ExLlama
Übersicht von ExLlama
ExLlama: Speicher-Effiziente Llama Implementierung für Quantisierte Gewichte
ExLlama ist eine eigenständige Python/C++/CUDA Implementierung von Llama, die für Geschwindigkeit und Speichereffizienz bei der Verwendung von 4-Bit GPTQ Gewichten auf modernen GPUs entwickelt wurde. Dieses Projekt zielt darauf ab, eine schnellere und speichereffizientere Alternative zur Hugging Face Transformers Implementierung zu bieten, insbesondere für Benutzer, die mit quantisierten Modellen arbeiten.
Was ist ExLlama?
ExLlama ist als eine hochleistungsfähige Inferenz-Engine für die Llama-Familie von Sprachmodellen konzipiert. Es nutzt CUDA für GPU-Beschleunigung und ist für 4-Bit GPTQ quantisierte Gewichte optimiert, wodurch Benutzer große Sprachmodelle auf GPUs mit begrenztem Speicher ausführen können.
Wie funktioniert ExLlama?
ExLlama optimiert die Speichernutzung und Inferenzgeschwindigkeit durch verschiedene Techniken:
- CUDA Implementierung: Nutzt CUDA für effiziente GPU-Berechnungen.
- Quantisierungsunterstützung: Speziell für 4-Bit GPTQ quantisierte Gewichte entwickelt.
- Speichereffizienz: Reduziert den Speicherbedarf im Vergleich zu Standardimplementierungen.
Hauptmerkmale und Vorteile:
- Hohe Leistung: Optimiert für schnelle Inferenz.
- Speichereffizienz: Ermöglicht das Ausführen großer Modelle auf weniger leistungsstarken GPUs.
- Eigenständige Implementierung: Keine Notwendigkeit für die Hugging Face Transformers Bibliothek.
- Web UI: Beinhaltet eine einfache Web UI für einfache Interaktion mit dem Modell (JavaScript geschrieben von ChatGPT, also Vorsicht!).
- Docker Unterstützung: Kann in einem Docker Container für einfachere Bereitstellung und Sicherheit ausgeführt werden.
Wie benutzt man ExLlama?
Installation:
- Klonen Sie das Repository:
git clone https://github.com/turboderp/exllama - Navigieren Sie zum Verzeichnis:
cd exllama - Installieren Sie Abhängigkeiten:
pip install -r requirements.txt
- Klonen Sie das Repository:
Ausführen des Benchmarks:
python test_benchmark_inference.py -d <path_to_model_files> -p -ppl
Ausführen des Chatbot Beispiels:
python example_chatbot.py -d <path_to_model_files> -un "Jeff" -p prompt_chatbort.txt
Web UI:
- Installieren Sie zusätzliche Abhängigkeiten:
pip install -r requirements-web.txt - Führen Sie die Web UI aus:
python webui/app.py -d <path_to_model_files>
- Installieren Sie zusätzliche Abhängigkeiten:
Warum ExLlama wählen?
ExLlama bietet mehrere Vorteile:
- Leistung: Liefert schnellere Inferenzgeschwindigkeiten im Vergleich zu anderen Implementierungen.
- Zugänglichkeit: Ermöglicht Benutzern mit begrenztem GPU-Speicher, große Sprachmodelle auszuführen.
- Flexibilität: Kann über das Python-Modul in andere Projekte integriert werden.
- Benutzerfreundlichkeit: Bietet eine einfache Web UI für die Interaktion mit dem Modell.
Für wen ist ExLlama geeignet?
ExLlama ist geeignet für:
- Forscher und Entwickler, die mit großen Sprachmodellen arbeiten.
- Benutzer mit NVIDIA GPUs (30er-Serie und neuer empfohlen).
- Diejenigen, die eine speichereffiziente und hochleistungsfähige Inferenzlösung suchen.
- Jeder, der daran interessiert ist, Llama Modelle mit 4-Bit GPTQ Quantisierung auszuführen.
Hardware Anforderungen:
- NVIDIA GPUs (RTX 30er-Serie oder neuer empfohlen)
- ROCm Unterstützung ist theoretisch, aber ungetestet
Abhängigkeiten:
- Python 3.9+
- PyTorch (getestet auf 2.0.1 und 2.1.0 nightly) mit CUDA 11.8
- safetensors 0.3.2
- sentencepiece
- ninja
- flask und waitress (für Web UI)
Docker Unterstützung:
ExLlama kann in einem Docker Container für einfachere Bereitstellung und Sicherheit ausgeführt werden. Das Docker Image unterstützt NVIDIA GPUs.
Ergebnisse und Benchmarks:
ExLlama demonstriert signifikante Leistungsverbesserungen im Vergleich zu anderen Implementierungen, insbesondere in Bezug auf Tokens pro Sekunde (t/s) während der Inferenz. Benchmarks werden für verschiedene Llama Modellgrößen (7B, 13B, 33B, 65B, 70B) auf verschiedenen GPU-Konfigurationen bereitgestellt.
Beispielhafte Verwendung
import torch
from exllama.model import ExLlama, ExLlamaCache, ExLlamaConfig
from exllama.tokenizer import ExLlamaTokenizer
## Initialisiere Modell und Tokenizer
model_directory = "/path/to/your/model"
tokenizer_path = os.path.join(model_directory, "tokenizer.model")
model_config_path = os.path.join(model_directory, "config.json")
config = ExLlamaConfig(model_config_path)
config.model_path = os.path.join(model_directory, "model.safetensors")
tokenizer = ExLlamaTokenizer(tokenizer_path)
model = ExLlama(config)
cache = ExLlamaCache(model)
## Bereite Eingabe vor
prompt = "The quick brown fox jumps over the lazy"
input_ids = tokenizer.encode(prompt)
## Generiere Ausgabe
model.forward(input_ids, cache)
token = model.sample(temperature = 0.7, top_k = 50, top_p = 0.7)
output = tokenizer.decode([token])
print(prompt + output)
Kompatibilität und Modellunterstützung:
ExLlama ist mit einer Reihe von Llama Modellen kompatibel, einschließlich Llama 1 und Llama 2. Das Projekt wird kontinuierlich aktualisiert, um neue Modelle und Funktionen zu unterstützen.
ExLlama ist ein leistungsstarkes Werkzeug für alle, die Llama Modelle effizient ausführen möchten. Sein Fokus auf Speicheroptimierung und Geschwindigkeit macht es zu einer ausgezeichneten Wahl für Forschung und praktische Anwendungen.
Beste Alternativwerkzeuge zu "ExLlama"

vLLM ist eine Inferenz- und Serving-Engine mit hohem Durchsatz und Speichereffizienz für LLMs, die PagedAttention und kontinuierliche Batchverarbeitung für optimierte Leistung bietet.
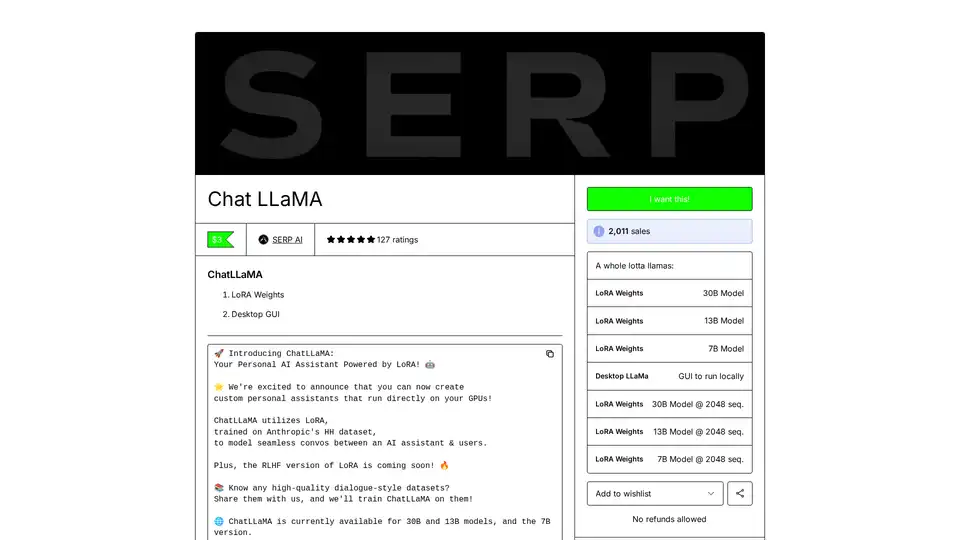
ChatLLaMA ist ein LoRA-trainierter KI-Assistent basierend auf LLaMA-Modellen, der benutzerdefinierte persönliche Gespräche auf Ihrem lokalen GPU ermöglicht. Mit Desktop-GUI, trainiert auf Anthropics HH-Datensatz, verfügbar für 7B-, 13B- und 30B-Modelle.

Ermöglichen Sie eine effiziente LLM-Inferenz mit llama.cpp, einer C/C++-Bibliothek, die für verschiedene Hardware optimiert ist und Quantisierung, CUDA und GGUF-Modelle unterstützt. Ideal für lokale und Cloud-Bereitstellung.
Führen Sie sofort jedes Llama-Modell von HuggingFace aus, ohne Server einzurichten. Über 11.900 Modelle verfügbar. Ab 10 US-Dollar pro Monat für unbegrenzten Zugriff.