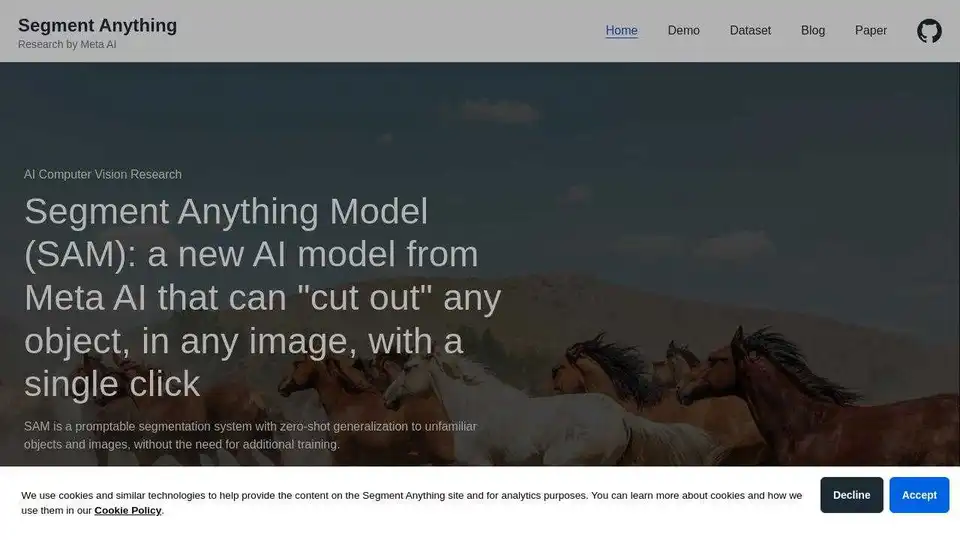
Segment Anything Model (SAM) 概述
Segment Anything Model (SAM): 使用 AI 革新图像分割
什么是 Segment Anything Model (SAM)?它是由 Meta AI 开发的尖端 AI 模型,旨在以空前的简易性和灵活性执行图像分割。它允许用户使用诸如单击之类的提示“剪切”图像中的任何对象,从而使其具有高度的交互性和用户友好性。
Segment Anything Model (SAM) 如何工作?
SAM 作为一个可提示的分割系统运行,这意味着它可以根据各种输入提示分割图像,而无需额外的训练。 这种能力被称为零样本泛化。 该模型已经学习了构成对象的通用概念,使其能够有效地处理不熟悉的对象和图像。
主要功能包括:
- 交互式提示: 使用点、框或蒙版来指定要分割的内容。
- 自动分割: 自动分割图像中的所有内容。
- 歧义处理: 为模糊的提示生成多个有效的蒙版。
- 可扩展的输出: 输出蒙版可以用作其他 AI 系统的输入。
- 零样本泛化: 该模型的预训练理解使其能够泛化到新的对象和图像,而无需重新训练。
为什么 Segment Anything Model (SAM) 如此重要?
SAM 代表了计算机视觉的重大进步,在图像分割方面提供了多功能性和效率。 其可提示的设计有助于与其他系统集成,为创新应用铺平了道路。 它还大大减少了计算机视觉任务中通常需要的注释工作。
如何使用 Segment Anything Model (SAM)?
- 提供提示: 输入提示,例如前景/背景点、边界框或蒙版。
- 运行推理: 图像编码器处理图像以创建图像嵌入。
- 解码蒙版: 提示编码器和蒙版解码器从图像和提示嵌入生成对象蒙版。
Segment Anything Model (SAM) 适用于谁?
SAM 对广泛的用户都很有价值,包括:
- AI 研究人员: 探索计算机视觉的新可能性。
- 应用程序开发人员: 将灵活的分割功能集成到他们的应用程序中。
- 数据科学家: 简化和加速图像注释过程。
- 创意专业人士: 使用分割的对象进行图像编辑、拼贴和 3D 建模。
SAM 的数据引擎:秘诀
SAM 的能力是通过在使用模型在环“数据引擎”收集的数百万张图像和蒙版上进行训练的结果。 研究人员迭代地注释图像并更新模型,从而显着提高了其性能和数据集。
高效且灵活的模型设计
SAM 的设计旨在提高效率。 它将模型分解为:
- 一次性图像编码器。
- 可以在 Web 浏览器中运行的轻量级蒙版解码器。
这种设计允许快速推理,并使 SAM 可以在各种平台上访问。
常见用例:
- 视频中的对象跟踪: 跟踪视频帧中分割的对象。
- 图像编辑应用程序: 通过隔离对象实现精确编辑。
- 3D 建模: 将 2D 蒙版提升为 3D 模型。
- 创意任务: 使用分割的元素创建拼贴和其他艺术作品。
常见问题 (FAQ)
- 支持哪些类型的提示? 支持前景/背景点、边界框和蒙版。 研究论文中探讨了文本提示,但目前尚未发布。
- 模型的结构是什么? 它使用 ViT-H 图像编码器、提示编码器和基于轻量级 Transformer 的蒙版解码器。
- 模型使用什么平台? 图像编码器在带有 GPU 的 PyTorch 上运行,而提示编码器和蒙版解码器可以使用 ONNX 运行时在 CPU 或 GPU 上运行。
通过利用 SAM,用户可以在图像分割中释放新的精度和效率水平,从而为各种创新应用打开大门。 SAM 的用户友好和高效的设计使其成为研究人员、开发人员和创意专业人士的变革性工具。
SAM:实例分割的通用模型
Segment Anything Model (SAM) 代表了 AI 驱动的图像分割的重大飞跃。 它泛化到未见数据并处理各种提示的能力使其成为研究人员、开发人员以及任何从事计算机视觉任务的人员的宝贵工具。 随着 Meta AI 不断开发和完善 SAM,其对图像处理领域的潜在影响是巨大的。
"Segment Anything Model (SAM)"的最佳替代工具
T-Rex Label 是一款AI驱动的数据标注工具,支持Grounding DINO、DINO-X和T-Rex模型。它兼容COCO和YOLO数据集,提供边界框、图像分割和掩码标注等功能,可高效创建计算机视觉数据集。
了解如何在 Google Colab 上使用 AUTOMATIC1111 的 Web UI 轻松运行 Stable Diffusion。安装模型、LoRA 和 ControlNet,实现快速 AI 图像生成,无需本地硬件。
Ultralytics HUB使用户能够通过无代码平台创建、训练和部署AI模型。使用Ultralytics YOLO训练视觉AI模型,用于物体检测和图像分割。
探索Robovision的AI驱动计算机视觉平台,实现智能自动化。它使用深度学习处理视觉数据,支持制造业和农业等行业的模型训练和部署。
People For AI为AI训练提供高质量的数据标注和注释服务。 他们在计算机视觉和自然语言处理方面拥有专业知识,可确保为机器学习项目提供准确可靠的数据集。
AI Superior 是一家位于德国的 AI 服务公司,专门从事 AI 驱动的应用程序开发和咨询。他们提供定制 AI 解决方案、培训和研发,以增强企业的竞争力。
Datature 是一个端到端视觉 AI 平台,可加速企业和开发人员的数据标注、模型训练和部署。以 10 倍的速度构建可用于生产的数据集,并无缝集成视觉智能。

Emu Edit 由 Meta AI 开发,是一款擅长于基于指令编辑的多任务图像编辑模型。它经过广泛的任务训练,包括基于区域的编辑、自由形式编辑和计算机视觉,在该领域树立了新的标准。
BasicAI 提供领先的数据标注平台和专业标注服务,用于 AI/ML 模型,深受 AV、ADAS 和智能城市应用中的数千用户信赖。拥有 7 年以上专业经验,确保高质量、高效的数据解决方案。
Innovatiana 提供专业的数据标注服务,并为 ML、DL、LLM、VLM、RAG 和 RLHF 构建高质量的 AI 数据集,确保合乎道德且具有影响力的 AI 解决方案。