ExLlama の概要
ExLlama: 量子化された重みに対するメモリ効率の高い Llama 実装
ExLlamaは、最新の GPU で 4 ビット GPTQ の重みを使用する際の速度とメモリ効率のために設計された、Llama のスタンドアロンの Python/C++/CUDA 実装です。このプロジェクトは、特に量子化されたモデルを扱うユーザー向けに、Hugging Face Transformers の実装よりも高速でメモリ効率の高い代替手段を提供することを目的としています。
ExLlama とは?
ExLlama は、Llama ファミリーの言語モデル向けの高性能推論エンジンとして設計されています。GPU アクセラレーションに CUDA を活用し、4 ビット GPTQ 量子化された重みに最適化されており、ユーザーは限られたメモリの GPU 上で大規模言語モデルを実行できます。
ExLlama の仕組み
ExLlama は、いくつかの手法を通じてメモリ使用量と推論速度を最適化します。
- CUDA 実装: 効率的な GPU 計算のために CUDA を利用します。
- 量子化サポート: 特に 4 ビット GPTQ 量子化された重み用に設計されています。
- メモリ効率: 標準的な実装と比較して、メモリフットプリントを削減します。
主な機能と利点:
- 高性能: 高速な推論に最適化されています。
- メモリ効率: より低スペックの GPU で大規模モデルを実行できます。
- スタンドアロン実装: Hugging Face Transformers ライブラリは不要です。
- Web UI: モデルとの簡単なインタラクションのためのシンプルな Web UI が含まれています (JavaScript は ChatGPT によって書かれているため、注意してください!)。
- Docker サポート: より簡単なデプロイとセキュリティのために、Docker コンテナで実行できます。
ExLlama の使い方
インストール:
- リポジトリをクローンします:
git clone https://github.com/turboderp/exllama - ディレクトリに移動します:
cd exllama - 依存関係をインストールします:
pip install -r requirements.txt
- リポジトリをクローンします:
ベンチマークの実行:
python test_benchmark_inference.py -d <path_to_model_files> -p -ppl
チャットボットの例の実行:
python example_chatbot.py -d <path_to_model_files> -un "Jeff" -p prompt_chatbort.txt
Web UI:
- 追加の依存関係をインストールします:
pip install -r requirements-web.txt - Web UI を実行します:
python webui/app.py -d <path_to_model_files>
- 追加の依存関係をインストールします:
ExLlama を選ぶ理由
ExLlama には、いくつかの利点があります。
- パフォーマンス: 他の実装と比較して、より高速な推論速度を実現します。
- アクセシビリティ: GPU メモリが限られているユーザーでも、大規模言語モデルを実行できます。
- 柔軟性: Python モジュールを介して他のプロジェクトに統合できます。
- 使いやすさ: モデルと対話するためのシンプルな Web UI を提供します。
ExLlama は誰のためのものか
ExLlama は、以下のようなユーザーに適しています。
- 大規模言語モデルを扱う研究者および開発者。
- NVIDIA GPU を使用するユーザー (30 シリーズ以降を推奨)。
- メモリ効率が高く、高性能な推論ソリューションを求めているユーザー。
- 4 ビット GPTQ 量子化で Llama モデルを実行することに関心のある人。
ハードウェア要件:
- NVIDIA GPU (RTX 30 シリーズ以降を推奨)
- ROCm サポートは理論上は可能ですが、テストされていません
依存関係:
- Python 3.9+
- CUDA 11.8 を搭載した PyTorch (2.0.1 および 2.1.0 nightly でテスト済み)
- safetensors 0.3.2
- sentencepiece
- ninja
- flask と waitress (Web UI 用)
Docker サポート:
ExLlama は、より簡単なデプロイとセキュリティのために、Docker コンテナで実行できます。Docker イメージは NVIDIA GPU をサポートしています。
結果とベンチマーク:
ExLlama は、特に推論中の 1 秒あたりのトークン数 (t/s) の点で、他の実装と比較して大幅なパフォーマンスの向上を示しています。さまざまな GPU 構成で、さまざまな Llama モデルサイズ (7B、13B、33B、65B、70B) のベンチマークが提供されています。
使用例
import torch
from exllama.model import ExLlama, ExLlamaCache, ExLlamaConfig
from exllama.tokenizer import ExLlamaTokenizer
## モデルとトークナイザーを初期化します
model_directory = "/path/to/your/model"
tokenizer_path = os.path.join(model_directory, "tokenizer.model")
model_config_path = os.path.join(model_directory, "config.json")
config = ExLlamaConfig(model_config_path)
config.model_path = os.path.join(model_directory, "model.safetensors")
tokenizer = ExLlamaTokenizer(tokenizer_path)
model = ExLlama(config)
cache = ExLlamaCache(model)
## 入力を準備します
prompt = "The quick brown fox jumps over the lazy"
input_ids = tokenizer.encode(prompt)
## 出力を生成します
model.forward(input_ids, cache)
token = model.sample(temperature = 0.7, top_k = 50, top_p = 0.7)
output = tokenizer.decode([token])
print(prompt + output)
互換性とモデルのサポート:
ExLlama は、Llama 1 や Llama 2 など、さまざまな Llama モデルと互換性があります。このプロジェクトは、新しいモデルと機能をサポートするために継続的に更新されています。
ExLlama は、Llama モデルを効率的に実行したいと考えている人にとって強力なツールです。メモリの最適化と速度に重点を置いているため、研究と実用的なアプリケーションの両方にとって優れた選択肢となります。
"ExLlama" のベストな代替ツール

vLLMは、LLM のための高スループットかつメモリ効率の良い推論およびサービングエンジンであり、最適化されたパフォーマンスのためにPagedAttentionと継続的なバッチ処理を備えています。
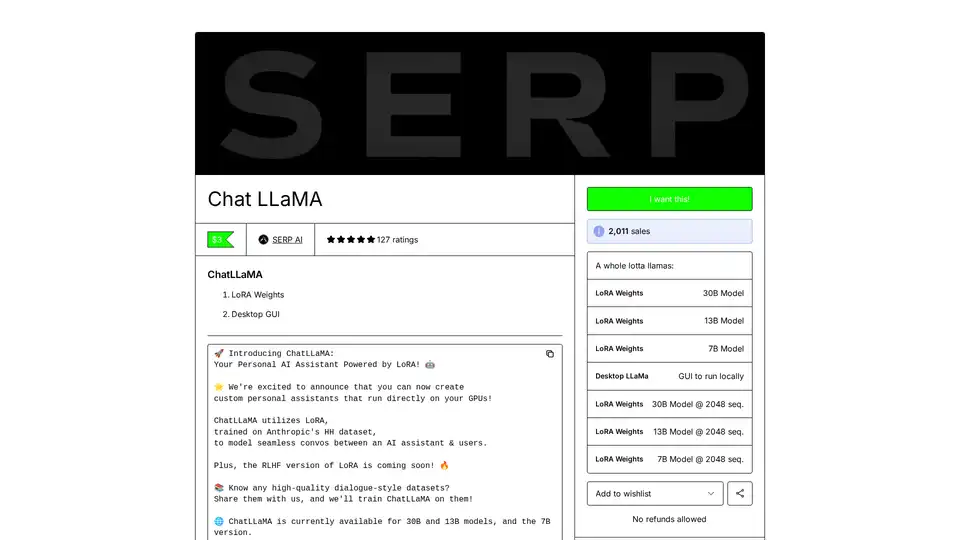
ChatLLaMA は LLaMA モデルに基づく LoRA 訓練 AI アシスタントで、ローカル GPU でカスタム個人会話が可能。デスクトップ GUI を備え、Anthropic の HH データセットで訓練、7B、13B、30B モデル対応。
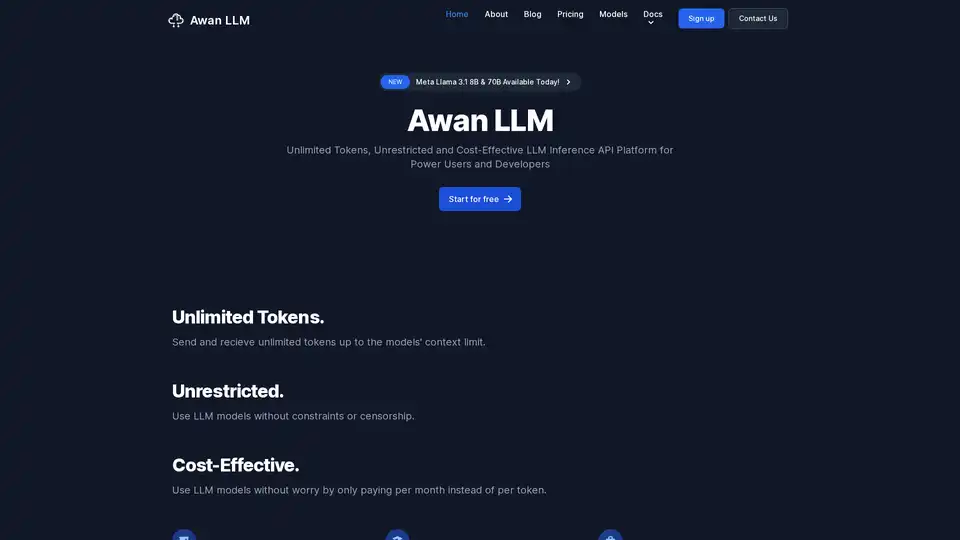
Awan LLM は、無制限、無制限、費用対効果の高い LLM 推論 API プラットフォームを提供します。ユーザーと開発者は、トークンの制限なしに強力な LLM モデルにアクセスでき、AI エージェント、ロールプレイ、データ処理、コード補完に最適です。

llama.cpp を使用して効率的な LLM 推論を有効にします。これは、多様なハードウェア向けに最適化された C/C++ ライブラリで、量子化、CUDA、GGUF モデルをサポートしています。 ローカルおよびクラウド展開に最適です。