Nebius AI Studio Inference Service
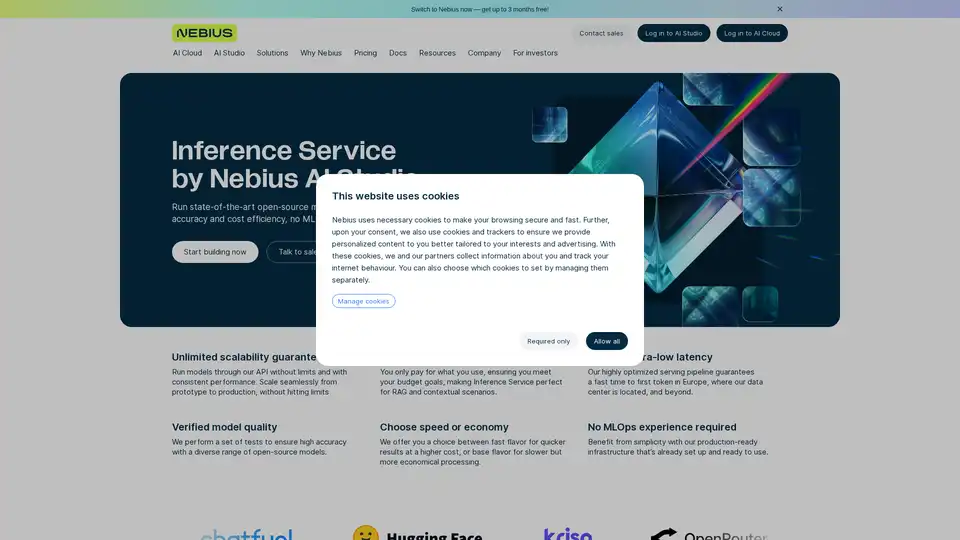
Descripción general de Nebius AI Studio Inference Service
¿Qué es el Servicio de Inferencia de Nebius AI Studio?
El Servicio de Inferencia de Nebius AI Studio es una plataforma potente diseñada para ayudar a desarrolladores y empresas a ejecutar modelos de IA de código abierto de vanguardia con rendimiento de grado empresarial. Lanzado como un producto clave de Nebius, simplifica el despliegue de modelos de lenguaje grandes (LLMs) para tareas de inferencia, eliminando la necesidad de configuraciones complejas de MLOps. Ya sea que estés construyendo aplicaciones de IA, prototipos o escalando a producción, este servicio proporciona endpoints para modelos populares como la serie Llama de Meta, DeepSeek-R1 y variantes de Mistral, asegurando alta precisión, baja latencia y eficiencia de costos.
En su núcleo, el servicio aloja estos modelos en una infraestructura optimizada ubicada en Europa (Finlandia), aprovechando un pipeline de servicio altamente eficiente. Esta configuración garantiza una latencia ultra baja, especialmente para respuestas de tiempo hasta el primer token, lo que lo hace adecuado para aplicaciones en tiempo real como chatbots, RAG (Generación Aumentada por Recuperación) y escenarios de IA contextuales. Los usuarios se benefician de una escalabilidad ilimitada, lo que significa que puedes pasar de pruebas iniciales a producción de alto volumen sin cuellos de botella de rendimiento o límites ocultos.
¿Cómo funciona el Servicio de Inferencia de Nebius AI Studio?
El servicio opera a través de una API sencilla que es compatible con bibliotecas familiares como el SDK de OpenAI, haciendo que la integración sea fluida para desarrolladores que ya usan herramientas similares. Para comenzar, regístrate para obtener créditos gratuitos y accede al Playground: una interfaz web amigable para probar modelos sin codificar. Desde allí, puedes cambiar a llamadas API para uso programático.
Aquí hay un ejemplo básico de cómo interactuar con él usando Python:
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("NEBIUS_API_KEY"),
base_url='https://api.studio.nebius.com/v1'
)
completion = client.chat.completions.create(
messages=[{'role': 'user', 'content': 'What is the answer to all questions?'}],
model='meta-llama/Meta-Llama-3.1-8B-Instruct-fast'
)
Este fragmento de código demuestra cómo consultar un modelo como Meta-Llama-3.1-8B-Instruct en modo 'fast', entregando respuestas rápidas. El servicio soporta dos variantes: 'fast' para tareas críticas de velocidad a un precio premium, y 'base' para procesamiento económico ideal para cargas de trabajo en masa. Todos los modelos pasan por pruebas rigurosas para verificar la calidad, asegurando que las salidas rivalicen con modelos propietarios como GPT-4o en benchmarks para Llama-405B, con hasta 3x de ahorros en tokens de entrada.
La seguridad de datos es una prioridad, con servidores en Finlandia que cumplen con estrictas regulaciones europeas. No se envían datos fuera de la infraestructura innecesariamente, y los usuarios pueden solicitar instancias dedicadas para un aislamiento mejorado a través de la consola de autoservicio o el equipo de soporte.
Características Principales y Ventajas Principales
Nebius AI Studio se destaca con varias características clave que abordan puntos de dolor comunes en la inferencia de IA:
Garantía de Escalabilidad Ilimitada: Ejecuta modelos sin cuotas o limitaciones de velocidad. Escala sin problemas de prototipos a producción, manejando cargas de trabajo diversas con facilidad.
Optimización de Costos: Paga solo por lo que usas, con precios hasta 3x más baratos en tokens de entrada en comparación con competidores. Planes flexibles comienzan con $1 en créditos gratuitos, y opciones como la variante 'base' mantienen los gastos bajos para aplicaciones RAG y de contexto largo.
Latencia Ultra Baja: Pipelines optimizados entregan tiempos rápidos hasta el primer token, particularmente en Europa. Resultados de benchmarks muestran un rendimiento superior sobre rivales, incluso para tareas de razonamiento complejas.
Calidad de Modelos Verificada: Cada modelo se prueba para precisión en matemáticas, código, razonamiento y capacidades multilingües. Modelos disponibles incluyen:
- Meta Llama-3.3-70B-Instruct: 128k de contexto, rendimiento de texto mejorado.
- Meta Llama-3.1-405B-Instruct: 128k de contexto, potencia comparable a GPT-4.
- DeepSeek-R1: Licenciado bajo MIT, destaca en matemáticas y código (128k de contexto).
- Mixtral-8x22B-Instruct-v0.1: Modelo MoE para codificación/matemáticas, soporte multilingüe (65k de contexto).
- OLMo-7B-Instruct: Totalmente abierto con datos de entrenamiento publicados (2k de contexto).
- Phi-3-mini-4k-instruct: Fuerte en razonamiento (4k de contexto).
- Mistral-Nemo-Instruct-2407: Compacto pero superando a modelos más grandes (128k de contexto).
Se agregan más modelos regularmente: verifica el Playground para lo último.
Sin MLOps Requerido: Infraestructura preconfigurada significa que te enfocas en construir, no en gestionar servidores o despliegues.
UI e API Simples: El Playground ofrece un entorno sin código para experimentación, mientras que la API soporta integración fácil en aplicaciones.
Estas características hacen que el servicio no solo sea eficiente, sino también accesible, respaldado por benchmarks que muestran mejor velocidad y costo para modelos como Llama-405B.
¿Para quién es el Servicio de Inferencia de Nebius AI Studio?
Este servicio apunta a una amplia gama de usuarios, desde desarrolladores individuales prototipando aplicaciones de IA hasta empresas manejando cargas de trabajo de producción a gran escala. Es ideal para:
Constructores de Aplicaciones y Startups: Simplifica la integración de modelos fundacionales sin costos de infraestructura pesados. Los créditos gratuitos y el Playground bajan la barrera de entrada.
Empresas en Gen AI, RAG e Inferencia ML: Perfecto para industrias como biotecnología, medios, entretenimiento y finanzas que necesitan IA confiable y escalable para preparación de datos, ajuste fino o procesamiento en tiempo real.
Investigadores e Ingenieros ML: Accede a modelos de código abierto de primer nivel con calidad verificada, soportando tareas en razonamiento, codificación, matemáticas y aplicaciones multilingües. Programas como Research Cloud Credits agregan valor para pursuits académicos.
Equipos Buscando Eficiencia de Costos: Negocios cansados de APIs propietarias costosas apreciarán los ahorros de 3x en tokens y precios flexibles, especialmente para escenarios contextuales.
Si estás lidiando con cargas de trabajo de producción, el servicio confirma que está construido para ellas, con opciones para modelos personalizados vía formularios de solicitud e instancias dedicadas.
¿Por qué Elegir Nebius AI Studio Sobre Competidores?
En un panorama de IA abarrotado, Nebius se diferencia a través de su enfoque en la excelencia de código abierto. A diferencia de APIs propietarias que te atan a ecosistemas de proveedores, Nebius ofrece libertad con modelos bajo licencias como Apache 2.0, MIT y términos específicos de Llama: todo mientras iguala o supera el rendimiento. Los usuarios ahorran en costos sin sacrificar velocidad o precisión, como lo evidencian benchmarks: tiempo más rápido hasta el primer token en Europa y calidad comparable a GPT-4o.
El compromiso con la comunidad vía X/Twitter, LinkedIn y Discord proporciona actualizaciones, soporte técnico y discusiones, fomentando un entorno colaborativo. Para usuarios conscientes de la seguridad, el alojamiento europeo asegura cumplimiento, y el servicio evita el seguimiento innecesario de datos.
Cómo Comenzar con Nebius AI Studio
Ponerte al día es rápido:
- Regístrate: Crea una cuenta y reclama $1 en créditos gratuitos.
- Explora el Playground: Prueba modelos interactivamente vía la UI web.
- Integra vía API: Usa el endpoint compatible con OpenAI con tu clave API.
- Escala y Optimiza: Elige variantes, solicita modelos o contacta ventas para necesidades empresariales.
- Monitorea y Ajusta: Rastrea el uso para mantenerte dentro del presupuesto, con opciones para recursos dedicados.
Para solicitudes personalizadas, inicia sesión y usa el formulario para sugerir modelos de código abierto adicionales. Los detalles de precios son transparentes: verifica la página de precios de AI Studio para costos de endpoints basados en velocidad vs. economía.
Casos de Uso del Mundo Real y Valor Práctico
Nebius AI Studio impulsa aplicaciones diversas:
Sistemas RAG: Manejo económico de tokens para consultas aumentadas por recuperación en búsqueda o bases de conocimiento.
Chatbots y Asistentes: Respuestas de baja latencia para servicio al cliente o agentes virtuales.
Generación de Código y Solvers Matemáticos: Aprovecha modelos como DeepSeek-R1 o Mixtral para herramientas de desarrolladores.
Creación de Contenido: Soporte multilingüe en modelos Mistral para aplicaciones globales.
El valor práctico radica en su equilibrio de rendimiento y asequibilidad, habilitando innovación más rápida. Los usuarios reportan escalado fluido y salidas confiables, reduciendo tiempo y costos de desarrollo. Por ejemplo, en medios y entretenimiento, acelera servicios Gen AI; en biotecnología, soporta análisis de datos sin sobrecarga MLOps.
En resumen, el Servicio de Inferencia de Nebius AI Studio es el referente para cualquiera que busque inferencia de IA de código abierto de alto rendimiento. Empodera a los usuarios para construir aplicaciones más inteligentes con facilidad, entregando ROI real a través de eficiencia y escalabilidad. Cambia a Nebius hoy y experimenta la diferencia en velocidad, ahorros y simplicidad.
Mejores herramientas alternativas a "Nebius AI Studio Inference Service"

Etiquetas Relacionadas con Nebius AI Studio Inference Service