DataChain 概述
什么是 DataChain?
DataChain 是一个 AI 原生平台,旨在处理高级机器学习和人工智能时代中海量数据的复杂性。其突出之处在于为多模态数据集提供集中式注册表,包括视频、音频文件、PDF、图像、MRI 扫描甚至嵌入向量。与传统的基于 SQL 的工具不同——那些工具难以处理存储在 S3、GCS 或 Azure 等对象存储中的非结构化或大规模数据——DataChain 弥合了开发者友好工作流与企业级处理之间的差距。该平台赋能从初创公司到财富 500 强企业高效地策展、丰富和版本化其数据集,将原始的多模态输入转化为可操作的 AI 知识。
DataChain 的核心解决了从大数据到其所谓的“海量数据”的转变——即充满未开发 AI 应用潜力的丰富非结构化格式。无论您是在构建智能体、副驾驶还是自适应工作流,DataChain 都能确保您的数据管道不需要持续重新处理,从而节省时间和资源,同时释放更深入的洞察。
DataChain 如何运作?
DataChain 遵循开发者优先的理念,结合了 Python 的简洁性与类 SQL 操作的可扩展性。以下是其关键机制的解析:
集中式数据集注册表:所有数据集均通过完整的血缘关系、元数据和版本控制进行跟踪。您可以通过用户界面(UI)、聊天界面、集成开发环境(IDE)甚至通过模型控制协议(MCP)的 AI 智能体无缝访问它们。该注册表作为单一事实来源,使得管理依赖关系和重现结果变得轻松。
Python 简洁性与 SQL 规模相结合:开发者使用一种熟悉的语言——Python——跨越代码和数据操作。这消除了由独立 SQL 工具造成的孤岛,增强了与 IDE 和 AI 智能体的集成。例如,您可以在不切换上下文的情况下查询和操作海量数据,从而简化工作流。
本地开发与云扩展:在本地 IDE 中开始构建和测试数据管道以实现快速迭代。准备就绪后,无需代码修改即可无缝扩展至云中的数百个 GPU。这种混合方法在不影响大规模任务性能的前提下最大化生产力。
零数据复制与锁定:您的原始文件——视频、图像、音频——保留在如 S3 的本机存储中。DataChain 仅引用和跟踪版本,避免不必要的重复或供应商锁定。这不仅降低成本,还确保数据主权和灵活性。
该平台利用大型语言模型(LLM)和机器学习模型从非结构化源中提取结构、嵌入向量和洞察。例如,它可以在 ETL(提取、转换、加载)过程中将模型应用于视频或 PDF,将混乱组织成 AI 就绪格式。
DataChain 的核心功能
DataChain 的工具套件覆盖了 AI 项目数据处理的每个阶段。关键功能包括:
多模态数据精通:在一处处理多样格式,如视频(🎥)、音频(🎧)、PDF(📄)、图像(🖼️)和医疗扫描(🔬 MRI)。使用 LLM 提取洞察,轻松处理非结构化内容。
无缝 ETL 管道:构建自动化工作流,将原始文件转化为丰富的数据集。大规模过滤、连接和更新数据,为从实验跟踪到模型版本化的所有环节提供动力。
数据血缘与可重现性:跟踪代码、数据和模型之间的每个依赖关系。按需重现数据集并自动化更新,这对可重现的 ML 研究和合规性至关重要。
大规模处理:管理数百万或数十亿文件而无瓶颈。高效计算更新并利用 ML 进行高级过滤,使其成为海量数据场景的理想选择。
集成与可访问性:支持 UI、聊天、IDE 和智能体。通过 GitHub 仓库的开源元素允许定制,而基于云的 Studio 提供即用型环境。
这些功能得到与全球行业领导者可信合作伙伴关系的支持,确保高风险 AI 部署的可靠性。
如何使用 DataChain?
开始使用 DataChain 简单且免费:
注册:在 DataChain 网站上创建账户以访问平台。无前期成本——立即开始探索。
设置环境:连接您的对象存储(如 S3)并导入数据集。使用直观的 UI 或 Python SDK 开始策展数据。
构建管道:使用 Python 在本地 IDE 中开发。应用 ML 模型进行丰富,然后部署到云端进行扩展。
版本与跟踪:使用元数据和血缘关系注册数据集。使用 MCP 进行智能体交互或通过自然语言查询。
监控与迭代:利用注册表重现结果,通过 ETL 更新数据集,并为您的 AI 模型分析洞察。
文档、快速入门指南和 Discord 社区支持使入门顺畅。对于企业需求,联系销售获取根据您的规模定制的价格和功能。
为何选择 DataChain?
在 AI 需要更庞大、更复杂数据集的背景下,DataChain 通过使海量数据可访问和可管理提供竞争优势。传统工具在非结构化格式上不足,导致孤岛和低效。DataChain 以其零复制方法消除这些痛点,在某些情况下降低存储成本高达 100%,其以开发者为中心的设计加速洞察时间。
使用 DataChain 的团队报告更快的实验跟踪、无缝模型版本化和强大的管道自动化。它在避免迭代 AI 开发中的重新处理方面特别有价值,其中数据或模型的更改否则可能导致数小时的返工。此外,无锁定让您保留对基础设施的控制。
与替代方案相比,DataChain 对多模态海量数据的关注使其脱颖而出——它不仅是另一个数据管理工具;它是为下一波 AI 构建的,从生成模型到实时智能体。
DataChain 适合谁?
DataChain 是 AI 生态系统中广泛用户的理想选择:
开发者和数据科学家:那些构建 ML 管道、需要用于多模态数据而无 SQL 障碍的 Python 原生工具的人。
初创企业和企业中的 AI/ML 团队:从早期创新者到处理视频分析、音频转录或医疗成像的财富 500 强公司。
研究人员和分析师:任何需要具有完整血缘关系的可重现数据集以进行计算机视觉、NLP 或多模态 AI 实验的人。
产品构建者:创建依赖丰富、版本化知识库的副驾驶、智能体或自适应系统。
如果您正在努力处理对象存储中的非结构化数据,并希望将其用于 AI 而无额外开销,DataChain 是您的首选解决方案。
实用价值与用例
DataChain 通过将海量数据转化为战略资产提供切实价值。考虑这些实际应用:
媒体与娱乐:处理视频和音频库以提取用于推荐引擎或内容审核的嵌入向量。
医疗保健:为 AI 驱动诊断版本化 MRI 扫描和 PDF,确保通过数据血缘跟踪合规。
电子商务:使用 LLM 丰富产品图像和描述以构建个性化搜索和虚拟试穿功能。
研究实验室:为多模态学习中的大规模数据集自动化 ETL,加速模型训练周期。
用户称赞其可扩展性——轻松处理数十亿文件——以及 IDE 集成带来的生产力提升。虽然价格详情需联系获取,但免费层降低了实验门槛。
总之,DataChain 重新定义了大规模 AI 的数据管理。通过以最小摩擦策展、丰富和版本化多模态数据集,它赋能高效团队在海量数据革命中领先。准备将您的数据转化为 AI 优势了吗?立即注册并探索其 GitHub 以获取开源贡献。
"DataChain"的最佳替代工具
发现Pal Chat,这是iOS的轻量级却强大的AI聊天客户端。访问GPT-4o、Claude 3.5等模型,完全隐私保护——不收集任何数据。在iPhone或iPad上生成图像、编辑提示,并享受无缝AI交互。

探索 ChatGPT 深度研究免费版,这是 OpenAI 深度研究的最佳在线替代方案,适合无法访问的用户。通过 AI 驱动的网络研究,生成带引用的详细报告,并高效处理复杂查询——全部免费。
Agent TARS 是一个开源多模态 AI 代理,无缝集成浏览器操作、命令行和文件系统,实现增强的工作流自动化。体验先进的视觉解释和复杂的推理,以高效处理任务。
探索Nano Banana AI,由Gemini 2.5 Flash Image驱动,提供免费在线图像生成和编辑。创建一致角色、轻松编辑照片,并探索动漫或3D转换等风格,在NanoBananaArt.ai上。
Google Gemini是一款多模态AI助手,与Google生态系统深度集成,通过文本、语音和视觉交互提供高级写作辅助、规划、头脑风暴和生产力工具。
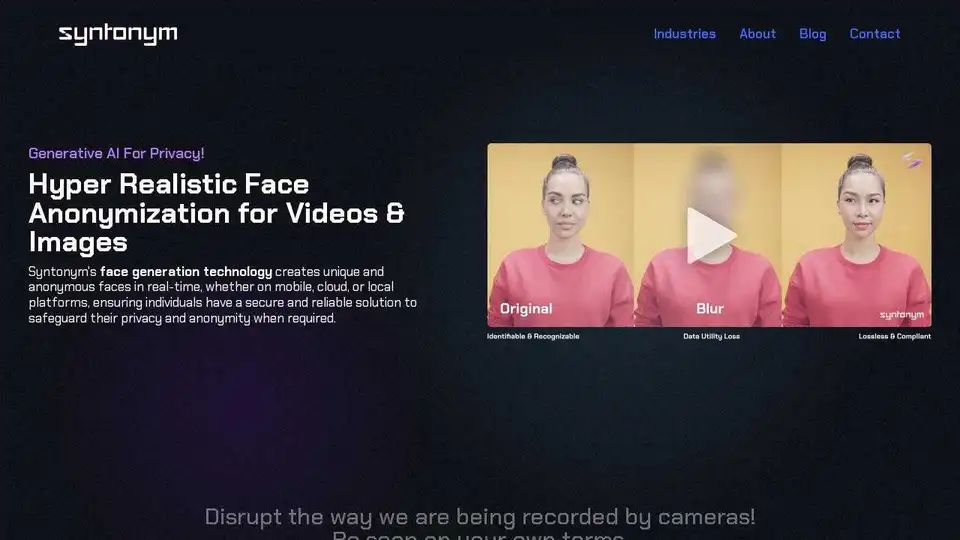
Syntonym 通过提供无损匿名化来增强机器视觉,在保护个人数据的同时保持人工智能模型的数据效用。通过实时匿名化解决方案确保隐私和合规性。
Innovatiana 提供专业的数据标注服务,并为 ML、DL、LLM、VLM、RAG 和 RLHF 构建高质量的 AI 数据集,确保合乎道德且具有影响力的 AI 解决方案。
加入Llama Family,一个致力于通过Llama模型推动AI进步的开源社区。探索各种模型,为生态系统做出贡献,并共同迈向AGI。
Ocular AI 是一个多模态数据湖平台,允许您在非结构化数据上摄取、管理、搜索、注释和训练自定义 AI 模型。为多模态 AI 时代而构建。