
FramePack の概要
FramePack:コンシューマーGPUでのビデオ生成に革命を
FramePackとは? FramePackは、コンシューマーグレードのGPUで高品質なビデオ生成を可能にするように設計された、画期的なオープンソースのビデオ拡散技術です。必要なVRAMはわずか6GBです。革新的なフレームコンテキストパッキングアプローチを採用し、AIビデオの作成をこれまで以上にアクセスしやすくします。
主な機能と利点:
- 低VRAM要件: わずか6GBのVRAMで、ラップトップやミッドレンジシステムで高品質のビデオを生成します。
- アンチドリフト技術: FramePackの両方向サンプリングアプローチを使用して、長いビデオシーケンス全体で一貫した品質を維持します。
- ローカル実行: クラウド処理や高価なGPUレンタルを必要とせずに、ハードウェア上で直接ビデオを生成します。
FramePackの仕組み
FramePackは、高品質のビデオコンテンツを生成するための直感的なワークフローを提供します。
- インストールとセットアップ: GitHub経由でインストールし、環境をセットアップします。
- 初期フレームの定義: 画像から開始するか、テキストプロンプトから画像を生成して、ビデオシーケンスを開始します。
- モーションプロンプトの作成: 自然言語で目的の動きとアクションを記述して、ビデオ生成をガイドします。
- 生成とレビュー: FramePackが印象的な時間的一貫性でフレームごとにビデオを生成するのを見てください。
コアテクノロジーの説明
- フレームコンテキストパッキング: フレームコンテキスト情報を効率的に圧縮して利用し、コンシューマーハードウェアでの処理を可能にします。これは、FramePackの低VRAM要件の鍵です。
- ローカルビデオ生成: データを外部サーバーに送信せずに、デバイス上で直接ビデオを生成し、プライバシーと制御を確保します。
- 両方向サンプリング: アンチドリフト技術により、長いビデオシーケンス全体で一貫性を維持します。これにより、ビデオの品質が時間の経過とともに低下するのを防ぎます。
- 最適化されたパフォーマンス: Teacache最適化を備えたハイエンドGPUで、フレームあたり約1.5秒でフレームを生成します。ローエンドハードウェアでも、プロトタイピングに使用できるパフォーマンスです。
- オープンソースアクセス: カスタマイズとコミュニティの貢献を可能にする、完全にオープンソースの実装から恩恵を受けます。これにより、イノベーションが促進され、長期的なサポートが保証されます。
- マルチモーダル入力: テキストプロンプトと画像入力の両方を使用して、ビデオ生成をガイドし、クリエイティブプロセスに対する柔軟性と制御を提供します。
FramePackが重要な理由
FramePackは、ハードウェアリソースが限られているユーザーでもアクセスできるようにすることで、AIビデオ生成を民主化します。ビデオ生成をローカルで実行できることは、プライバシーを重視するユーザーや、インターネット帯域幅が限られているユーザーにとって大きな利点です。FramePackのオープンソースの性質は、コミュニティのコラボレーションと継続的な改善を促進します。
ユーザーの声
- Emily Johnson、独立アニメーター: 「FramePackは、アニメーションの作成方法を変えました。ラップトップで高品質のビデオを生成できるということは、どこからでも作業できるということであり、結果はクライアントのプレゼンテーションに十分なほど印象的です。」
- Michael Rodriguez、VFXスペシャリスト: 「複数のクリエイティブチームと協力している人として、FramePackはゲームチェンジャーでした。レンダーファームを待つことなくビデオコンセプトをプロトタイプ化する、高速で効率的な方法を提供し、制作時間を大幅に節約できます。」
- Sarah Chen、AI研究者: 「このツールは、ビデオ生成の研究に対するアプローチを変えました。FramePackの革新的なフレームコンテキストパッキングにより、標準的な実験装置でより長いシーケンスを試すことができ、研究サイクルを大幅に加速できます。」
よくある質問
- FramePackとは正確には何であり、どのように機能しますか? FramePackは、コンシューマーGPUで次フレーム予測を可能にするオープンソースのビデオ拡散技術です。フレームコンテキスト情報を効率的にパッキングし、固定長の入力形式を使用することで、VRAMが限られているハードウェアでも高品質のビデオをフレームごとに生成できます。
- FramePackのシステム要件は何ですか? FramePackには、少なくとも6GBのVRAM(RTX 3060など)、CUDAサポート、PyTorch 2.6+を備えたNVIDIA GPUが必要で、WindowsまたはLinuxで実行できます。最適なパフォーマンスを得るには、8GB以上のVRAMを備えたRTX 30または40シリーズGPUを推奨します。
- FramePackはどれくらいの速さでビデオを生成できますか? RTX 4090などのハイエンドGPUでは、FramePackはTeacache最適化を使用してフレームあたり約1.5秒でフレームを生成できます。6GBのVRAMを搭載したラップトップでは、生成は4〜8倍遅くなりますが、プロトタイピングには依然として使用できます。
- FramePackは無料で使用できますか? FramePackは、すべての機能を備えた無料のオープンソースバージョンを提供しています。プレミアムティアでは、プロのユーザーとチーム向けに追加機能、優先サポート、および拡張機能を提供する場合があります。
- FramePackの「フレームコンテキストパッキング」とは何ですか? フレームコンテキストパッキングは、以前のフレームからの情報を固定長の形式に効率的に圧縮するFramePackの中核的なイノベーションです。これにより、モデルはビデオの長さが増加してもメモリを増やすことなく時間的な一貫性を維持できます。
- FramePackは他のビデオ生成ツールと比較してどうですか? クラウドベースのソリューションとは異なり、FramePackはハードウェア上で完全にローカルに実行されます。一部のクラウドサービスはより高速な生成を提供する可能性がありますが、FramePackは優れたプライバシー、使用制限なし、および一貫した品質でより長いシーケンスを生成する機能を提供します。
結論
FramePackは、AIビデオ生成における重要な一歩を表しています。低VRAM要件、オープンソースの性質、および革新的なフレームコンテキストパッキング技術により、アマチュアとプロの両方にとって貴重なツールとなっています。アニメーションの作成、ビデオコンセプトのプロトタイプ作成、または研究の実施のいずれの場合でも、FramePackは、コンシューマーGPUで高品質のビデオを生成するための高速、効率的、かつアクセス可能なソリューションを提供します。ローカルマシンでビデオを生成する最良の方法は何ですか?FramePackは間違いなく有力候補です。
"FramePack" のベストな代替ツール
Emu Videoは、MetaのAI駆動テキストからビデオへのツールで、拡散モデルを活用してテキストプロンプトから高品質のビデオを生成します。分解された生成アプローチを使用して、16fpsで4秒のビデオを効率的に作成します。

Mind-Video は、fMRI を介してキャプチャされた脳活動からビデオを再構築するために AI を使用します。この革新的なツールは、マスクされた脳モデリング、マルチモーダルなコントラスト学習、および時空間的注意を組み合わせて、高品質のビデオを生成します。
MAGI-1は、最高レベルの品質と完全な制御を備えた初のオープンソースの自己回帰ビデオ生成モデルです。素晴らしいAIビデオを簡単に作成できます。今すぐお試しください!
DreamFace の無料 AI ツールで創造性を高めましょう! 素晴らしい AI ビデオ、画像、アバターをすばやく生成します。 ビデオ編集、顔交換、写真のエンハンスメントに最適です。
Lumiereは、Google Researchによるビデオ生成のための時空間拡散モデルです。テキストからビデオ、画像からビデオ、ビデオのスタイル化、シネマグラフ、インペインティングをサポートし、リアルで一貫性のあるモーションを生成します。
NightCafeを発見、最強の無料AIアート生成器でFluxやDALL-E 3などのトップモデル、活気あるコミュニティ、デイリーチャレンジで終わりのない創造性を。
Fast3Dを発見してください。AI駆動のソリューションで、テキストと画像から数秒で高品質な3Dモデルを生成します。機能、ゲームへの応用、将来のトレンドを探求します。
MotionAgent はオープンソースの AI ツールで、Qwen-7B-Chat や SDXL などのモデルを使用して、アイデアを動く映画に変換します。スクリプト、映画の静止画、高解像度ビデオ、カスタム背景音楽を生成します。
FluxAPI.ai は、テキストから画像と画像編集のための Flux.1 スイート全体に高速で柔軟なアクセスを提供します。Kontext Pro が 0.025 ドル、Kontext Max が 0.05 ドルで、同じモデルを低コストで楽しめます—AI 画像生成をスケーリングする開発者とクリエイターに最適。
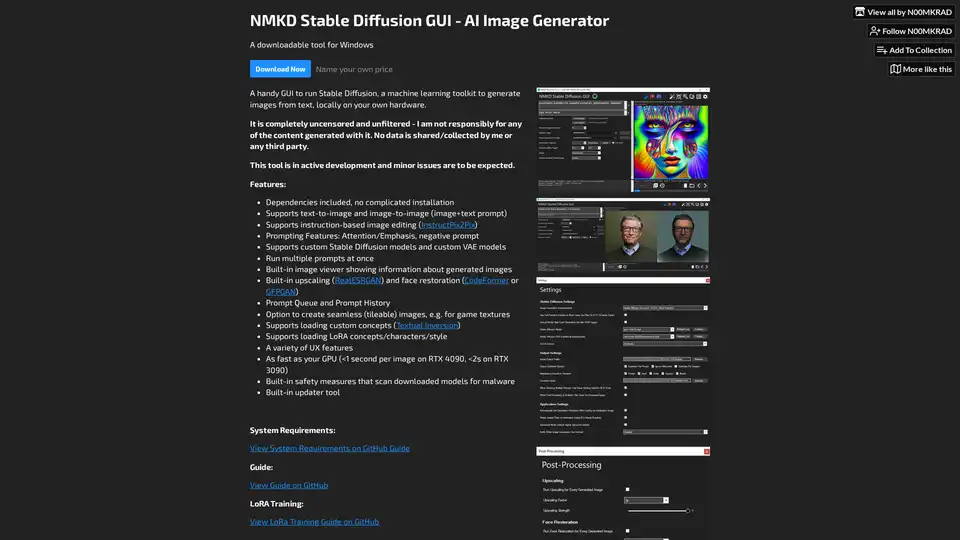
NMKD Stable Diffusion GUI は、Stable Diffusion を使用して GPU でローカルに AI 画像を生成する無料のオープンソースツールです。テキストから画像、画像編集、上スケーリング、LoRA モデルをサポートし、検閲やデータ収集はありません。

Skelet AIを発見、あなたのオールインワンプラットフォームで、AI駆動のコンテンツ生成、驚くべき画像、および80言語以上の自然なテキスト-to-スピーチを生成。無料プランあり、プレミアムアップグレードでHD機能。

Stable Video 3D(SV3D)を使用して、単一の画像からマルチビュー3Dモデルを生成します。高品質で一貫性のある3D視覚化のためにStable Video Diffusionを利用しています。
ToonCrafter AI を使用して、写真を魅力的な漫画に変換します。これは、シームレスな漫画の補間とビデオ生成のためのオープンソースの AI ツールです。アニメーション愛好家やクリエイティブ ディレクターに最適です。
Wan 2.2は、Alibabaの最先端AI動画生成モデルであり、現在オープンソースです。映画のようなビジョン制御を提供し、テキストからビデオおよび画像からビデオの生成をサポートし、効率的な高解像度ハイブリッドTI2Vを提供します。