ExLlama 개요
ExLlama: 양자화된 가중치를 위한 메모리 효율적인 Llama 구현
ExLlama는 최신 GPU에서 4비트 GPTQ 가중치를 사용할 때 속도와 메모리 효율성을 위해 설계된 Llama의 독립 실행형 Python/C++/CUDA 구현입니다. 이 프로젝트는 특히 양자화된 모델을 사용하는 사용자를 위해 Hugging Face Transformers 구현보다 더 빠르고 메모리 효율적인 대안을 제공하는 것을 목표로 합니다.
ExLlama란 무엇입니까?
ExLlama는 Llama 제품군의 언어 모델을 위한 고성능 추론 엔진으로 설계되었습니다. GPU 가속을 위해 CUDA를 활용하고 4비트 GPTQ 양자화된 가중치에 최적화되어 사용자가 제한된 메모리의 GPU에서 대규모 언어 모델을 실행할 수 있습니다.
ExLlama는 어떻게 작동합니까?
ExLlama는 다음과 같은 여러 기술을 통해 메모리 사용량과 추론 속도를 최적화합니다.
- CUDA 구현: 효율적인 GPU 계산을 위해 CUDA를 활용합니다.
- 양자화 지원: 특히 4비트 GPTQ 양자화된 가중치용으로 설계되었습니다.
- 메모리 효율성: 표준 구현에 비해 메모리 공간을 줄입니다.
주요 기능 및 장점:
- 고성능: 빠른 추론에 최적화되었습니다.
- 메모리 효율성: 덜 강력한 GPU에서 대규모 모델을 실행할 수 있습니다.
- 독립 실행형 구현: Hugging Face Transformers 라이브러리가 필요하지 않습니다.
- 웹 UI: 모델과의 쉬운 상호 작용을 위한 간단한 웹 UI가 포함되어 있습니다 (JavaScript는 ChatGPT에서 작성했으므로 주의하십시오!).
- Docker 지원: 더 쉬운 배포 및 보안을 위해 Docker 컨테이너에서 실행할 수 있습니다.
ExLlama를 사용하는 방법
설치:
- 리포지토리 복제:
git clone https://github.com/turboderp/exllama - 디렉토리로 이동:
cd exllama - 종속성 설치:
pip install -r requirements.txt
- 리포지토리 복제:
벤치마크 실행:
python test_benchmark_inference.py -d <path_to_model_files> -p -ppl
챗봇 예제 실행:
python example_chatbot.py -d <path_to_model_files> -un "Jeff" -p prompt_chatbort.txt
웹 UI:
- 추가 종속성 설치:
pip install -r requirements-web.txt - 웹 UI 실행:
python webui/app.py -d <path_to_model_files>
- 추가 종속성 설치:
ExLlama를 선택하는 이유
ExLlama는 다음과 같은 여러 가지 장점을 제공합니다.
- 성능: 다른 구현에 비해 더 빠른 추론 속도를 제공합니다.
- 접근성: GPU 메모리가 제한된 사용자가 대규모 언어 모델을 실행할 수 있습니다.
- 유연성: Python 모듈을 통해 다른 프로젝트에 통합할 수 있습니다.
- 사용 용이성: 모델과 상호 작용하기 위한 간단한 웹 UI를 제공합니다.
ExLlama는 누구를 위한 것입니까?
ExLlama는 다음에 적합합니다.
- 대규모 언어 모델을 사용하는 연구원 및 개발자.
- NVIDIA GPU를 사용하는 사용자 (30 시리즈 이상 권장).
- 메모리 효율적이고 고성능 추론 솔루션을 찾는 사람.
- 4비트 GPTQ 양자화로 Llama 모델을 실행하는 데 관심이 있는 모든 사람.
하드웨어 요구 사항:
- NVIDIA GPU (RTX 30 시리즈 이상 권장)
- ROCm 지원은 이론적이지만 테스트되지 않았습니다.
종속성:
- Python 3.9+
- CUDA 11.8이 있는 PyTorch (2.0.1 및 2.1.0 nightly에서 테스트됨)
- safetensors 0.3.2
- sentencepiece
- ninja
- flask 및 waitress (웹 UI용)
Docker 지원:
ExLlama는 더 쉬운 배포 및 보안을 위해 Docker 컨테이너에서 실행할 수 있습니다. Docker 이미지는 NVIDIA GPU를 지원합니다.
결과 및 벤치마크:
ExLlama는 특히 추론 중 초당 토큰 수 (t/s) 측면에서 다른 구현에 비해 상당한 성능 향상을 보여줍니다. 다양한 GPU 구성에서 다양한 Llama 모델 크기 (7B, 13B, 33B, 65B, 70B)에 대한 벤치마크가 제공됩니다.
사용 예
import torch
from exllama.model import ExLlama, ExLlamaCache, ExLlamaConfig
from exllama.tokenizer import ExLlamaTokenizer
## 모델 및 토크나이저 초기화
model_directory = "/path/to/your/model"
tokenizer_path = os.path.join(model_directory, "tokenizer.model")
model_config_path = os.path.join(model_directory, "config.json")
config = ExLlamaConfig(model_config_path)
config.model_path = os.path.join(model_directory, "model.safetensors")
tokenizer = ExLlamaTokenizer(tokenizer_path)
model = ExLlama(config)
cache = ExLlamaCache(model)
## 입력 준비
prompt = "The quick brown fox jumps over the lazy"
input_ids = tokenizer.encode(prompt)
## 출력 생성
model.forward(input_ids, cache)
token = model.sample(temperature = 0.7, top_k = 50, top_p = 0.7)
output = tokenizer.decode([token])
print(prompt + output)
호환성 및 모델 지원:
ExLlama는 Llama 1 및 Llama 2를 포함한 다양한 Llama 모델과 호환됩니다. 이 프로젝트는 새로운 모델과 기능을 지원하기 위해 지속적으로 업데이트됩니다.
ExLlama는 Llama 모델을 효율적으로 실행하려는 모든 사람에게 강력한 도구입니다. 메모리 최적화 및 속도에 중점을 두어 연구 및 실제 응용 프로그램 모두에 탁월한 선택입니다.
"ExLlama"의 최고의 대체 도구

vLLM은 최적화된 성능을 위해 PagedAttention 및 지속적인 일괄 처리를 특징으로 하는 LLM을 위한 고처리량 및 메모리 효율적인 추론 및 서비스 엔진입니다.
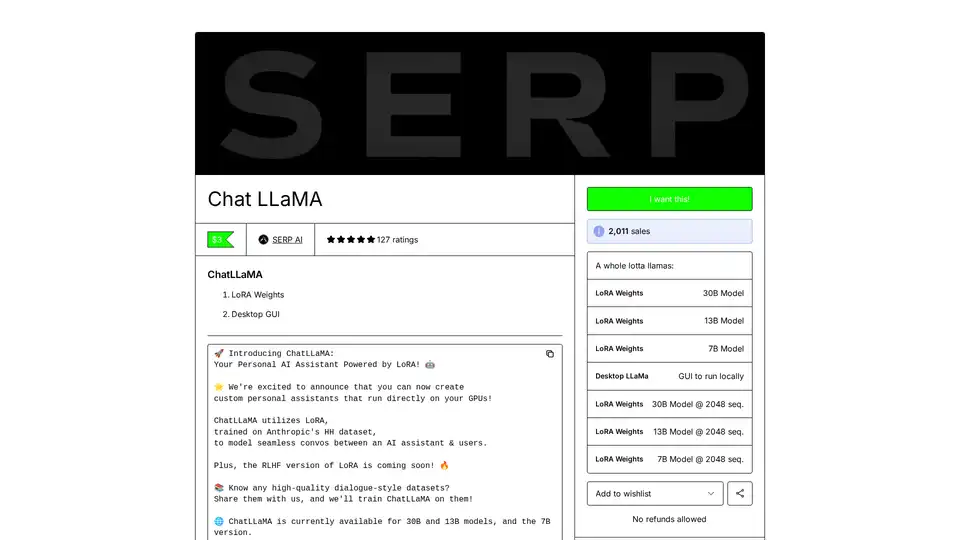
ChatLLaMA는 LLaMA 모델 기반 LoRA 훈련 AI 어시스턴트로, 로컬 GPU에서 사용자 지정 개인 대화를 가능하게 합니다. 데스크톱 GUI 제공, Anthropic의 HH 데이터셋으로 훈련, 7B, 13B, 30B 모델 지원.

다양한 하드웨어에 최적화된 C/C++ 라이브러리인 llama.cpp을 사용하여 효율적인 LLM 추론을 활성화하고 양자화, CUDA 및 GGUF 모델을 지원합니다. 로컬 및 클라우드 배포에 이상적입니다.
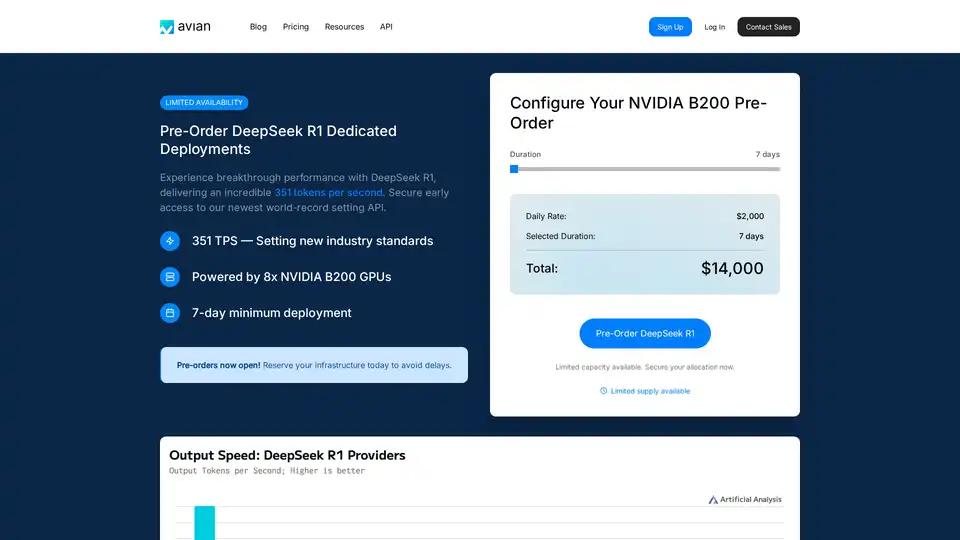
Avian API는 오픈 소스 LLM에 가장 빠른 AI 추론을 제공하여 DeepSeek R1에서 351 TPS를 달성합니다. OpenAI 호환 API를 사용하여 HuggingFace LLM을 3~10배 빠른 속도로 배포하십시오. 엔터프라이즈급 성능 및 개인 정보 보호.
서버를 설정하지 않고도 HuggingFace에서 Llama 모델을 즉시 실행할 수 있습니다. 11,900개 이상의 모델을 사용할 수 있습니다. 무제한 액세스에 월 $10부터 시작합니다.
Nebius AI Studio Inference Service는 호스팅된 오픈소스 모델을 제공하여 독점 API보다 더 빠르고 저렴하며 정확한 추론 결과를 제공합니다. MLOps 없이 원활하게 확장 가능하며, RAG 및 생산 워크로드에 이상적입니다。
Fireworks AI는 최첨단 오픈 소스 모델을 사용하여 생성적 AI를 위한 매우 빠른 추론을 제공합니다. 추가 비용 없이 자신의 모델을 미세 조정하고 배포하십시오. AI 워크로드를 전 세계적으로 확장하십시오.
FriendliAI는 AI 모델 배포를 위한 속도, 규모 및 안정성을 제공하는 AI 추론 플랫폼입니다. 459,400개 이상의 Hugging Face 모델을 지원하고 사용자 정의 최적화를 제공하며 99.99%의 가동 시간을 보장합니다.
Reflection 70B 온라인 체험: Llama 70B 기반 오픈 소스 LLM. 혁신적인 자체 수정 기능으로 GPT-4보다 뛰어난 성능을 제공합니다. 온라인 무료 평가판을 이용할 수 있습니다.
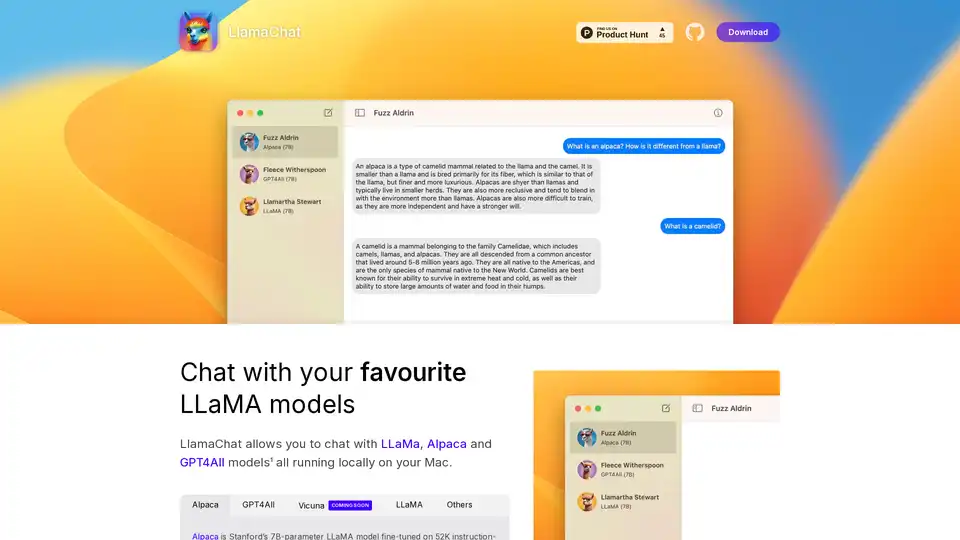
LlamaChat은 Mac에서 LLaMA, Alpaca 및 GPT4All 모델과 로컬로 채팅할 수 있는 macOS 앱입니다. 지금 다운로드하여 로컬 LLM 채팅을 경험해보세요!

Friendli Inference는 가장 빠른 LLM 추론 엔진으로, 속도와 비용 효율성을 위해 최적화되어 높은 처리량과 짧은 대기 시간을 제공하면서 GPU 비용을 50~90% 절감합니다.
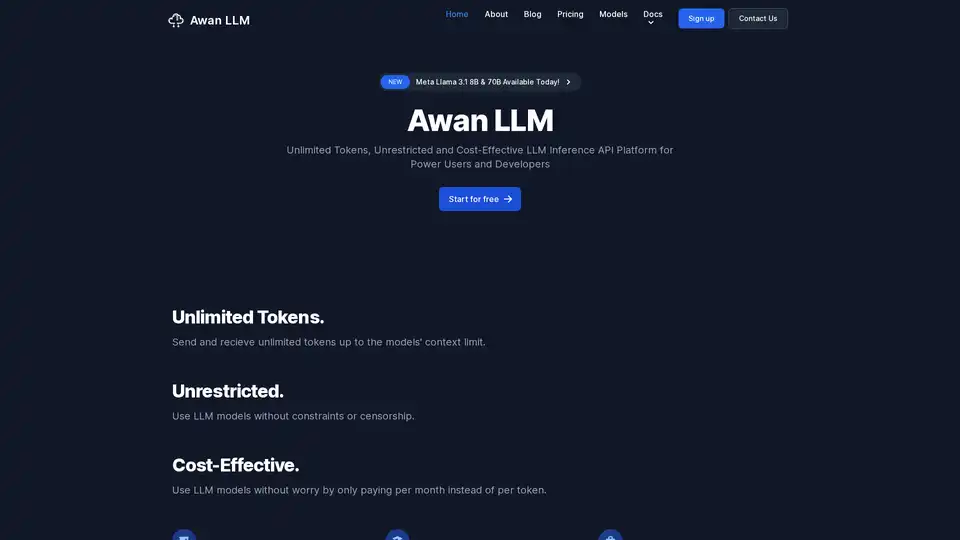
Awan LLM은 무제한, 무제한 및 비용 효율적인 LLM 추론 API 플랫폼을 제공합니다. 사용자와 개발자는 토큰 제한 없이 강력한 LLM 모델에 액세스할 수 있어 AI 에이전트, 역할극, 데이터 처리 및 코드 완성에 이상적입니다.

Unsloth AI는 gpt-oss 및 Llama와 같은 LLM에 대한 오픈 소스 미세 조정 및 강화 학습을 제공하여 30배 더 빠른 교육과 메모리 사용량 감소를 자랑하므로 AI 교육에 접근하고 효율적으로 사용할 수 있습니다.

Cloudflare Workers AI를 사용하면 Cloudflare의 글로벌 네트워크에서 사전 훈련된 머신러닝 모델에 대해 서버리스 AI 추론 작업을 실행할 수 있습니다. 다양한 모델을 제공하고 다른 Cloudflare 서비스와 원활하게 통합됩니다.