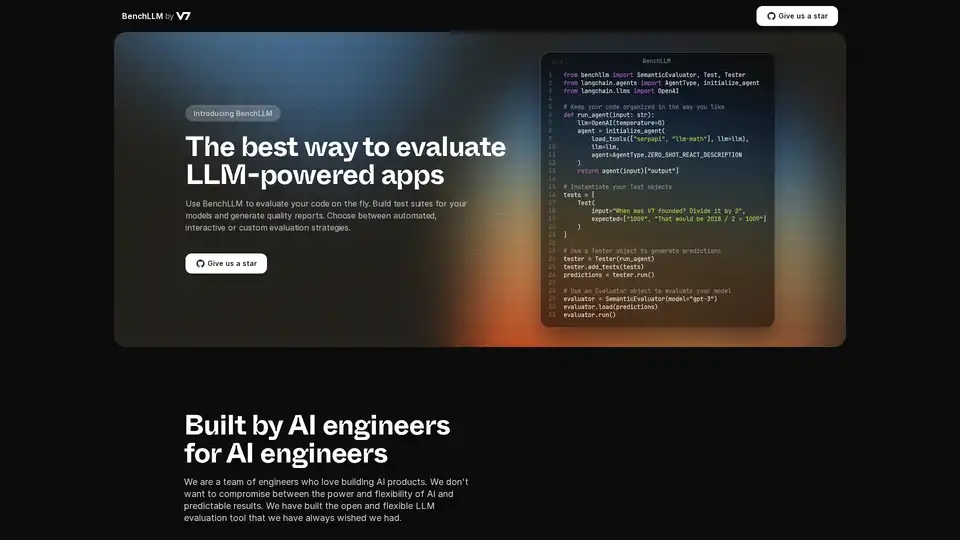
BenchLLM 개요
BenchLLM이란 무엇인가요?
BenchLLM은 대규모 언어 모델(LLM) 기반 애플리케이션의 성능과 품질을 평가하도록 설계된 도구입니다. 테스트 스위트 구축, 품질 보고서 생성 및 모델 성능 모니터링을 위한 유연하고 포괄적인 프레임워크를 제공합니다. 자동화된, 대화형 또는 사용자 지정 평가 전략이 필요한 경우에도 BenchLLM은 AI 모델이 필요한 표준을 충족하도록 보장하는 기능과 성능을 제공합니다.
BenchLLM은 어떻게 작동하나요?
BenchLLM은 사용자가 테스트를 정의하고, 해당 테스트에 대해 모델을 실행한 다음, 결과를 평가할 수 있도록 하여 작동합니다. 자세한 분석은 다음과 같습니다.
- 직관적으로 테스트 정의: 테스트는 JSON 또는 YAML 형식으로 정의할 수 있으므로 테스트 케이스를 쉽게 설정하고 관리할 수 있습니다.
- 테스트를 스위트로 구성: 쉬운 버전 관리 및 관리를 위해 테스트를 스위트로 구성합니다. 이는 모델이 발전함에 따라 다양한 버전의 테스트를 유지하는 데 도움이 됩니다.
- 테스트 실행: 강력한 CLI 또는 유연한 API를 사용하여 모델에 대해 테스트를 실행합니다. BenchLLM은 OpenAI, Langchain 및 기타 API를 즉시 지원합니다.
- 결과 평가: BenchLLM은 모델의 성능을 평가하기 위한 다양한 평가 전략을 제공합니다. 이는 프로덕션 환경에서 회귀를 식별하고 시간이 지남에 따라 모델 성능을 모니터링하는 데 도움이 됩니다.
- 보고서 생성: 평가 보고서를 생성하고 팀과 공유합니다. 이러한 보고서는 모델의 강점과 약점에 대한 통찰력을 제공합니다.
코드 스니펫 예시:
Langchain과 함께 BenchLLM을 사용하는 방법의 예는 다음과 같습니다.
from benchllm import SemanticEvaluator, Test, Tester
from langchain.agents import AgentType, initialize_agent
from langchain.llms import OpenAI
## Keep your code organized in the way you like
def run_agent(input: str):
llm=OpenAI(temperature=0)
agent = initialize_agent(
load_tools(["serpapi", "llm-math"], llm=llm),
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
return agent(input)["output"]
## Instantiate your Test objects
tests = [
Test(
input="When was V7 founded? Divide it by 2",
expected=["1009", "That would be 2018 / 2 = 1009"]
)
]
## Use a Tester object to generate predictions
tester = Tester(run_agent)
tester.add_tests(tests)
predictions = tester.run()
## Use an Evaluator object to evaluate your model
evaluator = SemanticEvaluator(model="gpt-3")
evaluator.load(predictions)
evaluator.run()
OpenAI의 ChatCompletion API와 함께 BenchLLM을 사용하는 방법의 예는 다음과 같습니다.
import benchllm
from benchllm.input_types import ChatInput
import openai
def chat(messages: ChatInput):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0].message.content.strip()
@benchllm.test(suite=".")
def run(input: ChatInput):
return chat(input)
주요 기능 및 이점
- 유연한 API: OpenAI, Langchain 및 기타 API에 대한 지원을 통해 즉석에서 코드를 테스트합니다.
- 강력한 CLI: 간단한 CLI 명령으로 모델을 실행하고 평가합니다. CI/CD 파이프라인에 이상적입니다.
- 쉬운 평가: JSON 또는 YAML 형식으로 직관적으로 테스트를 정의합니다.
- 자동화: 지속적인 품질을 보장하기 위해 CI/CD 파이프라인 내에서 평가를 자동화합니다.
- 통찰력 있는 보고서: 평가 보고서를 생성하고 공유하여 모델 성능을 모니터링합니다.
- 성능 모니터링: 모델 성능을 모니터링하여 프로덕션 환경에서 회귀를 감지합니다.
BenchLLM을 사용하는 방법
- 설치: BenchLLM을 다운로드하여 설치합니다.
- 테스트 정의: JSON 또는 YAML로 테스트 스위트를 만듭니다.
- 평가 실행: CLI 또는 API를 사용하여 LLM 애플리케이션에 대해 테스트를 실행합니다.
- 보고서 분석: 생성된 보고서를 검토하여 개선이 필요한 영역을 식별합니다.
BenchLLM은 누구를 위한 것인가요?
BenchLLM은 LLM 기반 애플리케이션의 품질과 안정성을 보장하려는 AI 엔지니어와 개발자를 위해 설계되었습니다. 특히 다음과 같은 경우에 유용합니다.
- AI 엔지니어: AI 제품을 구축하고 유지 관리하는 사람.
- 개발자: LLM을 애플리케이션에 통합합니다.
- 팀: AI 모델의 성능을 모니터링하고 개선하려는 사람.
BenchLLM을 선택하는 이유
BenchLLM은 LLM 애플리케이션을 평가하기 위한 포괄적인 솔루션을 제공하여 유연성, 자동화 및 통찰력 있는 보고를 제공합니다. 예측 가능한 결과를 제공하는 강력하고 유연한 도구가 필요한 AI 엔지니어가 구축했습니다. BenchLLM을 사용하면 다음을 수행할 수 있습니다.
- LLM 애플리케이션의 품질을 보장합니다.
- 평가 프로세스를 자동화합니다.
- 모델 성능을 모니터링하고 회귀를 감지합니다.
- 통찰력 있는 보고서로 협업을 개선합니다.
BenchLLM을 선택하면 AI 모델을 평가하고 최고의 성능과 품질 표준을 충족하는지 확인하기 위한 강력하고 안정적인 솔루션을 선택하는 것입니다.
"BenchLLM"의 최고의 대체 도구

Openlayer는 ML에서 LLM에 이르기까지 AI 시스템에 대한 통합 AI 평가, 관측 가능성 및 거버넌스를 제공하는 엔터프라이즈 AI 플랫폼입니다. AI 수명 주기 전반에 걸쳐 AI 시스템을 테스트, 모니터링 및 관리합니다.

Confident AI는 DeepEval 기반의 LLM 평가 플랫폼으로, 엔지니어링 팀이 LLM 애플리케이션 성능을 테스트, 벤치마킹, 보호 및 향상시킬 수 있도록 지원합니다. AI 시스템을 최적화하고 회귀를 포착하기 위한 최고의 지표, 보호 장치 및 관측성을 제공합니다.
UpTrain은 LLM 애플리케이션을 평가, 실험, 모니터링 및 테스트하기 위한 엔터프라이즈급 도구를 제공하는 풀 스택 LLMOps 플랫폼입니다. 자체 보안 클라우드 환경에서 호스팅하고 AI를 자신 있게 확장하십시오.
EvalMy.AI는 AI 응답 검증 및 RAG 평가를 자동화하여 LLM 테스트를 간소화합니다. 사용하기 쉬운 API로 정확성, 구성 가능성 및 확장성을 보장합니다.
GPT Driver는 모바일 앱을 위한 AI 네이티브 E2E 테스트 도구로, 불안정성과 유지 관리 노력을 줄입니다. 간단한 영어를 사용하여 테스트를 자동화하고 CI/CD에 통합하며 노코드 편집기로 테스트 범위를 늘립니다.
PromptPoint는 자동 프롬프트 테스트를 통해 프롬프트를 빠르고 쉽게 설계, 테스트 및 배포할 수 있도록 도와줍니다. 고품질 LLM 출력으로 팀의 프롬프트 엔지니어링 능력을 향상시키세요.
Freeplay는 프롬프트 관리, 평가, 관찰 가능성 및 데이터 검토 워크플로를 통해 팀이 AI 제품을 구축, 테스트 및 개선할 수 있도록 설계된 AI 플랫폼입니다. AI 개발을 간소화하고 고품질 제품을 보장합니다.
Code Fundi는 개발자와 팀이 소프트웨어를 더 빠르게 구축할 수 있도록 설계된 AI 기반 코딩 도우미입니다. AI 코드 생성, 디버깅, 문서화 및 실시간 모니터링과 같은 기능을 제공합니다.
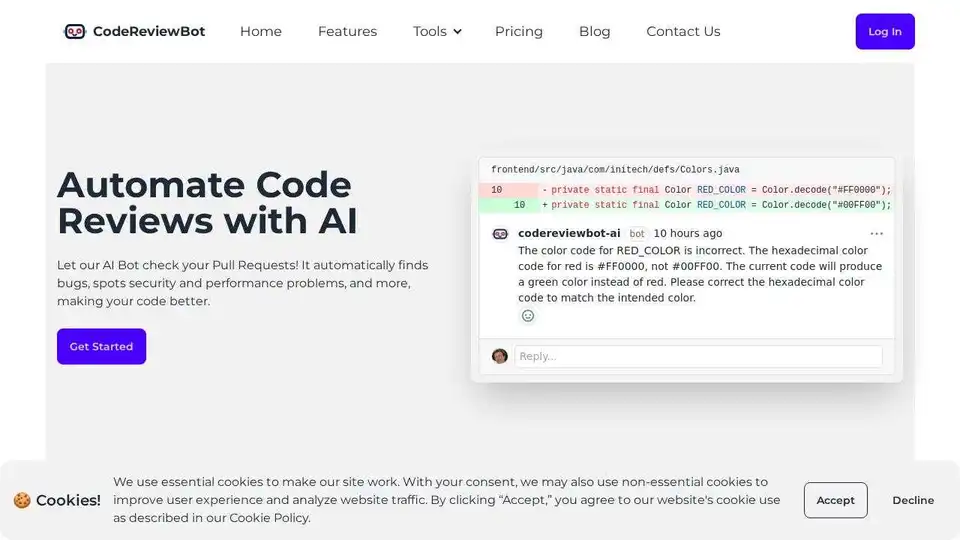
CodeReviewBot.ai는 GitHub pull requests와 통합되어 버그 감지, 보안 검사 및 성능 개선을 자동화하여 코딩 효율성을 향상시키는 AI 기반 코드 검토 서비스입니다.
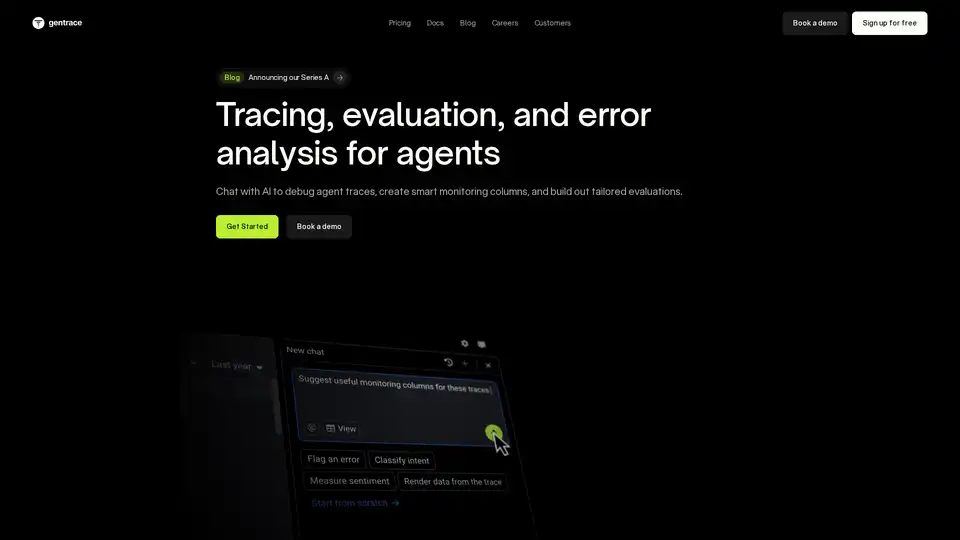
Gentrace는 AI 에이전트의 오류를 추적, 평가 및 분석하는 데 도움이 됩니다. AI와 채팅하여 추적을 디버깅하고, 평가를 자동화하고, 안정적인 성능을 위해 LLM 제품을 미세 조정하십시오. 오늘 무료로 시작하십시오!
Gru.ai는 코딩, 테스트, 디버깅을 위한 고급 AI 개발자 도구입니다. 단위 테스트 생성, 에이전트를 위한 Android 환경, gbox라는 오픈 소스 샌드박스 등의 기능을 제공하여 소프트웨어 개발 효율성을 높입니다.
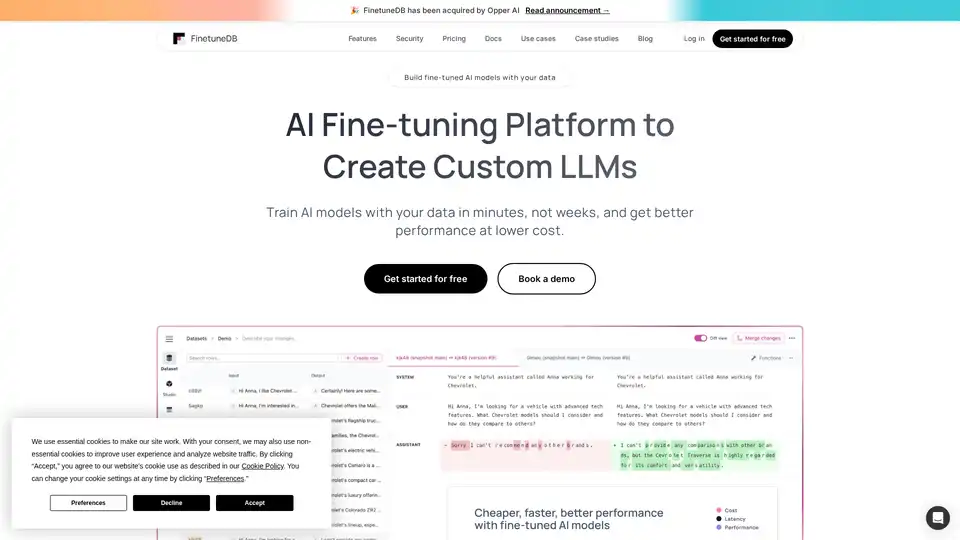
FinetuneDB는 데이터셋을 생성하고 관리하여 맞춤 LLM을 빠르고 저비용으로 훈련하는 AI 미세 조정 플랫폼으로, 생산 데이터와 협업 도구를 통해 모델 성능을 향상시킵니다.
Vivgrid는 개발자가 안전 장치 및 짧은 대기 시간 추론을 통해 AI 에이전트를 구축, 관찰, 평가 및 배포하는 데 도움이 되는 AI 에이전트 인프라 플랫폼입니다. GPT-5, Gemini 2.5 Pro 및 DeepSeek-V3를 지원합니다.