Awan LLM
Vue d'ensemble de Awan LLM
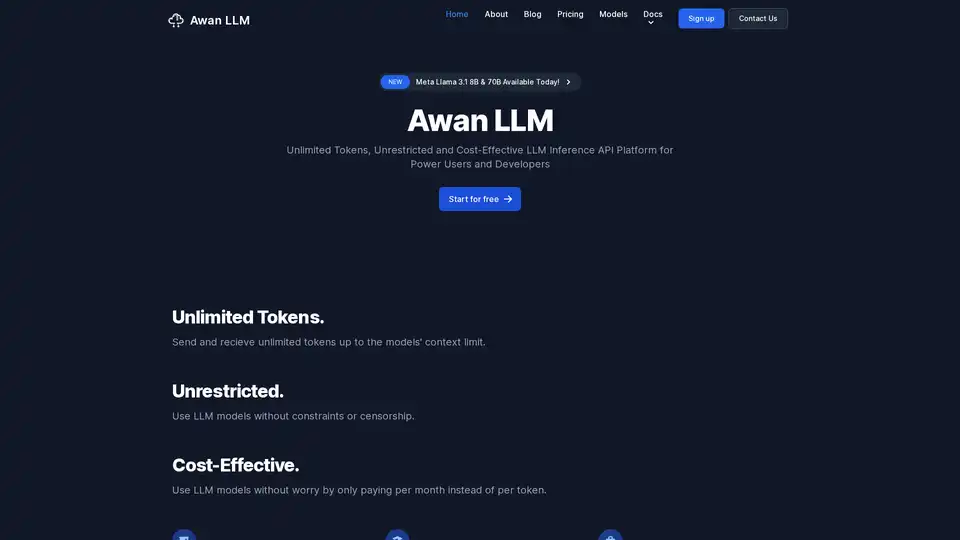
Awan LLM : Libérez la puissance de l’inférence LLM illimitée
Qu’est-ce qu’Awan LLM ? Awan LLM est une plateforme d’API d’inférence LLM (Large Language Model ou grand modèle linguistique) à la pointe de la technologie, conçue pour les utilisateurs expérimentés et les développeurs qui ont besoin d’un accès illimité et de solutions rentables. Contrairement aux modèles de tarification traditionnels basés sur les jetons, Awan LLM offre des jetons illimités, ce qui vous permet de maximiser vos applications d’IA sans vous soucier de l’augmentation des coûts.
Principales caractéristiques et avantages :
- Jetons illimités: Dites adieu aux limites de jetons et bonjour à une créativité et une puissance de traitement illimitées. Envoyez et recevez des jetons illimités dans la limite du contexte des modèles.
- Accès illimité: Utilisez les modèles LLM sans contraintes ni censure. Explorez tout le potentiel de l’IA sans limitations.
- Rentabilité: Bénéficiez d’une tarification mensuelle prévisible au lieu de frais imprévisibles par jeton. Parfait pour les projets ayant des besoins d’utilisation élevés.
Comment fonctionne Awan LLM ?
Awan LLM possède ses propres centres de données et GPU, ce qui lui permet de fournir une génération de jetons illimitée sans les coûts élevés associés à la location de ressources auprès d’autres fournisseurs.
Cas d’utilisation :
- Assistants d’IA: Fournissez une assistance illimitée à vos utilisateurs grâce à un support basé sur l’IA.
- Agents d’IA: Permettez à vos agents de travailler sur des tâches complexes sans vous soucier des jetons.
- Jeu de rôle: Plongez dans des expériences de jeu de rôle illimitées et sans censure.
- Traitement des données: Traitez des ensembles de données massifs de manière efficace et sans restrictions.
- Complétion de code: Accélérez le développement de code avec des complétions de code illimitées.
- Applications: Créez des applications rentables basées sur l’IA en éliminant les coûts des jetons.
Comment utiliser Awan LLM ?
- Inscrivez-vous pour obtenir un compte sur le site Web d’Awan LLM.
- Consultez la page Démarrage rapide pour vous familiariser avec les points de terminaison de l’API.
Pourquoi choisir Awan LLM ?
Awan LLM se distingue des autres fournisseurs d’API LLM en raison de son approche unique de la tarification et de la gestion des ressources. En possédant son infrastructure, Awan LLM peut fournir une génération de jetons illimitée à un coût nettement inférieur à celui des fournisseurs qui facturent en fonction de l’utilisation des jetons. Cela en fait un choix idéal pour les développeurs et les utilisateurs expérimentés qui ont besoin d’une inférence LLM à volume élevé sans contraintes budgétaires.
Questions fréquemment posées :
- Comment pouvez-vous fournir une génération de jetons illimitée ? Awan LLM possède ses propres centres de données et GPU.
- Comment puis-je contacter l’assistance Awan LLM ? Contactez-les à l’adresse contact.awanllm@gmail.com ou utilisez le bouton de contact sur le site Web.
- Conservez-vous des journaux des invites et de la génération ? Non. Awan LLM n’enregistre aucune invite ni génération, comme l’explique sa politique de confidentialité.
- Existe-t-il une limite cachée imposée ? Les limites du taux de requêtes sont expliquées sur la page Modèles et tarification.
- Pourquoi utiliser l’API Awan LLM au lieu d’auto-héberger les LLM ? Cela coûtera beaucoup moins cher que de louer des GPU dans le cloud ou d’exécuter vos propres GPU.
- Que faire si je veux utiliser un modèle qui n’est pas ici ? Contactez Awan LLM pour demander l’ajout du modèle.
À qui s’adresse Awan LLM ?
Awan LLM est idéal pour :
- Les développeurs qui créent des applications basées sur l’IA.
- Les utilisateurs expérimentés qui ont besoin d’une inférence LLM à volume élevé.
- Les chercheurs qui travaillent sur des projets d’IA de pointe.
- Les entreprises qui cherchent à réduire le coût de l’utilisation des LLM.
Grâce à ses jetons illimités, à son accès illimité et à sa tarification rentable, Awan LLM vous permet de libérer tout le potentiel des grands modèles linguistiques. Commencez gratuitement et découvrez l’avenir de l’inférence de l’IA.
Tags Liés à Awan LLM
