evaluación de modelos.
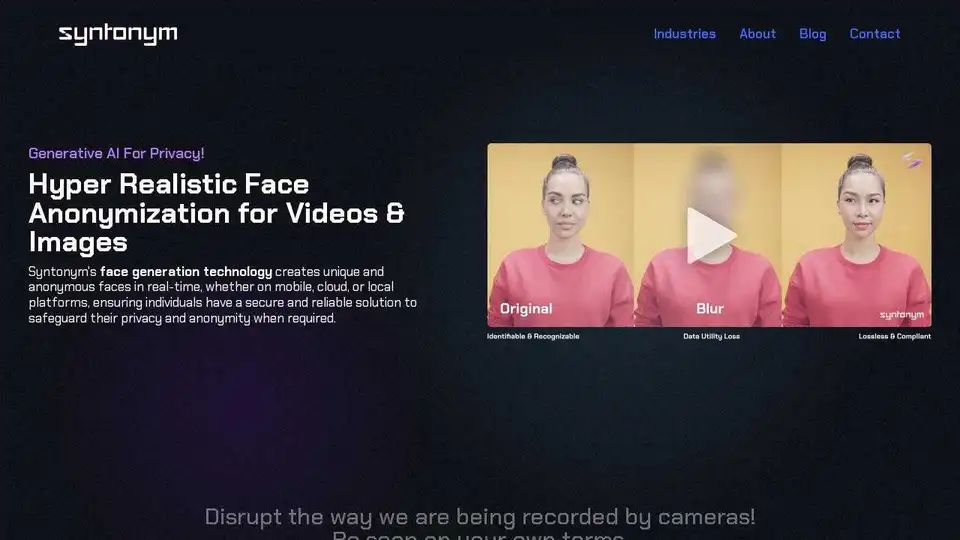
Syntonym potencia la visión artificial al proporcionar anonimización sin pérdidas, protegiendo los datos personales mientras mantiene la utilidad de los datos para los modelos de IA. Garantice la privacidad y el cumplimiento con las soluciones de anonimización en tiempo real.
Innovatiana ofrece etiquetado de datos experto y crea conjuntos de datos de IA de alta calidad para ML, DL, LLM, VLM, RAG y RLHF, garantizando soluciones de IA éticas e impactantes.
Thordata ofrece proxies residenciales de alta calidad para un web scraping de datos sin problemas, perfecto para IA, BI y flujos de trabajo. Accede a más de 60 millones de IPs con facturación basada en el tráfico y un rendimiento fiable.
Ocular AI es una plataforma de data lakehouse multimodal que le permite ingerir, curar, buscar, anotar y entrenar modelos de IA personalizados en datos no estructurados. Creado para la era de la IA multimodal.
Mixpeek ofrece una API para desarrolladores para la comprensión de contenido nativo de IA, lo que permite la búsqueda semántica y la clasificación automatizada en varios tipos de datos no estructurados.