Stable Diffusion
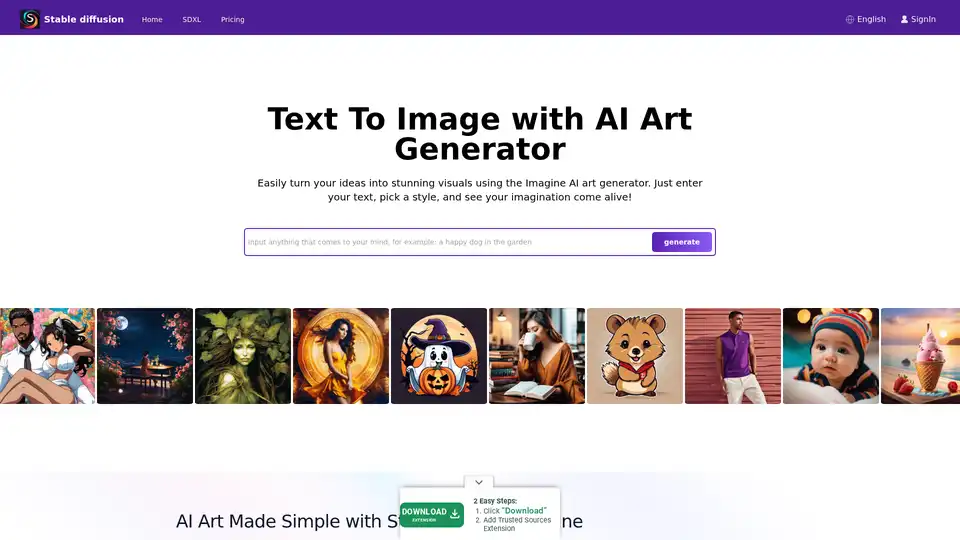
Descripción general de Stable Diffusion
¿Qué es Stable Diffusion AI?
Stable Diffusion es un innovador sistema de IA de código abierto que transforma descripciones de texto en imágenes impresionantes y realistas. Desarrollado por el grupo CompVis de la Universidad Ludwig Maximilian de Múnich, en colaboración con Runway ML y Stability AI, aprovecha modelos de difusión para habilitar la generación de imágenes a partir de texto, edición de imágenes y más. A diferencia de herramientas propietarias, el código, los modelos preentrenados y la licencia de Stable Diffusion son completamente de código abierto, lo que permite a los usuarios ejecutarlo en una sola GPU directamente en sus dispositivos. Esta accesibilidad ha democratizado la creatividad impulsada por IA, haciendo que la generación de imágenes de alta calidad esté disponible para artistas, diseñadores y aficionados sin necesidad de recursos a nivel empresarial.
En su núcleo, Stable Diffusion destaca en la producción de visuales detallados a partir de indicaciones simples, soportando resoluciones de hasta 1024x1024 píxeles. Es particularmente notable por su versatilidad en la generación de paisajes, retratos, arte abstracto e incluso diseños conceptuales. Para aquellos que se adentran en el arte de IA, Stable Diffusion se destaca como un punto de entrada confiable, ofreciendo libertad creativa mientras se es consciente del uso ético para evitar sesgos de sus datos de entrenamiento.
¿Cómo funciona Stable Diffusion?
Stable Diffusion opera en una arquitectura de Modelo de Difusión Latente (LDM), que comprime y procesa imágenes de manera eficiente en un espacio latente en lugar de en el espacio completo de píxeles, reduciendo las demandas computacionales. El sistema consta de tres componentes clave:
- Variational Autoencoder (VAE): Esto comprime las imágenes de entrada en una representación latente compacta, preservando detalles semánticos esenciales mientras descarta el ruido.
- U-Net: El núcleo de desruido, construido sobre una estructura ResNet, elimina iterativamente el ruido gaussiano agregado durante el proceso de difusión hacia adelante. Utiliza mecanismos de atención cruzada para incorporar indicaciones de texto, guiando la generación hacia las salidas descritas por el usuario.
- Text Encoder (Optional): Convierte descripciones textuales en embeddings que influyen en los pasos de desruido.
El proceso comienza agregando ruido a una imagen latente (o comenzando desde ruido puro para la generación). La U-Net luego invierte este proceso de difusión paso a paso, refinando la salida hasta que emerge una imagen coherente. Una vez desruido, el decodificador VAE reconstruye la imagen final basada en píxeles. Este flujo de trabajo elegante asegura resultados de alta fidelidad, incluso para indicaciones complejas que involucran estilos, composiciones o sujetos.
Entrenado en el masivo conjunto de datos LAION-5B —que comprende miles de millones de pares de imagen-texto de fuentes web— permite a Stable Diffusion aprender conceptos visuales diversos. Los datos se filtran por calidad, resolución y estética, con técnicas como Classifier-Free Guidance que mejoran la adherencia a las indicaciones. Sin embargo, estos datos de origen web introducen sesgos culturales, principalmente hacia el inglés y el contenido occidental, que los usuarios deben considerar al generar representaciones diversas.
Características y Capacidades Principales de Stable Diffusion
Stable Diffusion no se trata solo de la creación básica de imágenes; ofrece una suite de funciones avanzadas:
- Generación de Imágenes a partir de Texto: Ingresa una indicación descriptiva como "un paisaje sereno de montaña al atardecer" y genera arte original en segundos.
- Herramientas de Edición de Imágenes: Usa inpainting para rellenar o modificar partes de una imagen (por ejemplo, cambiar fondos) y outpainting para expandir más allá de los bordes originales.
- Traducción de Imagen a Imagen: Redibuja fotos existentes con nueva orientación textual, preservando la estructura mientras altera estilos o elementos.
- Integración de ControlNet: Mantiene estructuras geométricas, poses o bordes de imágenes de referencia mientras aplica cambios estilísticos.
- Soporte de Alta Resolución: La variante XL (Stable Diffusion XL 1.0) impulsa las capacidades con un modelo dual de 6 mil millones de parámetros, habilitando salidas de 1024x1024, mejor renderizado de texto en imágenes y simplificación de indicaciones para resultados más rápidos y realistas.
Mejoras como LoRAs (Adaptaciones de Bajo Rango) permiten el ajuste fino para detalles específicos —como rostros, ropa o estilos anime— sin reentrenar todo el modelo. Los embeddings capturan estilos visuales para salidas consistentes, mientras que las indicaciones negativas excluyen elementos no deseados como distorsiones o extremidades extra, refinando la calidad.
Cómo Usar Stable Diffusion AI
Comenzar con Stable Diffusion es sencillo, ya sea en línea o sin conexión.
Acceso en Línea a Través de Plataformas
Para principiantes, plataformas como Stablediffusionai.ai proporcionan una interfaz web amigable para el usuario:
- Visita stablediffusionai.ai e inicia sesión.
- Ingresa tu indicación de texto en el campo de entrada.
- Selecciona estilos, resoluciones (por ejemplo, SDXL para alta resolución) y ajusta parámetros como pasos de muestreo.
- Haz clic en "Generate" o "Dream" para crear imágenes.
- Refina con indicaciones negativas (por ejemplo, "borroso, baja calidad") y descarga favoritos.
Esta opción sin instalación es ideal para experimentos rápidos, aunque requiere internet.
Instalación Local y Descarga
Para control total y uso sin conexión:
- Descarga desde GitHub (github.com/CompVis/stable-diffusion) haciendo clic en "Code" > "Download ZIP" (necesita ~10GB de espacio).
- Instala prerrequisitos: Python 3.10+, Git y una GPU con 4GB+ VRAM (NVIDIA recomendado).
- Extrae el ZIP, coloca los checkpoints del modelo (por ejemplo, de Hugging Face) en la carpeta de modelos.
- Ejecuta webui-user.bat (Windows) o script equivalente para lanzar la UI local.
- Ingresa indicaciones, ajusta configuraciones como pasos de inferencia (20-50 para equilibrio) y genera.
Extensiones como la web UI de Automatic1111 agregan funciones como procesamiento por lotes. Una vez configurado, se ejecuta completamente sin conexión, priorizando la privacidad.
Entrenar Tu Propio Modelo de Stable Diffusion
Usuarios avanzados pueden personalizar Stable Diffusion:
- Reúne un conjunto de datos de pares imagen-texto (por ejemplo, para estilos nicho).
- Prepara datos limpiando y captionando.
- Modifica configs para tu conjunto de datos e hiperparámetros (tamaño de lote, tasa de aprendizaje).
- Entrena componentes por separado (VAE, U-Net, codificador de texto) usando scripts —alquila GPUs en la nube para tareas pesadas.
- Evalúa y ajusta finamente de manera iterativa.
Este proceso exige conocimientos técnicos, pero desbloquea modelos adaptados para dominios específicos como moda o arquitectura.
Stable Diffusion XL: La Versión Mejorada
Lanzado en julio de 2023 por Stability AI, SDXL se basa en el original con un conteo de parámetros mayor para detalles superiores. Simplifica las indicaciones (menos palabras necesarias), incluye estilos integrados y destaca en texto legible dentro de imágenes. Para profesionales, SDXL Online a través de plataformas dedicadas entrega salidas de ultra alta resolución para visuales de marketing, activos de juegos o impresiones. Es un paso adelante para aquellos que buscan fotorealismo o diseños intrincados sin comprometer la velocidad.
Usar LoRAs, Embeddings e Indicaciones Negativas
- LoRAs: Descarga archivos especializados (por ejemplo, para retratos) y actívalos vía indicaciones como "lora:portrait_style:1.0". Mejoran detalles de manera eficiente.
- Embeddings: Entrena en conjuntos de datos de estilos, luego invócalos con ":style_name:" en indicaciones para consistencia temática.
- Indicaciones Negativas: Especifica evita como "deformed, ugly" para minimizar fallos, mejorando la precisión general de la salida.
Aplicaciones Prácticas y Casos de Uso
Stable Diffusion brilla en varios escenarios:
- Artistas y Diseñadores: Prototipa conceptos, genera referencias o experimenta con estilos para arte digital, ilustraciones o mockups de UI/UX.
- Marketing y Medios: Crea visuales personalizados para anuncios, redes sociales o contenido sin fotos de stock —ideal para renders de productos de e-commerce.
- Educación y Aficionados: Enseña conceptos de IA o crea arte personalizado como hobby, como retratos familiares en entornos de fantasía.
- Desarrollo de Juegos: Creación de activos para personajes, entornos o texturas, especialmente con ControlNet para control de poses.
Su capacidad sin conexión se adapta a creadores remotos, mientras que el acceso API (vía Dream Studio o Hugging Face) se integra en flujos de trabajo.
¿Para quién es Stable Diffusion?
Esta herramienta apunta a profesionales creativos, desde artistas digitales novatos hasta desarrolladores experimentados. Los principiantes aprecian las interfaces intuitivas, mientras que los expertos valoran opciones de personalización como ajuste fino. Es perfecta para aquellos que priorizan la ética de código abierto y privacidad local sobre dependencias en la nube. Sin embargo, es menos adecuada para tareas no creativas o usuarios sin configuración técnica básica.
Limitaciones y Mejores Prácticas
A pesar de sus fortalezas, Stable Diffusion tiene obstáculos:
- Sesgos: Las salidas pueden favorecer estéticas occidentales; indicaciones diversas y ajuste fino ayudan a mitigar.
- Desafíos Anatómicos: Manos y rostros pueden distorsionarse —usa indicaciones negativas o LoRAs.
- Necesidades de Recursos: Ejecuciones locales requieren hardware decente; alternativas en la nube como Stablediffusionai.ai cierran brechas.
Siempre revisa por cuestiones éticas, como derechos de autor en datos de entrenamiento. Comunidades en Civitai o Reddit ofrecen modelos y consejos para superar fallos.
¿Por qué Elegir Stable Diffusion?
En un panorama de IA abarrotado, la naturaleza de código abierto de Stable Diffusion fomenta la innovación, con actualizaciones constantes de la comunidad. Comparado con herramientas cerradas como DALL-E, ofrece generaciones ilimitadas sin cuotas y propiedad total de las salidas. Para necesidades de alta resolución, SDXL entrega calidad a nivel profesional de manera asequible. Ya sea para generar ideas o finalizar proyectos, empodera a los usuarios para combinar ingenio humano con eficiencia de IA.
Precios y Acceso
El núcleo de Stable Diffusion es gratuito para descargar y usar. Plataformas como Stablediffusionai.ai pueden ofrecer niveles gratuitos con actualizaciones pagadas para generaciones más rápidas o funciones avanzadas. Los créditos API de Dream Studio comienzan bajos, escalando para uso intensivo. Configuraciones locales eliminan costos continuos, haciéndolo viable económicamente para creatividad sostenida.
En esencia, Stable Diffusion redefine la generación de arte de IA poniendo el poder en manos de los usuarios. Sumérgete en su ecosistema vía GitHub o demos en línea, y desbloquea posibilidades infinitas para narración visual.
Etiquetas Relacionadas con Stable Diffusion
