Llama Family
Descripción general de Llama Family
Familia Llama: El Ecosistema de Modelos de IA de Código Abierto
¿Qué es Familia Llama? La Familia Llama es una comunidad de código abierto dedicada a promover el desarrollo de la Inteligencia Artificial General (AGI) a través de esfuerzos colaborativos centrados en los modelos Llama y tecnologías relacionadas. Su objetivo es crear una plataforma donde desarrolladores y entusiastas puedan contribuir a un ecosistema de código abierto que abarque varios aspectos de la AI, desde modelos a gran escala hasta modelos más pequeños, desde texto hasta capacidades multimodales y desde software hasta optimizaciones de algoritmos de hardware.
Componentes Clave de Familia Llama
Modelos: La comunidad se centra en varios modelos Llama de código abierto por Meta, incluidos Llama, Llama 2, Llama 3, Code Llama y Atom. Estos modelos cubren una variedad de tamaños de parámetros y conjuntos de datos de entrenamiento, que atienden a diferentes casos de uso y direcciones de investigación.
Cómputo: La comunidad fomenta la colaboración y el intercambio de recursos para el entrenamiento y la experimentación de modelos. Esto incluye la utilización de recursos de GPU como la serie GeForce RTX, NVIDIA H100 y A100 Tensor Core GPUs.
Comunidad: Un aspecto central de la Familia Llama es su vibrante comunidad de desarrolladores, investigadores y entusiastas. La comunidad fomenta la colaboración, el intercambio de conocimientos y la creación conjunta de recursos y herramientas.
Modelos Llama
Meta Llama
El modelo Llama de código abierto por Meta es ampliamente utilizado tanto en la industria como en la academia. Las versiones incluyen 1B, 3B, 8B, 70B y 405B, con datos de entrenamiento que superan los 15.0T tokens. Los modelos de visión incluyen 11B y 90B, entrenados en más de 6 mil millones de pares imagen-texto.
| Model | Training Data | Params | Tokens | Release Date |
|---|---|---|---|---|
| LLaMA | English CommonCrawl, C4, Github, Wikipedia, Gutenberg and Books3, ArXiv, Stack Exchange | 7B (6.7B) | 1.0T | 2023/02/24 |
| 13B (13.0B) | 1.0T | |||
| 33B (32.5B) | 1.4T | |||
| 65B (65.2B) | 1.4T | |||
| Llama 2 | A new mix of publicly available online data | 7B | 2.0T | 2023/07/18 |
| 13B | 2.0T | |||
| 34B | 2.0T | |||
| 70B | 2.0T | |||
| Llama 3 | A new mix of publicly available online data | 8B | 15.0T | 2024/04/18 |
| 70B | 15.0T | |||
| Llama 3.1 | Collected from publicly available sources, over 5% of the Llama 3 pretraining dataset consists of high-quality non-English data that covers over 30 languages | 8B | 15.0T | 2024/07/23 |
| 70B | 15.0T | |||
| 405B | 15.0T | |||
| Llama 3.2 | Llama 3.2-Text: A new mix of publicly available online data | 1B (1.23B) | 9.0T | 2024/09/25 |
| 3B (3.21B) | 9.0T | |||
| Llama 3.2-Vision | Pretrained on image and text pairs. The instruction tuning data includes publicly available vision instruction datasets, as well as over 3M synthetically generated examples | 11B (10.6B) | 6B (image, text) pairs | |
| 90B (88.8B) | 6B (image, text) pairs |
Code Llama
Code Llama se entrena sobre Llama 2 utilizando datos de código y se clasifica en Modelo Base, Modelo Python y Modelo Instruct, con tamaños de parámetros de 7B, 13B, 34B y 70B. Admite la continuación, el relleno y la programación basada en instrucciones de código.
| Model | Training Data | Params | Type |
|---|---|---|---|
| Code Llama | Based on Llama 2, trained using a public code dataset of 500B tokens. To help the model retain natural language understanding skills, 8% of the sample data comes from natural language datasets related to code. | 7B | Base Model: a foundational model for code generation tasks |
| Python: a version specialized for Python | |||
| Instruct: a fine-tuned version with human instructions and self-instruct code synthesis data | |||
| 13B | |||
| 34B | |||
| 70B |
Atom
Atom, desarrollado conjuntamente por AtomEcho y Familia Llama, se basa en la arquitectura Llama y se entrena en 2.7T de corpus chinos y multilingües, con tamaños de parámetros que incluyen 1B, 7B y 13B. Atom mejora las capacidades del idioma chino del modelo Llama.
| Model | Training Data | Params | Tokens | Release Date |
|---|---|---|---|---|
| Atom | Chinese and multilingual encyclopedias, books, blogs, news, novels, financial data, legal data, medical data, code, paper, Chinese NLP competition datasets, etc. | 1B | 2.7T | 2023/12/20 |
| 7B | 2.7T | 2023/08/28 | ||
| 13B | 2.7T | 2023/07/31 |
Cómo Contribuir a Familia Llama
- Únete a la Comunidad: Interactúa con otros desarrolladores y entusiastas a través de foros, grupos de chat y eventos.
- Contribuye con Código: Envía solicitudes de extracción con correcciones de errores, nuevas características o mejoras del modelo.
- Comparte Recursos: Comparte conjuntos de datos, scripts de entrenamiento y modelos pre-entrenados con la comunidad.
- Proporciona Comentarios: Ofrece comentarios sobre los modelos y herramientas existentes para ayudar a mejorar su calidad y usabilidad.
¿Por qué es importante Familia Llama?
La Familia Llama es importante porque fomenta la colaboración y acelera el desarrollo de modelos de AI de código abierto. Al proporcionar una plataforma para que desarrolladores e investigadores compartan recursos y conocimientos, la Familia Llama ayuda a democratizar el acceso a la tecnología de AI y promueve la innovación.
Conclusión
La Familia Llama es una comunidad en crecimiento dedicada a promover la AI a través de la colaboración de código abierto. ¡Únete a la Familia Llama hoy mismo para contribuir al futuro de la AI!
Mejores herramientas alternativas a "Llama Family"
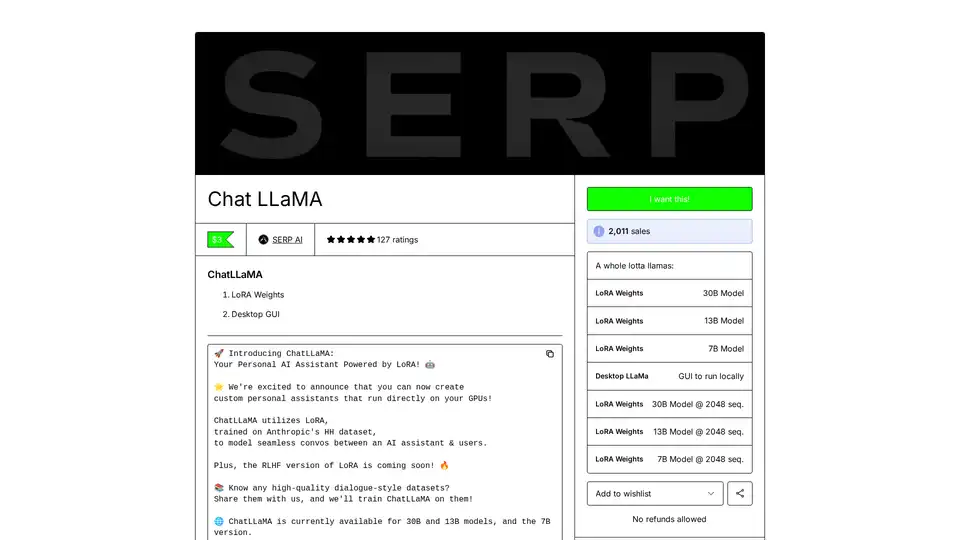
ChatLLaMA es un asistente de IA entrenado con LoRA basado en modelos LLaMA, que permite conversaciones personalizadas en tu GPU local. Incluye GUI de escritorio, entrenado en el conjunto de datos HH de Anthropic, disponible para modelos de 7B, 13B y 30B.
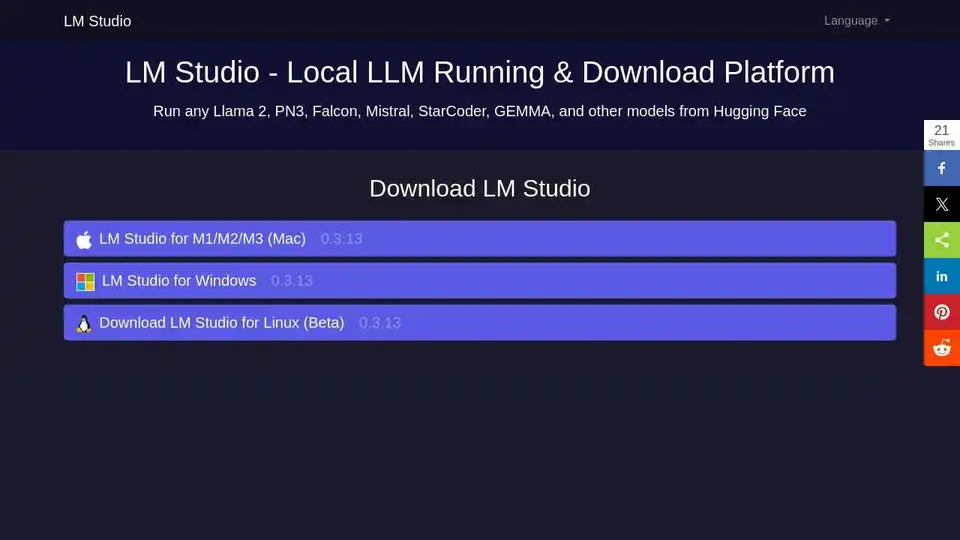
LM Studio es una aplicación de escritorio fácil de usar para ejecutar y descargar modelos de lenguaje grandes (LLM) de código abierto como LLaMa y Gemma localmente en tu ordenador. Incluye una interfaz de chat integrada y un servidor compatible con OpenAI para interacción offline, haciendo la IA accesible sin programación.
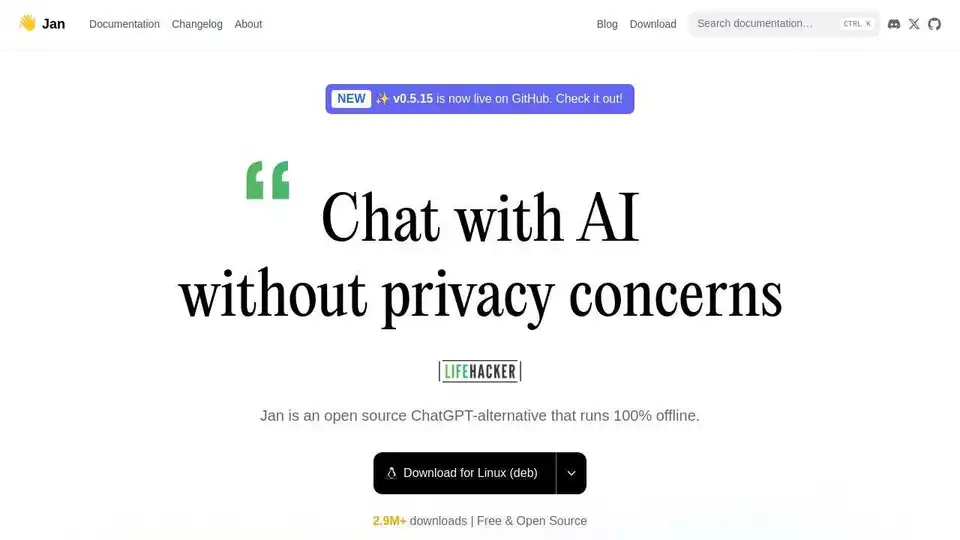
Jan es un cliente de IA de código abierto y de prioridad sin conexión. Ejecute modelos de lenguaje grandes (LLM) localmente con privacidad y sin facturas de API. Conéctese a varios modelos y servicios.

TextGen es un plugin de IA de código abierto para Obsidian que mejora la toma de notas con plantillas impulsadas por IA y generación de contenido inteligente.
xTuring es una biblioteca de código abierto que permite a los usuarios personalizar y ajustar finamente Modelos de Lenguaje Grandes (LLMs) de manera eficiente, enfocándose en simplicidad, optimización de recursos y flexibilidad para personalización de IA.
Cheshire Cat AI es un framework de código abierto que simplifica la construcción de agentes de IA. Admite LLM, API externas y plugins, todo dentro de un entorno Dockerizado para una fácil implementación y personalización.
ProxyAI es un asistente de código impulsado por IA para IDE de JetBrains, que ofrece finalización de código, edición en lenguaje natural y soporte offline con LLM locales. Mejora tu codificación con IA.
Sesame AI tiene como objetivo lograr la 'presencia de voz' en la IA, haciendo que las interacciones habladas se sientan reales y comprensibles. Explore su modelo de voz conversacional (CSM) para un diálogo natural.
FinGPT: Un modelo de lenguaje grande financiero de código abierto para democratizar los datos financieros, el análisis de sentimientos y la previsión. Ajuste fino rápidamente para obtener información oportuna del mercado.
Falcon LLM es una familia de modelos de lenguaje grandes generativos de código abierto de TII, con modelos como Falcon 3, Falcon-H1 y Falcon Arabic para aplicaciones de IA multilingües y multimodales que se ejecutan eficientemente en dispositivos cotidianos.
Replicate te permite ejecutar y ajustar modelos de aprendizaje automático de código abierto con una API en la nube. Construye y escala productos de IA con facilidad.
CalStudio es una plataforma sin código que permite a los creadores construir, lanzar y monetizar aplicaciones de IA personalizadas en minutos. Ofrece alojamiento, integración, análisis y acceso a los principales modelos de IA sin claves API.
Explora el repositorio Awesome ChatGPT Prompts, una colección curada de prompts para optimizar ChatGPT y otros LLMs como Claude y Gemini en tareas desde escritura hasta codificación. Mejora interacciones AI con ejemplos probados.
El servicio de inferencia de Nebius AI Studio ofrece modelos de código abierto alojados para resultados más rápidos, baratos y precisos que las APIs propietarias. Escala sin problemas sin MLOps, ideal para RAG y cargas de trabajo de producción.