Groq
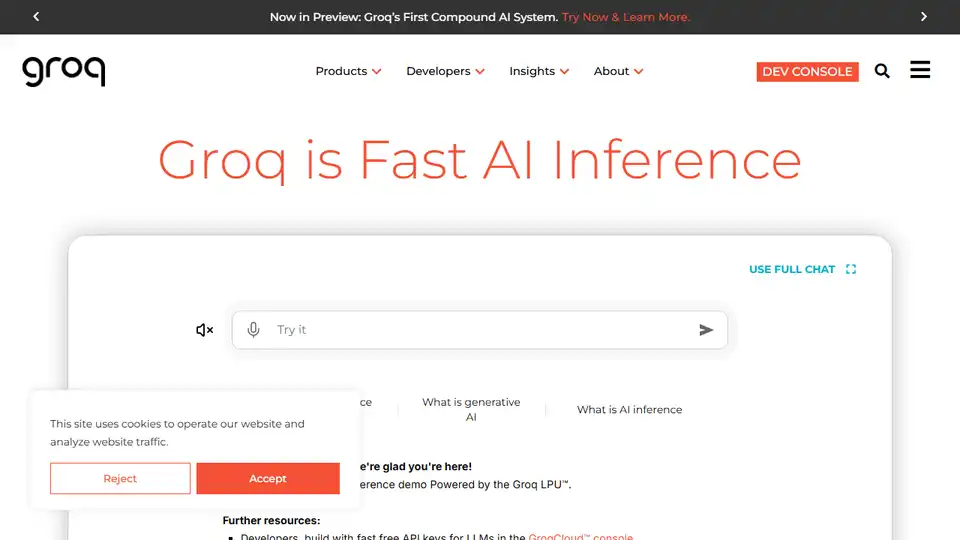
Vue d'ensemble de Groq
Groq : L’infrastructure pour l’inférence
Qu’est-ce que Groq ?
Groq est une entreprise axée sur la fourniture de solutions d’inférence rapides pour les constructeurs d’IA. Leur principale offre est le LPU™ Inference Engine, une plateforme matérielle et logicielle conçue pour une vitesse de calcul, une qualité et une efficacité énergétique exceptionnelles. Groq fournit des solutions infonuagiques (GroqCloud™) et sur site (GroqRack™) pour répondre aux divers besoins de déploiement.
Comment fonctionne Groq ?
Le LPU™ (Language Processing Unit) de Groq est conçu sur mesure pour l’inférence, ce qui signifie qu’il est conçu spécifiquement pour l’étape où les modèles d’IA entraînés sont déployés et utilisés pour faire des prédictions ou générer des résultats. Cela contraste avec l’adaptation du matériel à usage général pour l’inférence. Le LPU™ est développé aux États-Unis avec une chaîne d’approvisionnement résiliente, assurant une performance constante à l’échelle. Cet accent mis sur l’inférence permet à Groq d’optimiser la vitesse, le coût et la qualité sans compromis.
Principales caractéristiques et avantages de Groq :
- Performance de prix inégalée: Groq offre le coût par jeton le plus bas, même lorsque l’utilisation augmente, sans sacrifier la vitesse, la qualité ou le contrôle. Cela en fait une solution rentable pour les déploiements d’IA à grande échelle.
- Vitesse à n’importe quelle échelle: Groq maintient une latence inférieure à la milliseconde, même en cas de trafic intense, dans différentes régions et pour différentes charges de travail. Cette performance constante est essentielle pour les applications d’IA en temps réel.
- Qualité du modèle à laquelle vous pouvez faire confiance: L’architecture de Groq préserve la qualité du modèle à toutes les échelles, des modèles compacts aux modèles Mixture of Experts (MoE) à grande échelle. Cela garantit des prédictions d’IA précises et fiables.
Plateforme GroqCloud™
GroqCloud™ est une plateforme à pile complète qui offre une inférence rapide, abordable et prête pour la production. Il permet aux développeurs d’intégrer de manière transparente la technologie de Groq en quelques lignes de code.
Grappe GroqRack™
GroqRack™ offre un accès sur site à la technologie de Groq. Il est conçu pour les entreprises clientes et offre une performance de prix inégalée.
Pourquoi Groq est-il important ?
L’inférence est une étape essentielle du cycle de vie de l’IA où les modèles entraînés sont mis au travail. L’accent mis par Groq sur l’infrastructure d’inférence optimisée répond aux défis du déploiement de modèles d’IA à l’échelle, assurant à la fois la vitesse et la rentabilité.
Où puis-je utiliser Groq ?
Les solutions de Groq peuvent être utilisées dans une variété d’applications d’IA, y compris :
- Large Language Models (LLMs)
- Voice Models
- Diverses applications d’IA nécessitant une inférence rapide
Comment commencer à créer avec Groq :
Groq fournit une API key gratuite pour permettre aux développeurs d’évaluer et d’intégrer rapidement la technologie de Groq. La plateforme offre également des Groq Libraries et des Demos pour aider les développeurs à démarrer. Vous pouvez essayer Groq gratuitement en visitant leur site Web et en vous inscrivant pour obtenir un compte.
Groq applaudit le plan d’action sur l’IA de l’administration Trump, accélère le déploiement mondial de la pile d’IA américaine et Groq lance l’empreinte du centre de données européen à Helsinki, en Finlande.
En conclusion, Groq est un puissant moteur d’inférence pour l’IA. Groq fournit des solutions infonuagiques et sur site à l’échelle pour les applications d’IA. Grâce à son accent sur la vitesse, la rentabilité et la qualité du modèle, Groq est bien positionné pour jouer un rôle clé dans l’avenir des déploiements d’IA. Si vous recherchez une inférence d’IA rapide et fiable, Groq est une plateforme que vous devriez envisager.
Meilleurs outils alternatifs à "Groq"
HUMAIN fournit des solutions d'IA complètes, couvrant l'infrastructure, les données, les modèles et les applications. Accélérez les progrès et libérez un impact concret à grande échelle grâce aux plateformes natives d'IA de HUMAIN.
Spice.ai est un moteur d'inférence de données et d'IA open source pour créer des applications d'IA avec la fédération de requêtes SQL, l'accélération, la recherche et la récupération basées sur les données d'entreprise.
Local AI est une application native open source gratuite qui simplifie l'expérimentation avec des modèles d'IA localement. Il offre l'inférence CPU, la gestion des modèles et la vérification des digests, et ne nécessite pas de GPU.
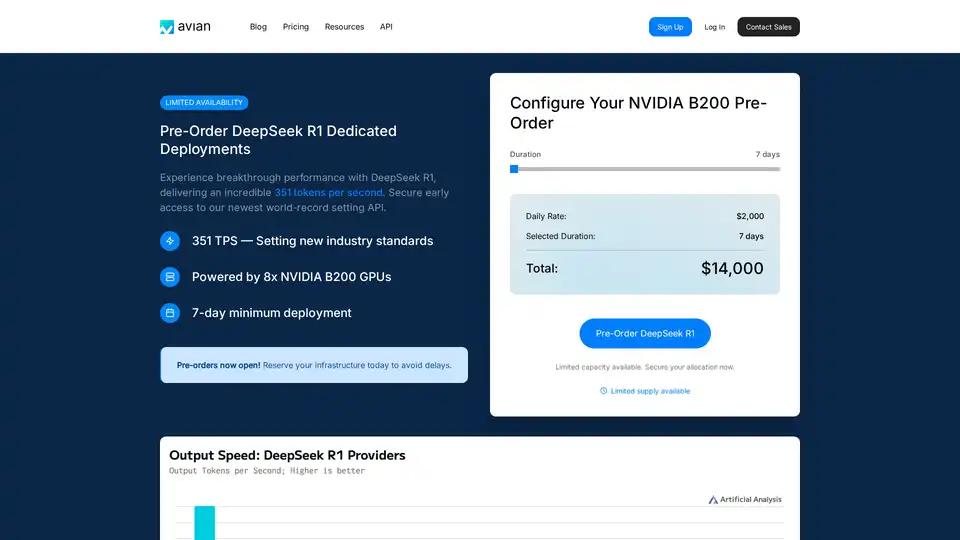
Avian API offre l’inférence d’IA la plus rapide pour les LLM open source, atteignant 351 TPS sur DeepSeek R1. Déployez n’importe quel LLM HuggingFace à une vitesse 3 à 10 fois supérieure grâce à une API compatible OpenAI. Performances et confidentialité de niveau entreprise.
Deep Infra est une plateforme d'inférence IA scalable et économique avec +100 modèles ML comme DeepSeek-V3.2, Qwen et outils OCR. APIs conviviales pour développeurs, location GPU et rétention zéro de données.

GPUX est une plateforme d'inférence GPU sans serveur permettant des démarrages à froid en 1 seconde pour des modèles IA comme StableDiffusionXL, ESRGAN et AlpacaLLM avec des performances optimisées et des capacités P2P.
Nexa SDK permet une inférence IA rapide et privée sur l'appareil pour les modèles LLM, multimodaux, ASR et TTS. Déployez sur les appareils mobiles, PC, automobiles et IoT avec des performances prêtes pour la production sur NPU, GPU et CPU.
FriendliAI est une plateforme d'inférence IA qui offre rapidité, évolutivité et fiabilité pour le déploiement de modèles IA. Il prend en charge plus de 459 400 modèles Hugging Face, offre une optimisation personnalisée et garantit une disponibilité de 99,99 %.

Cloudflare Workers AI vous permet d’exécuter des tâches d’inférence d’IA sans serveur sur des modèles d’apprentissage automatique pré-entraînés sur le réseau mondial de Cloudflare, offrant une variété de modèles et une intégration transparente avec d’autres services Cloudflare.
SaladCloud offre un cloud GPU distribué, abordable, sécurisé et axé sur la communauté pour l'inférence IA/ML. Économisez jusqu'à 90 % sur les coûts de calcul. Idéal pour l'inférence IA, le traitement par lots, etc.
BrainHost VPS propose des serveurs virtuels KVM haute performance avec stockage NVMe, idéal pour l'inférence IA, les sites web et le e-commerce. Provisionnement en 30s à Hong Kong et US West pour un accès global fiable.
Denvr Dataworks fournit des services de calcul IA haute performance, incluant un cloud GPU à la demande, l'inférence IA et une plateforme IA privée. Accélérez votre développement IA avec NVIDIA H100, A100 et Intel Gaudi HPU.
Nebius est une plateforme cloud IA conçue pour démocratiser l'infrastructure IA, offrant une architecture flexible, des performances testées et une valeur à long terme avec des GPU NVIDIA et des clusters optimisés pour l'entraînement et l'inférence.
Awan LLM fournit une plateforme d'API d'inférence LLM illimitée, sans restriction et rentable. Il permet aux utilisateurs et aux développeurs d'accéder à de puissants modèles LLM sans limitations de jetons, idéal pour les agents d'IA, les jeux de rôle, le traitement des données et la complétion de code.