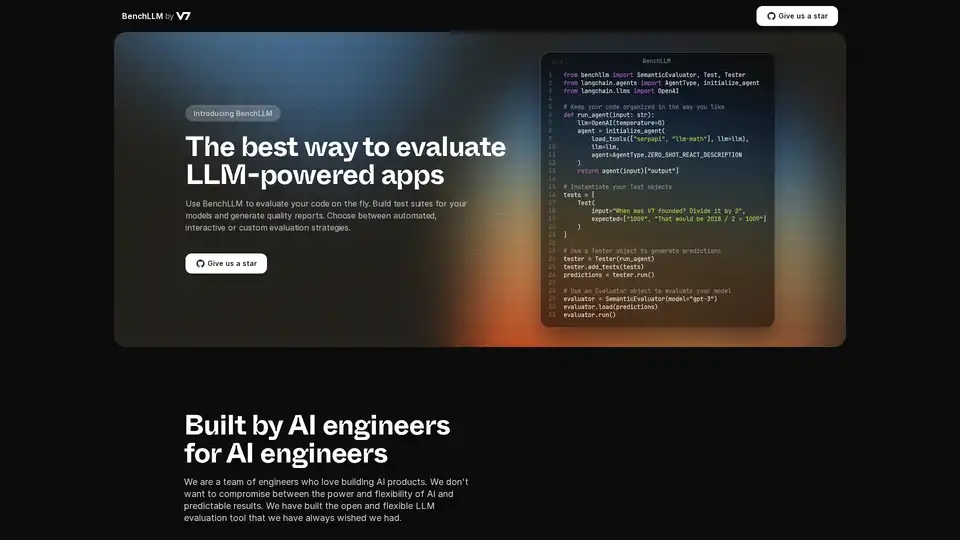
BenchLLM の概要
BenchLLMとは?
BenchLLMは、大規模言語モデル(LLM)を搭載したアプリケーションの性能と品質を評価するために設計されたツールです。テストスイートの構築、品質レポートの生成、モデルのパフォーマンスの監視のための柔軟で包括的なフレームワークを提供します。自動化された、インタラクティブな、またはカスタムの評価戦略が必要な場合でも、BenchLLMは、AIモデルが必要な基準を満たすことを保証する機能と能力を提供します。
BenchLLMの仕組み
BenchLLMは、ユーザーがテストを定義し、それらのテストに対してモデルを実行し、結果を評価できるようにすることで機能します。詳細な内訳は次のとおりです。
- 直感的にテストを定義: テストはJSONまたはYAML形式で定義できるため、テストケースのセットアップと管理が簡単になります。
- テストをスイートに整理: 簡単なバージョン管理と管理のために、テストをスイートに整理します。これは、モデルの進化に合わせてさまざまなバージョンのテストを維持するのに役立ちます。
- テストの実行: 強力なCLIまたは柔軟なAPIを使用して、モデルに対してテストを実行します。BenchLLMは、OpenAI、Langchain、およびその他のAPIをすぐにサポートしています。
- 結果の評価: BenchLLMは、モデルのパフォーマンスを評価するための複数の評価戦略を提供します。これにより、本番環境でのリグレッションを特定し、経時的なモデルのパフォーマンスを監視できます。
- レポートの生成: 評価レポートを生成し、チームと共有します。これらのレポートは、モデルの長所と短所に関する洞察を提供します。
コードスニペットの例:
LangchainでBenchLLMを使用する方法の例を次に示します。
from benchllm import SemanticEvaluator, Test, Tester
from langchain.agents import AgentType, initialize_agent
from langchain.llms import OpenAI
## Keep your code organized in the way you like
def run_agent(input: str):
llm=OpenAI(temperature=0)
agent = initialize_agent(
load_tools(["serpapi", "llm-math"], llm=llm),
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
return agent(input)["output"]
## Instantiate your Test objects
tests = [
Test(
input="When was V7 founded? Divide it by 2",
expected=["1009", "That would be 2018 / 2 = 1009"]
)
]
## Use a Tester object to generate predictions
tester = Tester(run_agent)
tester.add_tests(tests)
predictions = tester.run()
## Use an Evaluator object to evaluate your model
evaluator = SemanticEvaluator(model="gpt-3")
evaluator.load(predictions)
evaluator.run()
OpenAIのChatCompletion APIでBenchLLMを使用する方法の例を次に示します。
import benchllm
from benchllm.input_types import ChatInput
import openai
def chat(messages: ChatInput):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0].message.content.strip()
@benchllm.test(suite=".")
def run(input: ChatInput):
return chat(input)
主な機能と利点
- 柔軟なAPI: OpenAI、Langchain、およびその他のAPIのサポートにより、コードをその場でテストします。
- 強力なCLI: シンプルなCLIコマンドでモデルを実行および評価します。CI/CDパイプラインに最適です。
- 簡単な評価: JSONまたはYAML形式で直感的にテストを定義します。
- 自動化: CI/CDパイプライン内で評価を自動化して、継続的な品質を確保します。
- 洞察に満ちたレポート: 評価レポートを生成および共有して、モデルのパフォーマンスを監視します。
- パフォーマンスの監視: モデルのパフォーマンスを監視して、本番環境でのリグレッションを検出します。
BenchLLMの使用方法
- インストール: BenchLLMをダウンロードしてインストールします。
- テストの定義: JSONまたはYAMLでテストスイートを作成します。
- 評価の実行: CLIまたはAPIを使用して、LLMアプリケーションに対してテストを実行します。
- レポートの分析: 生成されたレポートを確認して、改善の余地がある領域を特定します。
BenchLLMは誰のためのものですか?
BenchLLMは、LLMを搭載したアプリケーションの品質と信頼性を確保したいAIエンジニアおよび開発者向けに設計されています。特に、次の用途に役立ちます。
- AIエンジニア: AI製品を構築および保守する人。
- 開発者: LLMをアプリケーションに統合します。
- チーム: AIモデルのパフォーマンスを監視および改善しようとしています。
BenchLLMを選ぶ理由
BenchLLMは、LLMアプリケーションを評価するための包括的なソリューションを提供し、柔軟性、自動化、および洞察に満ちたレポートを提供します。予測可能な結果を提供する強力で柔軟なツールを必要とするAIエンジニアによって構築されています。BenchLLMを使用すると、次のことができます。
- LLMアプリケーションの品質を確保します。
- 評価プロセスを自動化します。
- モデルのパフォーマンスを監視し、リグレッションを検出します。
- 洞察に満ちたレポートでコラボレーションを改善します。
BenchLLMを選択することで、AIモデルを評価し、最高のパフォーマンスと品質基準を満たすことを保証するための堅牢で信頼性の高いソリューションを選択することになります。
"BenchLLM" のベストな代替ツール

Confident AIはDeepEval上に構築されたLLM評価プラットフォームで、エンジニアリングチームがLLMアプリケーションの性能をテスト、ベンチマーク、保護、向上させることを可能にします。AIシステムを最適化し、リグレッションを捕捉するための最高クラスのメトリクス、ガードレール、およびオブザーバビリティを提供します。

Openlayerは、MLからLLMまでのAIシステムに統一されたAI評価、可観測性、ガバナンスを提供するエンタープライズAIプラットフォームです。AIライフサイクル全体を通じてAIシステムをテスト、監視、管理します。
UpTrainは、LLMアプリケーションを評価、実験、監視、テストするためのエンタープライズグレードのツールを提供するフルスタックLLMOpsプラットフォームです。独自の安全なクラウド環境でホストし、自信を持ってAIを拡張します。
Freeplayは、プロンプト管理、評価、可観測性、およびデータレビューワークフローを通じて、チームがAI製品を構築、テスト、および改善するのに役立つように設計されたAIプラットフォームです。 AI開発を合理化し、高品質の製品を保証します。

Parea AIは、チームがLLMアプリケーションを自信を持ってリリースするのに役立つAI実験およびアノテーションプラットフォームです。実験の追跡、可観測性、ヒューマンレビュー、プロンプトのデプロイメントなどの機能を提供します。
Future AGI は、AI アプリケーション向けの統一された LLM 可観測性と AI エージェント評価プラットフォームを提供し、開発から生産まで正確で責任ある AI を保証します。

Bolt Foundryは、AIの動作を予測可能かつテスト可能にするためのコンテキストエンジニアリングツールを提供し、信頼できるLLM製品の構築を支援します。コードをテストするのと同じようにLLMをテストします。
HoneyHiveは、LLMアプリケーションを構築するチームにAI評価、テスト、監視ツールを提供します。 統合されたLLMOpsプラットフォームを提供します。
LangWatchは、AIエージェントのテスト、LLM評価、およびLLM可観測性プラットフォームです。エージェントをテストし、回帰を防ぎ、問題をデバッグします。
Mindgardの自動レッドチームとセキュリティテストでAIシステムを保護します。 AI固有のリスクを特定して解決し、堅牢なAIモデルとアプリケーションを保証します。
Arize AIは、開発から生産まで、AIアプリケーション向けの統一されたLLM可観測性およびエージェント評価プラットフォームを提供します。プロンプトの最適化、エージェントの追跡、AIパフォーマンスのリアルタイム監視を行います。
Label Studioは、LLMの微調整、トレーニングデータの準備、AIモデルの評価のための柔軟なオープンソースデータラベリングプラットフォームです。テキスト、画像、オーディオ、ビデオなど、さまざまなデータ型をサポートしています。
VelvetはArizeに買収され、AI機能を分析、評価、監視するための開発者ゲートウェイを提供していました。Arizeは、AIの開発を加速するのに役立つ、AI評価と可観測性のための統合プラットフォームです。
Abacus.AIは、生成AI技術を基盤とする世界初のAIスーパーアシスタントです。企業やプロフェッショナル向けに、カスタムチャットボット、AIワークフロー、予測モデリングを提供し、ビジネス全体を自動化します。