Llama Family 概述
Llama Family: 开源 AI 模型生态系统
什么是 Llama Family? Llama Family 是一个开源社区,致力于通过围绕 Llama 模型和相关技术的协作努力,促进通用人工智能 (AGI) 的发展。 它的目标是创建一个平台,让开发者和爱好者可以为开源生态系统做出贡献,该生态系统涵盖 AI 的各个方面,从大型模型到小型模型,从文本到多模态能力,以及从软件到硬件算法优化。
Llama Family 的主要组成部分
模型: 该社区专注于 Meta 开源的各种 Llama 模型,包括 Llama、Llama 2、Llama 3、Code Llama 和 Atom。 这些模型涵盖了一系列参数大小和训练数据集,可满足不同的用例和研究方向。
计算: 该社区鼓励为模型训练和实验进行协作和资源共享。 这包括利用 GPU 资源,例如 GeForce RTX 系列、NVIDIA H100 和 A100 Tensor Core GPU。
社区: Llama Family 的核心是其充满活力的开发者、研究人员和爱好者社区。 该社区促进协作、知识共享以及资源和工具的共同创建。
Llama 模型
Meta Llama
Meta 开源的 Llama 模型已广泛应用于工业界和学术界。 版本包括 1B、3B、8B、70B 和 405B,训练数据超过 15.0T tokens。 Vision 模型包括 11B 和 90B,在超过 60 亿个图像-文本对上进行训练。
| Model | Training Data | Params | Tokens | Release Date |
|---|---|---|---|---|
| LLaMA | English CommonCrawl, C4, Github, Wikipedia, Gutenberg and Books3, ArXiv, Stack Exchange | 7B (6.7B) | 1.0T | 2023/02/24 |
| 13B (13.0B) | 1.0T | |||
| 33B (32.5B) | 1.4T | |||
| 65B (65.2B) | 1.4T | |||
| Llama 2 | A new mix of publicly available online data | 7B | 2.0T | 2023/07/18 |
| 13B | 2.0T | |||
| 34B | 2.0T | |||
| 70B | 2.0T | |||
| Llama 3 | A new mix of publicly available online data | 8B | 15.0T | 2024/04/18 |
| 70B | 15.0T | |||
| Llama 3.1 | Collected from publicly available sources, over 5% of the Llama 3 pretraining dataset consists of high-quality non-English data that covers over 30 languages | 8B | 15.0T | 2024/07/23 |
| 70B | 15.0T | |||
| 405B | 15.0T | |||
| Llama 3.2 | Llama 3.2-Text: A new mix of publicly available online data | 1B (1.23B) | 9.0T | 2024/09/25 |
| 3B (3.21B) | 9.0T | |||
| Llama 3.2-Vision | Pretrained on image and text pairs. The instruction tuning data includes publicly available vision instruction datasets, as well as over 3M synthetically generated examples | 11B (10.6B) | 6B (image, text) pairs | |
| 90B (88.8B) | 6B (image, text) pairs |
Code Llama
Code Llama 基于 Llama 2 使用代码数据进行训练,并分为 Base Model、Python Model 和 Instruct Model,参数大小为 7B、13B、34B 和 70B。 它支持代码续写、填充和基于指令的编程。
| Model | Training Data | Params | Type |
|---|---|---|---|
| Code Llama | Based on Llama 2, trained using a public code dataset of 500B tokens. To help the model retain natural language understanding skills, 8% of the sample data comes from natural language datasets related to code. | 7B | Base Model: a foundational model for code generation tasks |
| Python: a version specialized for Python | |||
| Instruct: a fine-tuned version with human instructions and self-instruct code synthesis data | |||
| 13B | |||
| 34B | |||
| 70B |
Atom
Atom 由 AtomEcho 和 Llama Family 联合开发,基于 Llama 架构,并在 2.7T 中文和多语种语料库上进行训练,参数大小包括 1B、7B 和 13B。 Atom 增强了 Llama 模型的中文语言能力。
| Model | Training Data | Params | Tokens | Release Date |
|---|---|---|---|---|
| Atom | Chinese and multilingual encyclopedias, books, blogs, news, novels, financial data, legal data, medical data, code, paper, Chinese NLP competition datasets, etc. | 1B | 2.7T | 2023/12/20 |
| 7B | 2.7T | 2023/08/28 | ||
| 13B | 2.7T | 2023/07/31 |
如何为 Llama Family 做出贡献
- 加入社区: 通过论坛、聊天群组和活动与其他开发者和爱好者互动。
- 贡献代码: 提交包含错误修复、新功能或模型改进的拉取请求。
- 分享资源: 与社区分享数据集、训练脚本和预训练模型。
- 提供反馈: 提供关于现有模型和工具的反馈,以帮助提高它们的质量和可用性。
为什么 Llama Family 很重要?
Llama Family 很重要,因为它促进了协作并加速了开源 AI 模型的发展。 通过为开发者和研究人员提供一个共享资源和知识的平台,Llama Family 帮助 democratize 对 AI 技术的访问并促进创新。
结论
Llama Family 是一个不断壮大的社区,致力于通过开源协作来推进 AI 的发展。 立即加入 Llama Family,为 AI 的未来做出贡献!
"Llama Family"的最佳替代工具
ChatLLaMA 是基于 LLaMA 模型的 LoRA 训练 AI 助手,可在本地 GPU 上运行自定义个人对话。提供桌面 GUI,使用 Anthropic 的 HH 数据集训练,支持 7B、13B 和 30B 模型。
Nebius AI Studio Inference Service 提供托管开源模型,实现比专有 API 更快、更便宜、更准确的推理结果。无需 MLOps,即可无缝扩展,适用于 RAG 和生产工作负载。
Falcon LLM 是 TII 的开源生成式大语言模型家族,包括 Falcon 3、Falcon-H1 和 Falcon Arabic 等,支持多语言、多模态 AI 应用,可在日常设备上高效运行。
LM Studio 是一款用户友好的桌面应用,用于在您的电脑上本地运行和下载 LLaMa 和 Gemma 等开源大语言模型 (LLM)。它提供应用内聊天界面和兼容 OpenAI 的本地服务器,无需编程技能即可离线使用AI模型。
OpenUI 是一个开源工具,让您用自然语言描述 UI 组件,并使用大语言模型实时渲染。将描述转换为 HTML、React 或 Svelte,实现快速原型设计。

Unsloth AI 为 LLM(如 gpt-oss 和 Llama)提供开源微调和强化学习,训练速度提高 30 倍,内存使用量减少,从而使 AI 训练变得易于访问且高效。
Cheshire Cat AI 是一个简化 AI 代理构建的开源框架。它支持 LLM、外部 API 和插件,所有这些都在 Docker 化的环境中,便于部署和自定义。
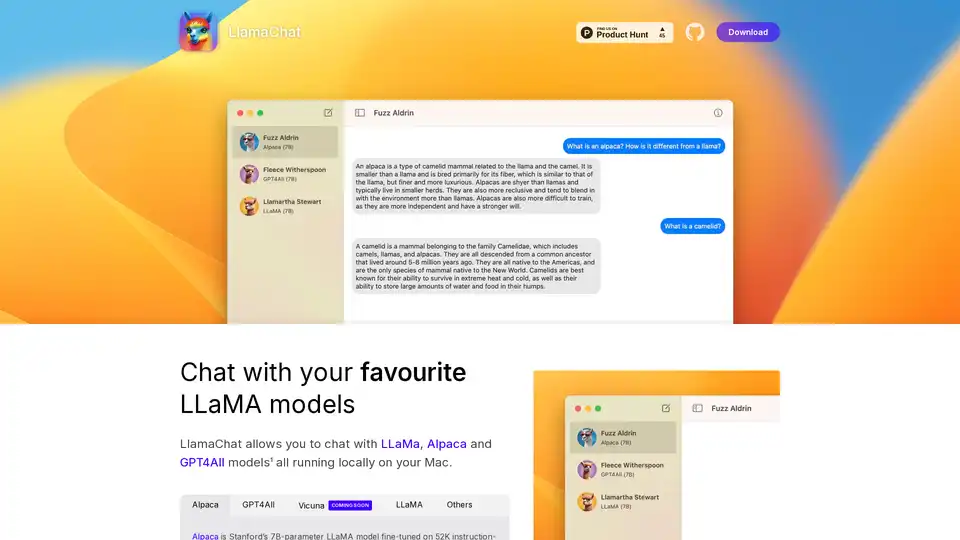
LlamaChat 是一款 macOS 应用程序,允许您在 Mac 上本地与 LLaMA、Alpaca 和 GPT4All 模型聊天。 立即下载并体验本地 LLM 聊天!
Sagify 是一个开源 Python 工具,可简化 AWS SageMaker 上的机器学习管道,提供统一的 LLM 网关,实现专有和开源大型语言模型的无缝集成,提高生产力。