PDFMerse
Vue d'ensemble de PDFMerse
PDFMerse : extraction de données PDF optimisée par l’IA pour des flux de travail rationalisés
Qu’est-ce que PDFMerse ? PDFMerse est un outil basé sur l’IA conçu pour transformer les PDF statiques en données dynamiques et exploitables. Il automatise l’extraction d’informations à partir de différents types de PDF, tels que les factures, les dossiers médicaux et les documents juridiques, et les convertit en formats structurés comme JSON, CSV et Excel. Cela élimine la saisie manuelle des données, permet de gagner du temps et d’améliorer la productivité.
Principales fonctionnalités et avantages
- Extraction automatisée: PDFMerse extrait avec précision les données de divers types de PDF, réduisant ainsi les efforts manuels.
- Précision améliorée: Des algorithmes avancés garantissent une grande précision dans l’extraction des données, minimisant ainsi les erreurs.
- Formats de sortie polyvalents: Exportez les données aux formats CSV, JSON et Excel pour une intégration transparente avec les systèmes existants.
- Gain de temps et rentabilité: Réduit considérablement le temps de traitement, permettant aux équipes de se concentrer sur des tâches à plus forte valeur ajoutée.
- RESTful API: Intégrez facilement les fonctionnalités de PDFMerse dans vos applications grâce à la RESTful API.
- Sortie structurée garantie: Recevez les données extraites au format JSON avec une structure garantie.
- Haute performance: Traitez rapidement et efficacement de gros volumes de PDF.
- Prise en charge multilingue : Extrait les données des documents dans plusieurs langues.
- Prise en charge du texte manuscrit : Extrait avec précision les données du texte imprimé et manuscrit.
Comment fonctionne PDFMerse ?
PDFMerse utilise des algorithmes d’IA avancés pour identifier et extraire automatiquement les informations pertinentes des documents PDF. Les utilisateurs peuvent décrire le type de données qu’ils souhaitent extraire, et l’IA génère un modèle de données approprié. Les données extraites sont ensuite fournies dans un format structuré, tel que JSON, prêt à être utilisé immédiatement dans diverses applications et systèmes.
Cas d’utilisation
PDFMerse est applicable dans divers secteurs et scénarios :
- Traitement des factures: Automatisez l’extraction des données des factures, rationalisant ainsi les processus comptables.
- Dossiers médicaux: Extrayez les informations des patients des dossiers médicaux pour une gestion efficace des données.
- Documents juridiques: Traitez les documents juridiques pour extraire les détails et les clauses clés.
- Automatisation de la saisie de données: Réduisez la saisie manuelle de données pour divers types de documents.
Tarification
PDFMerse propose des plans de tarification flexibles pour répondre à différents besoins :
- Gratuit: Accès limité aux fonctionnalités de base, adapté aux personnes qui essaient le service.
- Basique: 5 $/mois, idéal pour les particuliers et les petites équipes, offrant jusqu’à 100 pages/mois.
- Professionnel: 29 $/mois, adapté aux petites entreprises, offrant jusqu’à 1 000 pages/mois et des fonctionnalités avancées.
- Entreprise: 79 $/mois, conçu pour les grandes organisations avec un nombre illimité de pages/mois et une assistance dédiée.
Pourquoi PDFMerse est-il important ?
PDFMerse s’attaque aux défis de l’extraction manuelle des données des PDF, qui prend souvent du temps et est sujette aux erreurs. En automatisant ce processus, PDFMerse permet aux organisations de :
- Gagner du temps et réduire les coûts opérationnels.
- Améliorer la précision et la qualité des données.
- Rationaliser les flux de travail et améliorer la productivité.
- Concentrer les ressources sur les initiatives stratégiques.
Où puis-je utiliser PDFMerse ?
PDFMerse peut être utilisé dans un large éventail de secteurs et d’applications, notamment :
- Comptabilité et finance
- Soins de santé
- Services juridiques
- Logistique et chaîne d’approvisionnement
- Ressources humaines
PDFMerse API
La PDFMerse API permet aux développeurs d’intégrer les fonctionnalités d’extraction de données PDF directement dans leurs applications. L’API offre :
- Intégration facile avec de simples requêtes HTTP
- Sortie structurée garantie au format JSON
- Vitesse et efficacité optimisées pour le traitement de gros volumes de PDF
- Extraction de données sécurisée et fiable
FAQ
- Quels types de PDF PDFMerse peut-il traiter ? PDFMerse peut traiter différents types de PDF, notamment les factures, les dossiers médicaux et les documents juridiques.
- Quelle est la précision de l’extraction des données ? Les algorithmes avancés de PDFMerse garantissent une grande précision dans l’extraction des données, minimisant ainsi les erreurs.
- Quels sont les formats de sortie pris en charge par PDFMerse ? PDFMerse prend en charge plusieurs formats de sortie tels que CSV, JSON et Excel.
- Mes données sont-elles sécurisées avec PDFMerse ? PDFMerse accorde la priorité à la sécurité des données et utilise des mesures de sécurité standard de l’industrie.
- Puis-je créer des modèles d’extraction de données personnalisés ? Oui, PDFMerse vous permet de créer des modèles d’extraction de données personnalisés.
Conclusion
PDFMerse se distingue comme un outil précieux pour les organisations qui cherchent à automatiser l’extraction de données PDF. Ses capacités basées sur l’IA, ses formats de sortie polyvalents et ses plans de tarification flexibles en font un excellent choix pour améliorer la qualité des données, réduire les coûts opérationnels et améliorer l’efficacité globale. En transformant les PDF statiques en données exploitables, PDFMerse permet aux entreprises de libérer la puissance de leurs documents et d’améliorer leur prise de décision.
Meilleurs outils alternatifs à "PDFMerse"
Lido est l'outil alimenté par IA leader pour extraire rapidement et précisément les données de PDFs, factures et documents vers Excel. Éliminez la saisie manuelle avec 99,9 % de précision, compatible avec les fichiers scannés et divers formats—sans formation requise.
Doctly AI extrait du texte, des tableaux, des figures et des graphiques de PDF avec une grande précision, fournissant une sortie structurée en markdown ou JSON pour une intégration transparente dans les applications et workflows IA.
Transformez vos PDF en données JSON structurées grâce à notre puissant outil de conversion basé sur l'IA. Rationalisez votre flux de travail, gagnez du temps et libérez le potentiel de vos documents.
Document Extract est un outil basé sur l'IA qui extrait des données JSON structurées de documents, de PDF et d'images à l'aide de l'OCR. Il offre une intégration facile des API et des SDK pour les développeurs et une tarification à l'utilisation.
AnyParser : LLM de vision pour l'analyse de documents. Extrait avec précision le texte, les tableaux, les graphiques et la mise en page des PDF, PPT et images. Priorise la confidentialité et l'intégration d'entreprise.
DoDocs automatise le traitement des documents avec l'IA. Extrayez les données des factures et des reçus, en vous intégrant aux applications telles que QuickBooks et Zoho.
Transformez sans effort les PDF en données JSON structurées avec PDF Parser, un outil alimenté par l'IA qui automatise l'analyse des PDF. Une meilleure alternative à docparser.com, nanonets.com et parsio.io.
AlgoDocs automatise l'extraction de données à partir de PDF et d'images à l'aide de l'IA, rationalisant ainsi le traitement des documents pour les entreprises. Extrayez des données vers Excel ou des applications intégrées.
Automatisez l'extraction de données et réduisez de 75 % les coûts de saisie de données avec DOConvert, en rationalisant le traitement et l'intégration de tous les types de documents.
La plateforme Talos AI transforme les documents en informations exploitables et améliore les images en fichiers de haute qualité grâce à l'IA. Il offre l'amélioration de l'image, le traitement des données PDF et l'automatisation du codage médical.
Le traitement intelligent de documents (IDP) de super.AI automatise les processus métier de bout en bout, en extrayant des données de documents complexes à l'aide des derniers modèles d'IA, garantissant ainsi la précision et la conformité.
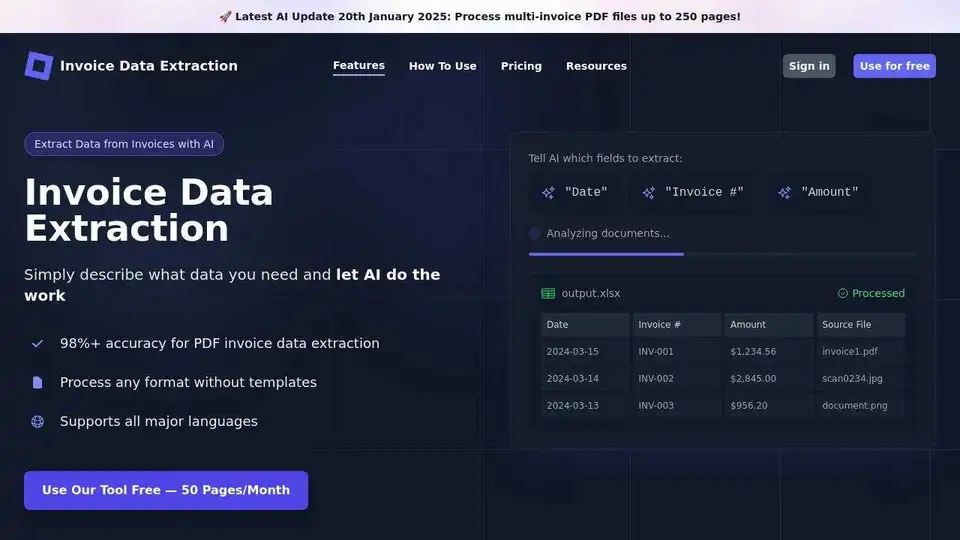
Extrayez automatiquement les données de factures vers Excel avec l'IA. Réduisez les coûts de traitement des factures de plus de 80 %. Approuvé par les entreprises du monde entier.
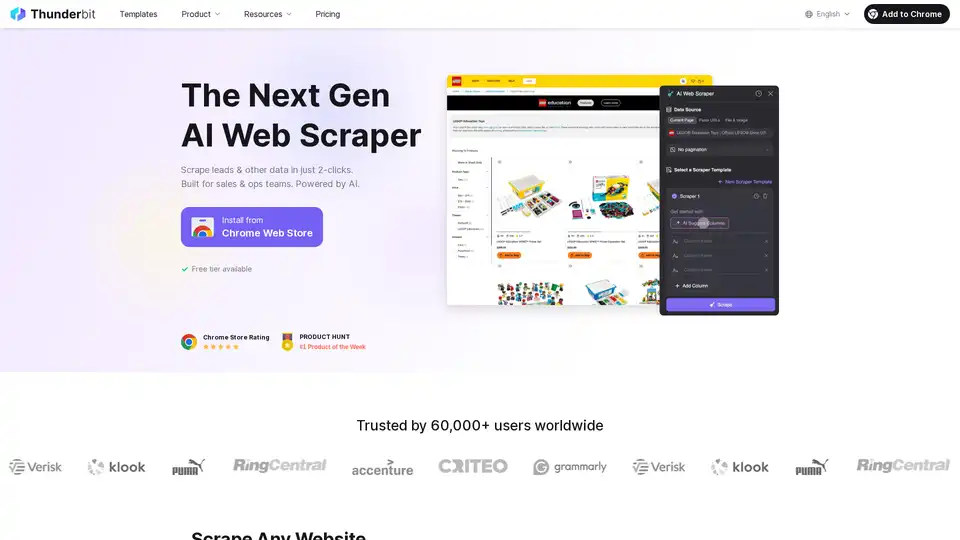
Thunderbit est une extension Chrome alimentée par IA qui extrait des données structurées de n'importe quel site web en seulement 2 clics en utilisant le traitement du langage naturel.
Bank Statement Convert transforme les relevés bancaires PDF en Excel/CSV grâce à l'IA. Automatisez les flux de travail financiers pour les comptables, les teneurs de livres et les professionnels de la finance.