Emu Video の概要
Emu Video: MetaによるAIテキストから動画生成
Emu Videoとは?
Emu Videoは、Meta AIによって開発された、テキストプロンプトから動画を生成するための最先端のAIツールです。1秒あたり16フレーム(fps)で高品質な4秒の動画を作成できることで際立っています。
Emu Videoはどのように機能するのですか?
Emu Videoは、拡散モデルに基づく因子化された生成アプローチを採用しています。このプロセスは、次の2つの主要なステップに分かれています。
- 画像生成: まず、システムは提供されたテキストプロンプトに基づいて画像を生成します。
- 動画生成: 次に、最初のテキストプロンプトと生成された画像の両方を条件として動画を生成します。
この因子化されたアプローチにより、Emu Videoは非常に効率的になり、512pxの動画を生成するために必要な拡散モデルは2つだけです。
主な機能と利点
- 高品質の出力: Emu Videoは、印象的な視覚的忠実度と一貫性を持つ動画を生成します。
- 効率: 因子化された生成方法により、効率的なトレーニングと動画作成が可能です。
- 最先端のパフォーマンス: Emu Videoは、人間の評価者によって決定されたように、品質とプロンプトへの忠実度の両方において、他のテキストから動画生成モデルよりも優れています。
パフォーマンスの比較
最先端のモデルに対する評価において、Emu Videoは一貫して優れた結果を提供しました。Make-a-Video (MAV)、Imagen-Video (Imagen)、Align Your Latents (AYL)、Reuse & Diffuse (R&D)、Cog Video (Cog)、Gen2、Pika Labsなどのモデルと比較されました。
Emu Videoは誰のためのものですか?
Emu Videoは、以下のような場合に最適です。
- AI研究者: テキストから動画生成の機能を探索する。
- コンテンツクリエーター: テキストの説明から動画コンテンツを作成する。
- クリエイティブプロフェッショナル: 新しい視覚表現の形式を試す。
実際のアプリケーション
Emu Videoは、以下を含むさまざまな目的に使用できます。
- **ソーシャルメディア用の短いビデオクリップを生成する。
- プレゼンテーションおよびマーケティング資料用の視覚コンテンツを作成する。
- 教育用ビデオとチュートリアルを開発する。
謝辞
Emu Videoの開発は、多数の協力者によってサポートされました。Meta AIは、データ収集、インフラストラクチャ、および役立つ議論に貢献してくれた個人に感謝の意を表します。その中には、Baixue Zheng、Baishan Guo、Jeremy Teboul、Milan Zhou、Shenghao Lin、Kunal Pradhan、Jort Gemmeke、Jacob Xu、Dingkang Wang、Samyak Datta、Guan Pang、Symon Perriman、Vivek Pai、Shubho Sengupta、Uriel Singer、Adam Polyak、Shelly Sheynin、Yaniv Taigman、Licheng Yu、Luxin Zhang、Yinan Zhao、David Yan、Yaqiao Luo、Xiaoliang Dai、Zijian He、Peizhao Zhang、Peter Vajda、Roshan Sumbaly、Armen Aghajanyan、Michael Rabbat、Michal Drozdzalが含まれます。チームはまた、Lauren Cohen、Mo Metanat、Lydia Baillergeau、Amanda Felix、Ana Paula Kirschner Mofarrej、Kelly Freed、Somya Jain、Ahmad Al-Dahle、Manohar Paluriからのサポートに感謝しています。
結論
Emu Videoは、AI主導の動画生成における大きな進歩を表しています。その因子化されたアプローチ、高品質の出力、および最先端のパフォーマンスにより、研究者、コンテンツクリエーター、およびクリエイティブプロフェッショナルにとって価値のあるツールとなっています。Emu Videoを使用することで、Meta AIはAIと動画テクノロジーで可能なことの境界を押し広げ続けています。
"Emu Video" のベストな代替ツール
Lumiereは、Google Researchによるビデオ生成のための時空間拡散モデルです。テキストからビデオ、画像からビデオ、ビデオのスタイル化、シネマグラフ、インペインティングをサポートし、リアルで一貫性のあるモーションを生成します。
オールインワンAIクリエーションツール:テキスト、画像、ビデオ、デジタルヒューマン作成のためのワンストップAIプラットフォーム。高度なAI機能でアイデアを素早く驚くべきビジュアルに変身。
先進的なオンラインAIビデオジェネレーターで、テキスト、画像、または参照から簡単に素晴らしいAIビデオを作成。100%無料で使いやすい。

Klyra AIは、ビデオ、ボイスオーバー、画像、ブログ、音楽などを先進的なAIツールで作成する究極のオールインワン・プラットフォームです。シームレスなコンテンツ自動化と強力な機能で生産性を向上させます。
AnimateDiffは、AI生成のビジュアルに動きを加える無料のオンラインビデオメーカーです。テキストプロンプトからアニメーションを作成したり、既存の画像を実際のビデオから学んだ自然な動きでアニメーション化したりできます。このプラグアンドプレイフレームワークは、Stable Diffusionのような拡散モデルにビデオ機能を追加し、再トレーニング不要です。AnimateDiffのテキスト-to-ビデオと画像-to-ビデオ生成ツールで、AIコンテンツ作成の未来を探求しましょう。

DeepAIは、テキストから画像への生成、AIビデオ作成、音楽作曲、写真編集、音声チャット機能を提供する総合的なクリエイティブAIプラットフォームです。ブラウザで即時に利用可能で、無料アクセスとProオプションを提供します。
Media.ioのAIビデオジェネレーターで、数秒でアイデアをビデオに変換します。テキストを入力するか画像をアップロードするだけで、水印なしの魅力的なビデオを作成—100%無料。
Mochi AIは、テキストプロンプトから高忠実度のビデオを作成するオープンソースのビデオ生成モデルです。 100億のパラメータを持つ拡散モデルを使用し、商用利用が可能です。

FramePackを使用すると、わずか6GBのVRAMでコンシューマーGPU上で高品質のビデオを生成できます。このオープンソースのビデオ拡散テクノロジーは、フレームコンテキストパッキングを使用して、高速なローカル実行を実現します。

TextToVideo.Bot:AI搭載のビデオエディターで、テキストをバイラルショートビデオに瞬時に変換します。あらゆるデバイスであらゆるニッチ向けの顔のないビデオを作成します。
Mochi 1 は、Genmo によるオープンソースの AI ビデオジェネレーターで、ユーザーはテキストプロンプトから高品質のビデオを作成できます。無料でカスタマイズ可能で、コンテンツクリエーターに最適です。
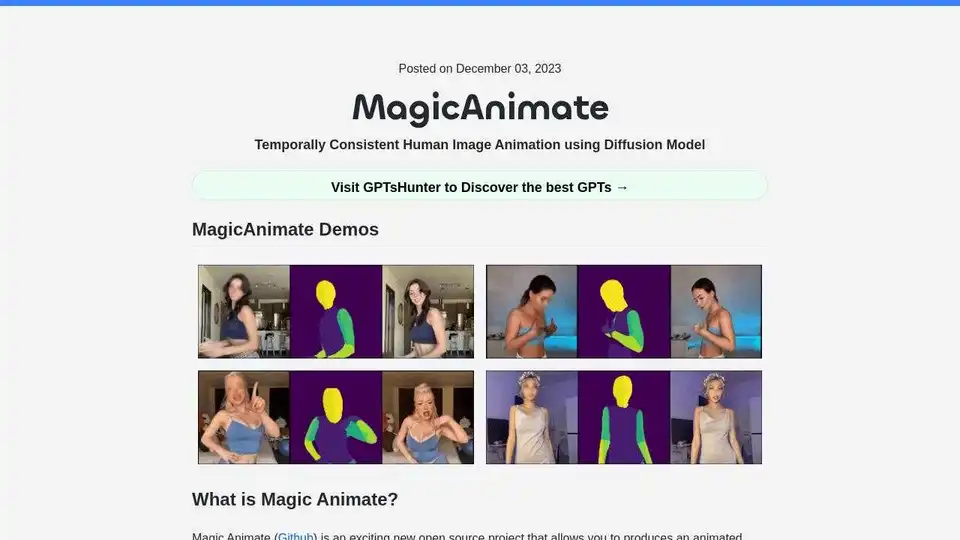
MagicAnimateは、単一の画像とモーションビデオから時間的に一貫性のある人物画像アニメーションを作成するための、拡散ベースのオープンソースフレームワークです。忠実度を高めたアニメーションビデオを生成します。
Wan 2.2は、Alibabaの最先端AI動画生成モデルであり、現在オープンソースです。映画のようなビジョン制御を提供し、テキストからビデオおよび画像からビデオの生成をサポートし、効率的な高解像度ハイブリッドTI2Vを提供します。
Flux AIは、高度なAI画像およびビデオ生成ツールを提供します。 テキストから画像へ、画像からビデオへのテクノロジーを使用して、驚くほど美しいビジュアルを作成します。 Flux Kontext AIとFlux.1 AIモデルを無料でお試しください。