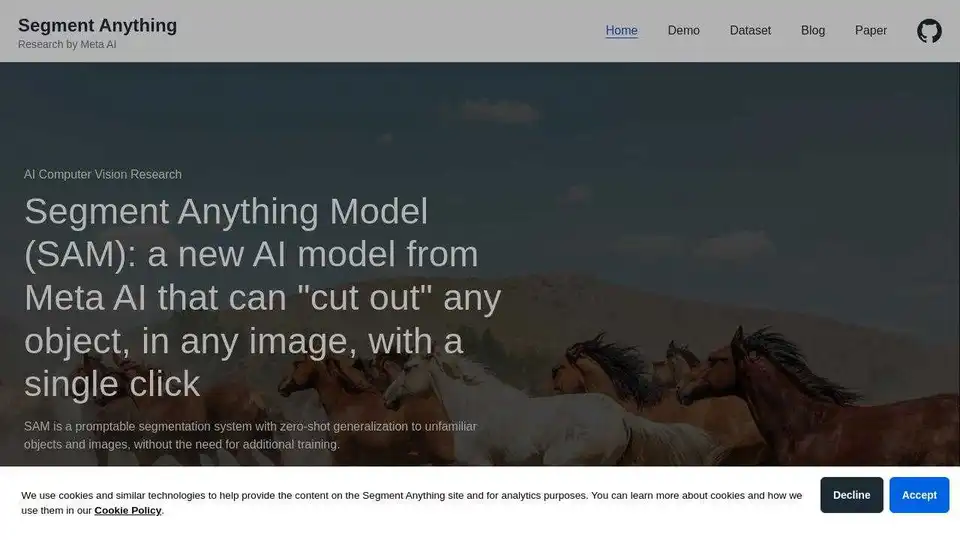
Segment Anything Model (SAM) の概要
Segment Anything Model (SAM):AIによる画像セグメンテーションの革新
**Segment Anything Model (SAM)**とは何ですか?Meta AIによって開発された最先端のAIモデルであり、比類のない容易さと柔軟性で画像セグメンテーションを実行するように設計されています。シングルクリックのようなプロンプトを使用して、画像内の任意のオブジェクトを「切り取る」ことができ、インタラクティブでユーザーフレンドリーです。
Segment Anything Model (SAM)の仕組み
SAMは、プロンプト可能なセグメンテーションシステムとして動作します。つまり、追加のトレーニングを必要とせずに、さまざまな入力プロンプトに基づいて画像をセグメント化できます。この機能は、ゼロショット汎化と呼ばれます。このモデルは、オブジェクトを構成する一般的な概念を学習しており、見慣れないオブジェクトや画像を効果的に処理できます。
主な機能は次のとおりです:
- インタラクティブなプロンプト:ポイント、ボックス、またはマスクを使用して、セグメント化するものを指定します。
- 自動セグメンテーション:画像内のすべてを自動的にセグメント化します。
- 曖昧さの処理:曖昧なプロンプトに対して複数の有効なマスクを生成します。
- 拡張可能な出力:出力マスクは、他のAIシステムの入力として使用できます。
- ゼロショット汎化:モデルの事前トレーニングされた理解により、再トレーニングなしで新しいオブジェクトや画像に汎化できます。
Segment Anything Model (SAM)が重要な理由
SAMは、コンピュータビジョンの大きな進歩を表しており、画像セグメンテーションにおいて汎用性と効率性を提供します。プロンプト可能な設計により、他のシステムとの統合が容易になり、革新的なアプリケーションへの道が開かれます。また、コンピュータビジョンタスクで通常必要な注釈作業も大幅に削減されます。
Segment Anything Model (SAM)の使い方
- プロンプトの提供:前景/背景ポイント、境界ボックス、マスクなどのプロンプトを入力します。
- 推論の実行:イメージエンコーダーは、イメージを処理してイメージ埋め込みを作成します。
- マスクのデコード:プロンプトエンコーダーとマスクデコーダーは、イメージとプロンプトの埋め込みからオブジェクトマスクを生成します。
Segment Anything Model (SAM)は誰のためのものですか?
SAMは、次のような幅広いユーザーにとって価値があります:
- AI研究者:コンピュータビジョンの新しい可能性を探求します。
- アプリケーション開発者:柔軟なセグメンテーション機能をアプリケーションに統合します。
- データサイエンティスト:画像注釈プロセスを簡素化および高速化します。
- クリエイティブプロフェッショナル:セグメント化されたオブジェクトをイメージング編集、コラージュ、3Dモデリングに使用します。
SAMのデータエンジン:秘伝のソース
SAMの機能は、モデルインザループ「データエンジン」を使用して収集された数百万の画像とマスクでトレーニングした結果です。研究者は画像を繰り返し注釈付けし、モデルを更新することで、パフォーマンスとデータセットを大幅に向上させました。
効率的で柔軟なモデル設計
SAMは効率的に設計されています。モデルを次のように分離します:
- 1回限りのイメージエンコーダー。
- Webブラウザーで実行できる軽量マスクデコーダー。
この設計により、高速な推論が可能になり、SAMをさまざまなプラットフォームで利用できるようになります。
一般的な使用例:
- ビデオ内のオブジェクト追跡:ビデオフレーム間でセグメント化されたオブジェクトを追跡します。
- 画像編集アプリケーション:オブジェクトを分離して正確な編集を可能にします。
- 3Dモデリング:2Dマスクを3Dモデルにリフトします。
- クリエイティブタスク:セグメント化された要素を使用して、コラージュやその他の芸術的な構成を作成します。
よくある質問(FAQ)
- **どのような種類のプロンプトがサポートされていますか?**前景/背景ポイント、境界ボックス、およびマスクがサポートされています。テキストプロンプトは研究論文で検討されましたが、現在リリースされていません。
- **モデルの構造は何ですか?**ViT-Hイメージエンコーダー、プロンプトエンコーダー、および軽量のトランスフォーマーベースのマスクデコーダーを使用します。
- **モデルはどのプラットフォームを使用しますか?**イメージエンコーダーはGPUを備えたPyTorchで実行され、プロンプトエンコーダーとマスクデコーダーはONNXランタイムを使用してCPUまたはGPUで実行できます。
SAMを活用することで、ユーザーは画像セグメンテーションにおいて新たなレベルの精度と効率を実現し、さまざまな革新的なアプリケーションへの扉を開くことができます。SAMのユーザーフレンドリーで効率的な設計は、研究者、開発者、およびクリエイティブプロフェッショナルにとって変革的なツールとなります。
SAM:インスタンスセグメンテーションのためのジェネラリストモデル
Segment Anything Model(SAM)は、AI駆動の画像セグメンテーションにおける大きな飛躍を表しています。未見のデータに汎化し、多様なプロンプトを処理できる能力により、研究者、開発者、およびコンピュータビジョンタスクに取り組むすべての人にとって貴重なツールとなります。Meta AIがSAMの開発と改良を続けるにつれて、画像処理の分野に与える潜在的な影響は大きくなります。
"Segment Anything Model (SAM)" のベストな代替ツール
T-Rex Labelは、Grounding DINO、DINO-X、T-RexモデルをサポートするAI搭載のデータアノテーションツールです。 COCOおよびYOLOデータセットと互換性があり、効率的なコンピュータビジョンデータセット作成のために、バウンディングボックス、画像セグメンテーション、マスクアノテーションなどの機能を提供します。
RobovisionのAI駆動型コンピュータビジョンプラットフォームでインテリジェントオートメーションを発見。深層学習で視覚データを処理し、製造業や農業などの業界向けに効率的なモデル訓練とデプロイを可能にします。
AUTOMATIC1111 の Web UI を使用して Google Colab で Stable Diffusion を簡単に実行する方法を紹介します。モデル、LoRA、ControlNet をインストールして、ローカルハードウェアなしで高速 AI 画像生成を実現。
Averroes: 99%以上の精度とほぼゼロの誤検出を実現するAI visual inspection software。シームレスで自動化されたvisual inspectionおよびvirtual metrologyのためのノーコードプラットフォーム。
Ultralytics HUBを使用すると、ユーザーはノーコードプラットフォームでAIモデルを作成、トレーニング、デプロイできます。物体検出と画像セグメンテーションのためにUltralytics YOLOを使用してビジョンAIモデルをトレーニングします。
People For AIは、AIトレーニング用の高品質なデータラベリングおよびアノテーションサービスを提供しています。彼らは、コンピュータビジョンとNLPの専門知識を提供し、機械学習プロジェクトのための正確で信頼性の高いデータセットを保証します。
AI Superior は、ドイツを拠点とする AI サービス企業であり、AI 駆動型アプリケーションの開発とコンサルティングを専門としています。企業の競争力を強化するために、カスタム AI ソリューション、トレーニング、R&D を提供しています。

Meta AIのEmu Editは、指示に基づく編集に優れたマルチタスク画像編集モデルです。 領域ベースの編集、フリーフォーム編集、コンピュータビジョンなど、幅広いタスクでトレーニングされており、この分野で新たな標準を確立しています。
DataVLab を使用して、正確な画像アノテーションとデータラベリングで AI モデルを強化します。ヘルスケア、小売、モビリティ向けに高品質でスケーラブルなサービスを提供します。
Datatureは、企業や開発者向けにデータラベリング、モデルトレーニング、デプロイメントを加速するエンドツーエンドのビジョンAIプラットフォームです。本番環境対応のデータセットを10倍高速に構築し、ビジョンインテリジェンスをシームレスに統合します。
BasicAI は、AI/ML モデル向けのリーディングデータアノテーションプラットフォームとプロフェッショナルなラベリングサービスを提供し、AV、ADAS、智能都市アプリケーションで数千のユーザーに信頼されています。7年以上の専門知識により、高品質で効率的なデータソリューションを保証します。
Innovatiana は専門的なデータラベリングを提供し、ML、DL、LLM、VLM、RAG、RLHF 向けに高品質な AI データセットを構築し、倫理的で影響力のある AI ソリューションを保証します。
AI駆動のユーザーインタビューで定性研究を拡大。瞬時の洞察を得て、フィードバックを10倍速く分析。LinkedIn、Ford、Miroが信頼。無料トライアル。
Lensa は、AI 駆動のツールで写真を次のレベルに引き上げるオールインワン画像編集アプリです。人顔レタッチ、背景編集、クリエイティブフィルターに対応。日常のスナップショットを簡単に強化。