
FramePack 概述
FramePack:革新消费级 GPU 上的视频生成
什么是 FramePack?FramePack 是一项突破性的开源视频扩散技术,旨在在消费级 GPU 上实现高质量的视频生成,仅需 6GB 的 VRAM。它采用创新的帧上下文打包方法,使 AI 视频创建比以往任何时候都更容易。
主要特性和优势:
- 低 VRAM 要求: 仅需 6GB 的 VRAM,即可在笔记本电脑和中端系统上生成高质量的视频。
- 防漂移技术: 使用 FramePack 的双向采样方法,在长视频序列中保持一致的质量。
- 本地执行: 直接在您的硬件上生成视频,无需云处理或昂贵的 GPU 租赁。
FramePack 的工作原理
FramePack 提供了一个直观的工作流程,用于生成高质量的视频内容:
- 安装和设置: 通过 GitHub 安装并设置您的环境。
- 定义您的初始帧: 从图像开始,或从文本提示生成一个图像,以开始您的视频序列。
- 创建运动提示: 用自然语言描述所需的运动和动作,以指导视频生成。
- 生成和审查: 观看 FramePack 逐帧生成您的视频,具有令人印象深刻的时间一致性。
核心技术详解
- 帧上下文打包: 高效地压缩和利用帧上下文信息,以实现在消费级硬件上的处理。这是 FramePack 低 VRAM 要求的关键。
- 本地视频生成: 直接在您的设备上生成视频,无需将数据发送到外部服务器,确保隐私和控制。
- 双向采样: 使用防漂移技术,在长视频序列中保持一致性。这可以防止视频质量随时间推移而下降。
- 优化性能: 在具有 Teacache 优化的的高端 GPU 上,以大约每帧 1.5 秒的速度生成帧。即使在低端硬件上,该性能也可用于原型设计。
- 开源访问: 受益于完全开源的实现,允许自定义和社区贡献。这促进了创新并确保了长期支持。
- 多模态输入: 使用文本提示和图像输入来指导您的视频生成,从而在创作过程中提供灵活性和控制力。
为什么 FramePack 很重要?
FramePack 通过让硬件资源有限的用户也能访问 AI 视频生成,从而实现了 AI 视频生成的民主化。在本地运行视频生成的能力对于注重隐私的用户和互联网带宽有限的用户来说是一个显著的优势。FramePack 的开源性质鼓励社区协作和持续改进。
用户评价
- Emily Johnson,独立动画师: “FramePack 改变了我创作动画的方式。能够在我的笔记本电脑上生成高质量的视频意味着我可以在任何地方工作,而且结果足以用于客户演示。”
- Michael Rodriguez,VFX 专家: “作为与多个创意团队合作的人,FramePack 改变了游戏规则。它提供了一种快速、高效的方式来原型化视频概念,而无需等待渲染场,从而节省了我们无数的生产时间。”
- Sarah Chen,AI 研究员: “这个工具改变了我们进行视频生成研究的方式。FramePack 创新的帧上下文打包使我们能够在标准实验室设备上尝试更长的序列,从而大大加快了我们的研究周期。”
常见问题解答
- FramePack 到底是什么,它是如何工作的? FramePack 是一种开源视频扩散技术,可在消费级 GPU 上实现下一帧预测。它通过有效地打包帧上下文信息并使用恒定长度的输入格式来实现,即使在 VRAM 有限的硬件上也能逐帧生成高质量的视频。
- FramePack 的系统要求是什么? FramePack 需要一个具有至少 6GB VRAM(如 RTX 3060)、CUDA 支持、PyTorch 2.6+ 的 NVIDIA GPU,并且可在 Windows 或 Linux 上运行。为了获得最佳性能,建议使用具有 8GB+ VRAM 的 RTX 30 或 40 系列 GPU。
- FramePack 生成视频的速度有多快? 在像 RTX 4090 这样的高端 GPU 上,FramePack 可以使用 Teacache 优化以大约每帧 1.5 秒的速度生成帧。在具有 6GB VRAM 的笔记本电脑上,生成速度慢 4-8 倍,但仍然可用于原型设计。
- FramePack 可以免费使用吗? FramePack 提供具有完整功能的免费开源版本。高级版可能为专业用户和团队提供额外的功能、优先支持和扩展功能。
- FramePack 中的“帧上下文打包”是什么? 帧上下文打包是 FramePack 的核心创新,它可以将来自先前帧的信息高效地压缩为恒定长度的格式。这使模型能够保持时间一致性,而无需随着视频长度的增加而增加内存。
- FramePack 与其他视频生成工具相比如何? 与基于云的解决方案不同,FramePack 完全在您的硬件上本地运行。虽然某些云服务可能提供更快的生成速度,但 FramePack 提供了卓越的隐私、没有使用限制以及生成具有一致质量的更长序列的能力。
结论
FramePack 代表了 AI 视频生成领域的一大进步。其低 VRAM 要求、开源性质和创新的帧上下文打包技术使其成为业余爱好者和专业人士的宝贵工具。无论您是创建动画、原型化视频概念还是进行研究,FramePack 都提供了一种快速、高效且易于访问的解决方案,用于在消费级 GPU 上生成高质量的视频。在您的本地机器上生成视频的最佳方式是什么?FramePack 绝对是一个有力的竞争者。
"FramePack"的最佳替代工具
Emu Video是由Meta推出的AI驱动的文本到视频工具,利用扩散模型从文本提示生成高质量视频。它采用分解生成方法,高效地创建16fps的4秒视频。
Lumiere是谷歌研究公司开发的一种用于视频生成的时空扩散模型。它支持文本到视频、图像到视频、视频风格化、电影图和修复,从而生成逼真且连贯的运动。
MotionAgent 是一个开源 AI 工具,通过使用 Qwen-7B-Chat 和 SDXL 等模型,将想法转化为动态图片,包括生成脚本、电影静态图像、高分辨率视频和自定义背景音乐。
AnimateDiff 是一个免费的在线视频制作工具,能为 AI 生成的视觉内容注入动态。使用文本提示创建动画,或为现有图像添加从真实视频中学到的自然运动。这个即插即用框架为 Stable Diffusion 等扩散模型添加视频功能,而无需重新训练。探索 AnimateDiff 的文本转视频和图像转视频生成工具,开启 AI 内容创作的未来。
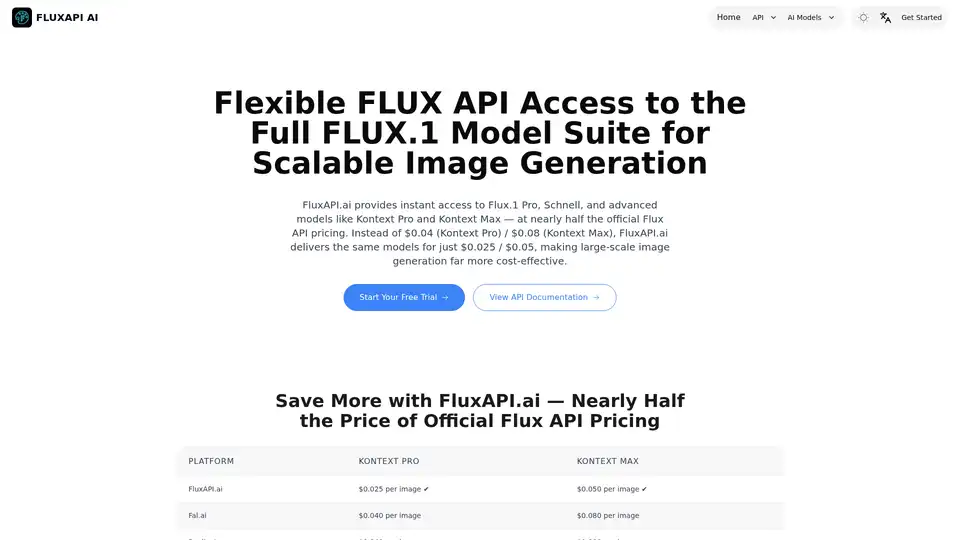
FluxAPI.ai 提供快速、灵活的 Flux.1 套件访问,用于文本到图像和图像编辑。Kontext Pro 仅需 0.025 美元,Kontext Max 仅需 0.05 美元,以更低成本享受相同模型——适合扩展 AI 图像生成的开发者和创作者。
NMKD Stable Diffusion GUI 是一款免费开源工具,可在本地 GPU 上使用 Stable Diffusion 生成 AI 图像。它支持文本到图像、图像编辑、上采样和 LoRA 模型,无审查或数据收集。
PayPerQ (PPQ.AI) 使用比特币和加密货币提供对领先AI模型如GPT-4o的即时访问。按查询付费,无需订阅或注册,支持文本、图像和视频生成。

使用Stable Video 3D (SV3D)从单张图像生成多视角3D模型。利用Stable Video Diffusion实现高质量、一致的3D可视化。
使用 ToonCrafter AI 将照片转换为引人入胜的卡通,这是一款用于无缝卡通插值和视频生成的开源 AI 工具。非常适合动画爱好者和创意总监。
Wan 2.2是阿里巴巴领先的AI视频生成模型,现已开源。它提供电影般的视觉控制,支持文本到视频和图像到视频的生成,并提供高效的高清混合TI2V。