Sagify
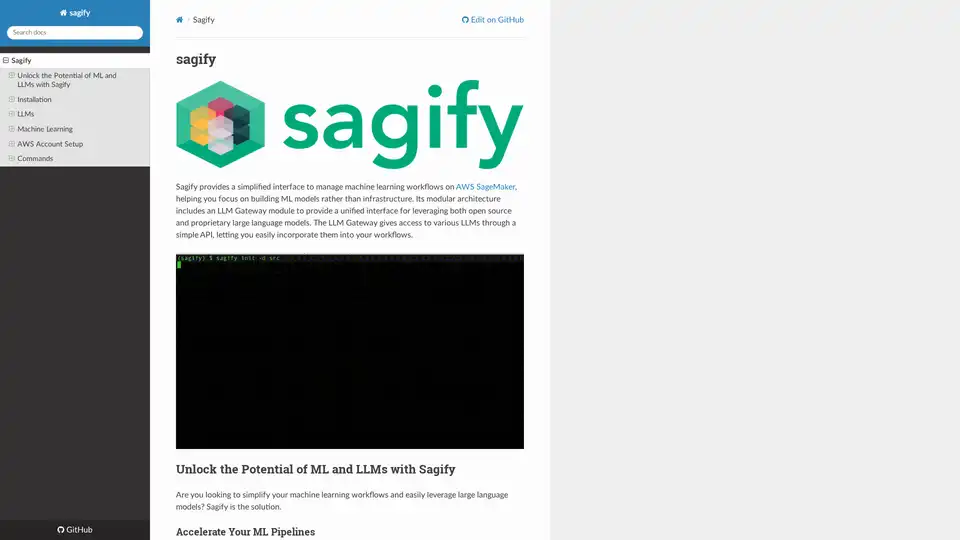
Vue d'ensemble de Sagify
Qu'est-ce que Sagify ?
Sagify est une bibliothèque innovante open-source en Python conçue pour simplifier les complexités des flux de travail de machine learning (ML) et de modèles de langage large (LLM) sur AWS SageMaker. En abstrayant les détails intricats de l'infrastructure cloud, Sagify permet aux scientifiques des données et aux ingénieurs ML de se concentrer sur ce qui compte vraiment : développer et déployer des modèles à fort impact. Que vous entraîniez des classificateurs personnalisés, ajustiez des hyperparamètres ou intégriez des LLMs puissants comme la série GPT d'OpenAI ou des alternatives open-source telles que Llama 2, Sagify fournit une interface modulaire et intuitive qui accélère votre passage du prototype à la production.
Au cœur de Sagify, il exploite les capacités robustes d'AWS SageMaker tout en éliminant le besoin de tâches manuelles de DevOps. Cela en fait un outil essentiel pour les équipes cherchant à exploiter la puissance du ML basé sur le cloud sans s'embourber dans la configuration et la gestion. Avec un support pour les LLMs propriétaires (par exemple, d'OpenAI, Anthropic) et les modèles open-source déployés sur des endpoints SageMaker, Sagify comble l'écart entre l'expérimentation et le déploiement scalable, garantissant que vos projets ML sont efficaces, rentables et innovants.
Comment fonctionne Sagify ?
Sagify opère via une interface en ligne de commande (CLI) et une API Python qui automatisent les étapes clés du cycle de vie du ML. Son architecture est construite autour de la modularité, avec des composants distincts pour les flux de travail ML généraux et un Gateway LLM spécialisé pour gérer les modèles de langage.
Architecture principale pour les flux de travail ML
Pour les tâches ML traditionnelles, Sagify commence par initialiser une structure de projet avec sagify init. Cela crée une disposition de répertoire standardisée, incluant des modules d'entraînement et de prédiction, des configurations Docker et des environnements de test locaux. Les utilisateurs implémentent des fonctions simples comme train() et predict() dans des templates fournis, que Sagify empaquette en images Docker via sagify build.
Une fois construites, ces images peuvent être poussées vers AWS ECR avec sagify push, et l'entraînement commence sur SageMaker en utilisant sagify cloud train. L'outil gère le téléchargement de données vers S3, l'approvisionnement de ressources (par exemple, types d'instances EC2 comme ml.m4.xlarge) et la gestion des sorties. Pour le déploiement, sagify cloud deploy lance des endpoints qui servent les prédictions via des APIs REST, supportant l'inférence en temps réel avec une latence minimale.
Sagify excelle également dans des fonctionnalités avancées comme l'optimisation d'hyperparamètres. En définissant des plages de paramètres dans une configuration JSON (par exemple, pour les noyaux SVM ou les valeurs gamma), les utilisateurs peuvent exécuter des jobs d'ajustement bayésien avec sagify cloud hyperparameter-optimization. Cela automatise les processus d'essai-erreur, en journalisant des métriques comme la précision ou l'exactitude directement depuis votre code d'entraînement en utilisant la fonction log_metric de Sagify. Les instances spot sont supportées pour des économies de coûts sur les jobs plus longs, ce qui le rend idéal pour les tâches intensives en ressources.
La transformation par lots et l'inférence en streaming complètent les capacités ML. Les jobs par lots traitent de grands ensembles de données hors ligne (par exemple, sagify cloud batch-transform), tandis que le streaming expérimental via Lambda et SQS permet des pipelines en temps réel pour des applications comme les recommandeurs.
LLM Gateway : Accès unifié aux modèles de langage large
L'une des fonctionnalités phares de Sagify est le LLM Gateway, une API RESTful basée sur FastAPI qui fournit un point d'entrée unique pour interagir avec divers LLMs. Ce gateway supporte plusieurs backends :
- LLMs propriétaires : Intégration directe avec OpenAI (par exemple, GPT-4, DALL-E pour la génération d'images), Anthropic (modèles Claude) et des plateformes à venir comme Amazon Bedrock ou Cohere.
- LLMs open-source : Déploiement de modèles comme Llama 2, Stable Diffusion ou des modèles d'embedding (par exemple, BGE, GTE) en tant qu'endpoints SageMaker.
Le flux de travail est simple : Déployez des modèles avec des commandes sans code comme sagify cloud foundation-model-deploy pour les modèles de base, ou sagify llm start pour des configs personnalisées. Les variables d'environnement configurent les clés API et les endpoints, et le gateway gère les requêtes pour les complétions de chat, les embeddings et les générations d'images.
Par exemple, pour générer des embeddings en mode batch, préparez des entrées JSONL avec des IDs uniques (par exemple, des recettes pour la recherche sémantique), téléchargez vers S3 et déclenchez sagify llm batch-inference. Les sorties se lient de retour via les IDs, parfait pour peupler des bases de données vectorielles dans les systèmes de recherche ou de recommandation. Les types d'instances supportés comme ml.p3.2xlarge assurent l'évolutivité pour les embeddings de haute dimension.
Les endpoints API reflètent le format d'OpenAI pour une migration facile :
- Complétions de chat : POST vers
/v1/chat/completionsavec des messages, température et tokens max. - Embeddings : POST vers
/v1/embeddingspour des représentations vectorielles. - Générations d'images : POST vers
/v1/images/generationsavec des prompts et des dimensions.
Les options de déploiement incluent des exécutions Docker locales ou AWS Fargate pour la production, avec des templates CloudFormation pour l'orchestration.
Fonctionnalités clés et avantages
Les fonctionnalités de Sagify sont conçues pour rationaliser le développement ML et LLM :
- Automatisation de l'infrastructure : Plus de provisioning manuel — Sagify gère les builds Docker, les pushes ECR, la gestion des données S3 et les jobs SageMaker.
- Tests locaux : Des commandes comme
sagify local trainetsagify local deploysimulent les environnements cloud sur votre machine. - Déploiement éclair : Pour les modèles pré-entraînés (par exemple, scikit-learn, Hugging Face, XGBoost), utilisez
sagify cloud lightning-deploysans code personnalisé. - Surveillance et gestion des modèles : Listez les plateformes et modèles avec
sagify llm platformsousagify llm models; démarrez/arrêtez l'infrastructure à la demande. - Efficacité des coûts : Exploitez les instances spot, le traitement par lots et l'auto-scaling pour optimiser les dépenses AWS.
La valeur pratique est immense. Les équipes peuvent réduire le temps de déploiement de semaines à jours, comme souligné dans la promesse de Sagify : « de l'idée au modèle déployé en une journée seulement ». Cela est particulièrement utile pour l'expérimentation itérative avec les LLMs, où basculer entre fournisseurs (par exemple, GPT-4 pour le chat, Stable Diffusion pour les visuels) nécessiterait autrement des configurations fragmentées.
Les témoignages d'utilisateurs et exemples, comme l'entraînement d'un classificateur Iris ou le déploiement de Llama 2 pour le chat, démontrent la fiabilité. Pour les embeddings, l'inférence par lots sur des modèles comme GTE-large permet des systèmes RAG (Retrieval-Augmented Generation) efficaces, tandis que les endpoints d'images alimentent des apps AI créatives.
Utiliser Sagify : Guide étape par étape
Installation et configuration
Les prérequis incluent Python 3.7+, Docker et AWS CLI. Installez via pip :
pip install sagify
Configurez votre compte AWS en créant des rôles IAM avec des politiques comme AmazonSageMakerFullAccess et en configurant des profils dans ~/.aws/config.
Démarrage rapide pour ML
- Clonez un repo demo (par exemple, classification Iris).
- Exécutez
sagify initpour configurer le projet. - Implémentez les fonctions
train()etpredict(). - Construisez et testez localement :
sagify build,sagify local train,sagify local deploy. - Poussez et entraînez sur le cloud :
sagify push,sagify cloud upload-data,sagify cloud train. - Déployez :
sagify cloud deployet invoquez via curl ou Postman.
Démarrage rapide pour LLMs
- Déployez un modèle :
sagify cloud foundation-model-deploy --model-id model-txt2img-stabilityai-stable-diffusion-v2-1-base. - Définissez les variables d'environnement (par exemple, clés API pour OpenAI).
- Démarrez le gateway :
sagify llm gateway --start-local. - Interrogez les APIs : Utilisez curl, requests Python ou fetch JS pour les complétions, embeddings ou images.
Pour l'inférence par lots, préparez des fichiers JSONL et exécutez sagify llm batch-inference.
Pourquoi choisir Sagify pour vos projets ML et LLM ?
Dans un paysage encombré de frameworks ML, Sagify se distingue par ses optimisations spécifiques à SageMaker et son unification des LLMs. Il aborde les points de douleur courants comme la surcharge d'infrastructure et la fragmentation des modèles, permettant une innovation plus rapide. Idéal pour les startups scalant des prototypes AI ou les entreprises construisant des apps LLM de production, la nature open-source de Sagify favorise les contributions communautaires, avec un support continu pour de nouveaux modèles (par exemple, Mistral, Gemma).
Pour qui ? Scientifiques des données fatigués du code boilerplate, ingénieurs ML cherchant l'automatisation, et développeurs AI expérimentant avec les LLMs. En se concentrant sur la logique du modèle plutôt que sur les ops, Sagify permet aux utilisateurs de livrer des solutions impactantes — que ce soit la recherche sémantique, l'art génératif ou l'analytique prédictive — tout en respectant les meilleures pratiques pour des déploiements AWS sécurisés et scalables.
Pour les meilleurs résultats dans les flux de travail ML ou les intégrations LLM, commencez avec Sagify dès aujourd'hui. Son mélange de simplicité et de puissance en fait l'outil de choix pour débloquer tout le potentiel d'AWS SageMaker.
Meilleurs outils alternatifs à "Sagify"
Nyckel vous permet de créer, de déployer et d'intégrer rapidement des modèles ML personnalisés. Il simplifie le processus, le rendant accessible sans nécessiter de doctorat, et se concentre sur la précision, la sécurité et la facilité d'utilisation.
Kortical est une plateforme d'IA conçue pour les data scientists, offrant des capacités AutoML et ML Ops pour créer et déployer rapidement des solutions d'IA de niveau entreprise. Il prend en charge les interfaces de code et d'interface utilisateur, ce qui favorise une itération plus rapide et de meilleures performances du modèle.
Agent Herbie est un agent IA hors ligne conçu pour les opérations en temps réel et critiques dans des environnements privés. Il exploite les LLM, SLM et ML pour une flexibilité et une fiabilité inégalées sans sortie de données.
finbots.ai CreditX est une plateforme de risque de crédit IA offrant des tableaux de bord personnalisés, un déploiement rapide et des prêts plus intelligents. Il aide les prêteurs à augmenter les approbations, à réduire les taux de perte et à améliorer l'efficacité opérationnelle.
Weco AI automatise les expériences d'apprentissage automatique en utilisant la technologie AIDE ML, optimisant les pipelines ML grâce à l'évaluation de code pilotée par IA et l'expérimentation systématique pour améliorer les métriques de précision et de performance.
Un studio d'entreprise de nouvelle génération pour les constructeurs d'IA qui forment, valident, ajustent et déploient des modèles d'IA. Découvrez les outils intégrés d'IBM watsonx.ai pour un développement d'IA générative évolutif.

Inferless propose une inférence GPU sans serveur ultra-rapide pour déployer des modèles ML. Il offre un déploiement évolutif et facile de modèles d'apprentissage automatique personnalisés avec des fonctionnalités comme la mise à l'échelle automatique, le traitement par lots dynamique et la sécurité d'entreprise.

Quantum Copilot est un outil assisté par IA pour l'informatique quantique, permettant de programmer en langage simple, de générer du code quantique, de simuler des circuits et d'exécuter sur du matériel réel pour débutants et experts.
Qubinets est une plateforme open source simplifiant le déploiement et la gestion de l'infrastructure d'IA et de big data. Construisez, connectez et déployez facilement. Concentrez-vous sur le code, pas sur les configurations.

Perpetual ML est un studio tout-en-un pour l'apprentissage automatique à grande échelle, offrant AutoML, apprentissage continu, suivi d'expériences, déploiement de modèles et surveillance des données, intégré nativement à Snowflake.
Thordata offre des proxies résidentiels de haute qualité pour un web scraping de données transparent, parfait pour l'IA, la BI et les workflows. Accédez à plus de 60 millions d'IP avec une facturation basée sur le trafic et des performances fiables.
Deployo simplifie le déploiement des modèles d'IA, transformant les modèles en applications prêtes pour la production en quelques minutes. Infrastructure d'IA agnostique du cloud, sécurisée et évolutive pour un flux de travail d'apprentissage automatique sans effort.

FinetuneFast : Lancez rapidement vos modèles d’IA. Le modèle pour lancer rapidement vos modèles d’IA. Inclut les applications RAG.
Flyte orchestre des flux de travail IA/ML durables, flexibles et natifs de Kubernetes. Utilisé par plus de 3 000 équipes pour la création et le déploiement de pipelines évolutifs.