WebCrawler API
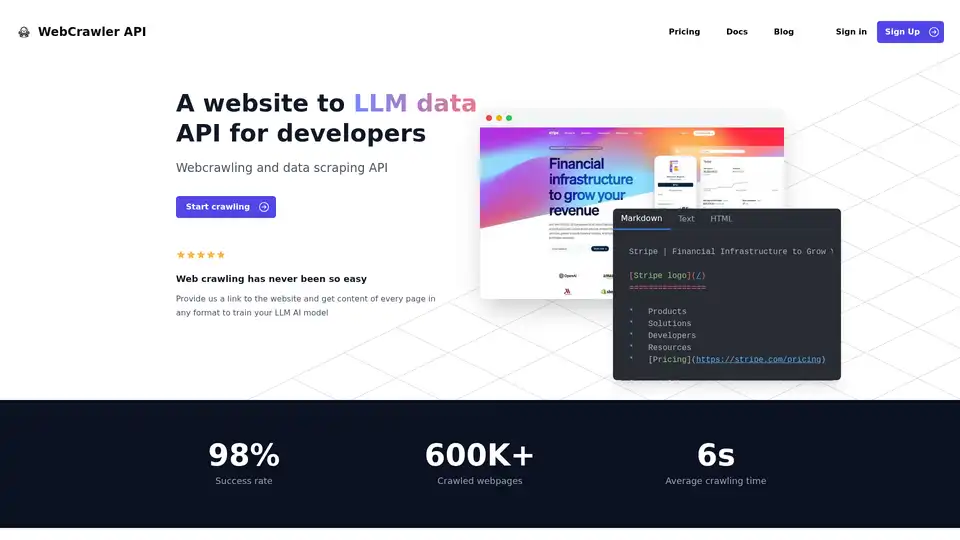
Visão geral de WebCrawler API
API WebCrawler: Rastreamento Web e Extração de Dados Sem Esforço para IA
O que é a API WebCrawler? É uma ferramenta poderosa projetada para simplificar o processo de extrair dados de websites, especificamente para treinar Modelos de Linguagem Grandes (LLMs) e outras aplicações de AI. Ela lida com as complexidades do rastreamento web, permitindo que você se concentre em utilizar os dados.
Principais Características:
- Fácil Integração: Integre a WebCrawlerAPI com apenas algumas linhas de código usando NodeJS, Python, PHP ou .NET.
- Formatos de Saída Versáteis: Receba conteúdo em formatos Markdown, Texto ou HTML, adaptados às suas necessidades.
- Alta Taxa de Sucesso: Com uma taxa de sucesso de 98%, a WebCrawlerAPI supera desafios comuns de rastreamento, como bloqueios anti-bot, CAPTCHAs e bloqueios de IP.
- Manipulação Abrangente de Links: Gerencia links internos, remove duplicatas e limpa URLs.
- Renderização JS: Emprega Puppeteer e Playwright de maneira estável para lidar com websites pesados em JavaScript.
- Infraestrutura Escalável: Gerencia e armazena de forma confiável milhões de páginas rastreadas.
- Limpeza Automática de Dados: Converte HTML em texto limpo ou Markdown usando regras de análise complexas.
- Gerenciamento de Proxy: Inclui uso ilimitado de proxy, para que você não precise se preocupar com restrições de IP.
Como funciona a API WebCrawler?
A API WebCrawler abstrai as dificuldades do rastreamento web, como:
- Manipulação de Links: Gerenciando links internos, removendo duplicatas e limpando URLs.
- Renderização JS: Renderizando websites pesados em JavaScript para extrair conteúdo dinâmico.
- Bloqueios Anti-Bot: Ignorando CAPTCHAs, bloqueios de IP e limites de taxa.
- Armazenamento: Gerenciando e armazenando grandes volumes de dados rastreados.
- Escalonamento: Lidando com múltiplos rastreadores em diferentes servidores.
- Limpeza de Dados: Convertendo HTML para texto limpo ou Markdown.
Ao lidar com essas complexidades subjacentes, a WebCrawlerAPI permite que você se concentre no que realmente importa – utilizar os dados extraídos para seus projetos de AI.
Como usar a API WebCrawler?
- Inscreva-se para uma conta e obtenha sua chave de acesso à API.
- Escolha sua linguagem de programação preferida: NodeJS, Python, PHP ou .NET.
- Integre o cliente WebCrawlerAPI em seu código.
- Especifique a URL de destino e o formato de saída desejado (Markdown, Texto ou HTML).
- Inicie o rastreamento e recupere o conteúdo extraído.
Exemplo usando NodeJS:
// npm i webcrawlerapi-js
import webcrawlerapi from "webcrawlerapi-js";
async function main() {
const client = new webcrawlerapi.WebcrawlerClient(
"YOUR API ACCESS KEY HERE",
)
const syncJob = await client.crawl({
"items_limit": 10,
"url": "https://stripe.com/",
"scrape_type": "markdown"
}
)
console.log(syncJob);
}
main().catch(console.error);
Por que escolher a API WebCrawler?
- Concentre-se em seu negócio principal: Evite gastar tempo e recursos no gerenciamento de uma infraestrutura complexa de rastreamento web.
- Acesse dados limpos e estruturados: Receba dados em seu formato preferido, prontos para treinamento de AI.
- Escale seus esforços de extração de dados: Lide com milhões de páginas sem se preocupar com limitações de infraestrutura.
- Preços econômicos: Pague apenas por solicitações bem-sucedidas, sem taxas de assinatura.
Para quem é a API WebCrawler?
A API WebCrawler é ideal para:
- Engenheiros de AI e Aprendizado de Máquina: Que precisam de grandes conjuntos de dados para treinar seus modelos.
- Cientistas de Dados: Que precisam extrair dados de websites para análise e pesquisa.
- Empresas: Que precisam monitorar concorrentes, rastrear tendências de mercado ou coletar informações sobre clientes.
Preços
A WebCrawlerAPI oferece preços simples, baseados no uso, sem taxas de assinatura. Você paga apenas por solicitações bem-sucedidas. Uma calculadora de custos está disponível para estimar seus gastos mensais com base no número de páginas que você planeja rastrear.
FAQ
- O que é WebcrawlerAPI? WebcrawlerAPI é uma API que permite extrair conteúdo de websites com uma alta taxa de sucesso, lidando com proxies, retries e navegadores headless.
- Posso rastrear apenas páginas específicas ou o website inteiro? Você pode especificar se deseja rastrear páginas específicas ou o website inteiro ao fazer uma solicitação.
- Posso usar dados rastreados em RAG ou treinar meu próprio modelo de AI? Sim, os dados rastreados podem ser usados em sistemas de Geração Aumentada por Recuperação (RAG) ou para treinar seus próprios modelos de AI.
- Preciso pagar uma assinatura para usar a WebcrawlerAPI? Não, não há taxas de assinatura. Você paga apenas por solicitações bem-sucedidas.
- Posso experimentar a WebcrawlerAPI antes de comprar? Entre em contato com eles para perguntar sobre as opções de teste.
- E se eu precisar de ajuda com a integração? O suporte por e-mail é fornecido.
Melhor maneira de extrair dados de websites para treinamento de AI com a WebCrawlerAPI
A WebCrawlerAPI fornece uma solução simplificada para extrair dados de websites, simplificando as complexidades do rastreamento web e permitindo que você se concentre no treinamento de modelos de AI e na análise de dados. Com sua alta taxa de sucesso, formatos de saída versáteis e recursos eficientes de limpeza de dados, ela capacita engenheiros de AI, cientistas de dados e empresas a coletar informações valiosas da web de forma eficaz.
Melhores ferramentas alternativas para "WebCrawler API"
Firecrawl é a API líder de rastreamento, raspagem e busca na web projetada para aplicativos de IA. Ela transforma sites em dados limpos, estruturados e prontos para LLM em escala, alimentando agentes de IA com extração web confiável sem proxies ou dores de cabeça.
UseScraper é uma API de web scraping e crawling hiper-rápida. Raspe qualquer URL instantaneamente, rastreie sites inteiros e exporte dados em texto simples, HTML ou Markdown. As primeiras 1.000 páginas são gratuitas.
BulkGPT é uma ferramenta sem código para automação de fluxos de trabalho IA em massa, permitindo raspagem web rápida e processamento em lotes de ChatGPT para criar conteúdo SEO, descrições de produtos e materiais de marketing sem esforço.
Apify é uma plataforma de nuvem completa para web scraping, automação de navegador e agentes de IA. Use ferramentas pré-construídas ou crie seus próprios Actors para extração de dados e automação de fluxo de trabalho.
Capalyze é uma ferramenta de análise de dados que capacita empresas com insights por meio de integração multi-fonte e crawling de dados web, impulsionando decisões mais inteligentes.

Exa é um mecanismo de pesquisa com tecnologia de IA e uma API de dados da web projetada para desenvolvedores. Ele oferece pesquisa web rápida, websets para consultas complexas e ferramentas para rastrear, responder e pesquisar em profundidade, permitindo que a IA acesse informações em tempo real.
Horseman é um rastreador da web configurável que usa trechos de código JavaScript e a integração GPT para fornecer informações sobre o seu site. É perfeito para desenvolvedores, especialistas em SEO e analistas de desempenho.

Olostep é uma API de dados da web para IA e agentes de pesquisa. Permite extrair dados da web estruturados de qualquer site em tempo real e automatizar seus fluxos de trabalho de pesquisa na web. Os casos de uso incluem dados para IA, enriquecimento de planilhas, geração de leads e muito mais.
Aplicativos web recentes criados com IA e a coleção completa de 15 aplicativos web utilitários criados com IA em 30 dias, incluindo AutoRoadmap.
Crawl AI: Crie assistentes de IA, agentes e web scrapers personalizados facilmente. Raspe sites da web, extraia dados e potencialize pesquisas profundas.
Virally automatiza posts personalizados e baseados em tendências para LinkedIn e X com IA. Rastreia a web por conteúdo fresco, reutiliza em posts prontos para publicar via modo autopilot ou manual. Ideal para profissionais ocupados que economizam tempo e aumentam engajamento.
Crie chatbots de IA personalizados com Gali AI, treinados em seus dados para melhorar a conversão do site, apoiar os clientes e interagir com os documentos 24/7. Configuração rápida, sem necessidade de codificação.
DeerFlow é um assistente de pesquisa profunda com tecnologia de IA que combina modelos de linguagem com ferramentas como mecanismos de busca, rastreadores da web e Python para obter insights, relatórios e podcasts.
Ncurator é uma extensão de navegador que usa IA para ajudá-lo a gerenciar e analisar sua base de conhecimento. Ele pode encontrar e organizar respostas para você.