LangWatch
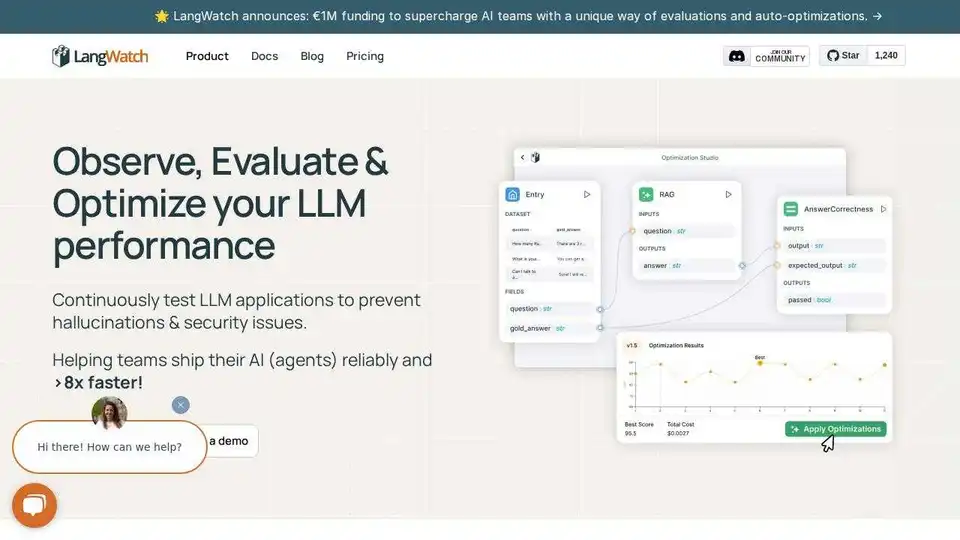
Übersicht von LangWatch
LangWatch: KI-Agenten-Tests und LLM-Evaluierungsplattform
LangWatch ist eine Open-Source-Plattform, die für KI-Agenten-Tests, LLM-Evaluierung und LLM-Observability entwickelt wurde. Sie hilft Teams, KI-Agenten zu simulieren, Antworten zu verfolgen und Fehler zu erkennen, bevor sie sich auf die Produktion auswirken.
Hauptmerkmale:
- Agentensimulation: Testen Sie KI-Agenten mit simulierten Benutzern, um Edge Cases abzufangen und Regressionen zu verhindern.
- LLM-Evaluierung: Bewerten Sie die Leistung von LLMs mit integrierten Tools zur Datenauswahl und -prüfung.
- LLM-Observability: Verfolgen Sie Antworten und beheben Sie Probleme in Ihrer Produktions-KI.
- Framework-Flexibilität: Funktioniert mit jeder LLM-App, jedem Agenten-Framework oder Modell.
- OpenTelemetry Native: Integriert sich in alle LLMs & KI-Agenten-Frameworks.
- Selbst gehostet: Vollständig Open-Source; lokal ausführen oder selbst hosten.
So verwenden Sie LangWatch:
- Erstellen: Entwerfen Sie intelligentere Agenten mit Beweisen, nicht mit Vermutungen.
- Evaluieren: Verwenden Sie integrierte Tools zur Datenauswahl, -bewertung und -prüfung.
- Bereitstellen: Reduzieren Sie Nacharbeiten, verwalten Sie Regressionen und bauen Sie Vertrauen in Ihre KI auf.
- Überwachen: Verfolgen Sie Antworten und fangen Sie Fehler ab, bevor sie in Produktion gehen.
- Optimieren: Arbeiten Sie mit Ihrem gesamten Team zusammen, um Experimente durchzuführen, Datensätze auszuwerten und Prompts und Abläufe zu verwalten.
Integrationen:
LangWatch lässt sich in verschiedene Frameworks und Modelle integrieren, darunter:
- Python
- Typescript
- OpenAI-Agenten
- LiteLLM
- DSPy
- LangChain
- Pydantic AI
- AWS Bedrock
- Agno
- Crew AI
Ist LangWatch das Richtige für Sie?
LangWatch eignet sich für KI-Ingenieure, Data Scientists, Produktmanager und Domain Experts, die gemeinsam bessere KI-Agenten entwickeln möchten.
FAQ:
- Wie funktioniert LangWatch?
- Was ist LLM-Observability?
- Was sind LLM-Evaluierungen?
- Ist LangWatch selbst gehostet verfügbar?
- Wie schneidet LangWatch im Vergleich zu Langfuse oder LangSmith ab?
- Welche Modelle und Frameworks werden von LangWatch unterstützt und wie kann ich sie integrieren?
- Kann ich LangWatch kostenlos ausprobieren?
- Wie handhabt LangWatch Sicherheit und Compliance?
- Wie kann ich zum Projekt beitragen?
LangWatch hilft Ihnen, Agenten mit Zuversicht auszuliefern. Legen Sie in nur 5 Minuten los.
Beste Alternativwerkzeuge zu "LangWatch"
Elixir ist eine AI Ops- und QA-Plattform, die für die Überwachung, das Testen und Debuggen von KI-Sprachagenten entwickelt wurde. Es bietet automatisierte Tests, Anrufprüfung und LLM-Tracing, um eine zuverlässige Leistung zu gewährleisten.
PromptLayer ist eine KI-Engineering-Plattform für Prompt-Management, -Bewertung und LLM-Observability. Arbeiten Sie mit Experten zusammen, überwachen Sie KI-Agenten und verbessern Sie die Prompt-Qualität mit leistungsstarken Tools.
Future AGI bietet eine einheitliche LLM Observability- und KI-Agenten-Evaluierungsplattform für KI-Anwendungen, die Genauigkeit und verantwortungsvolle KI von der Entwicklung bis zur Produktion gewährleistet.
Freeplay ist eine KI-Plattform, die Teams bei der Entwicklung, dem Testen und der Verbesserung von KI-Produkten durch Prompt-Management, Evaluierungen, Observability und Datenprüfungsworkflows unterstützt. Sie optimiert die KI-Entwicklung und gewährleistet eine hohe Produktqualität.
Athina ist eine kollaborative AI-Plattform, die Teams dabei hilft, LLM-basierte Funktionen 10-mal schneller zu entwickeln, zu testen und zu überwachen. Mit Tools für Prompt-Management, Evaluierungen und Observability gewährleistet sie Datenschutz und unterstützt benutzerdefinierte Modelle.
Keywords AI ist eine führende LLM-Monitoring-Plattform, die für KI-Startups entwickelt wurde. Überwachen und verbessern Sie Ihre LLM-Anwendungen einfach mit nur 2 Codezeilen. Debuggen Sie, testen Sie Prompts, visualisieren Sie Protokolle und optimieren Sie die Leistung für zufriedene Benutzer.
Infrabase.ai ist das Verzeichnis zur Entdeckung von KI-Infrastruktur-Tools und -Diensten. Finden Sie Vektor-Datenbanken, Prompt-Engineering-Tools, Inferenz-APIs und mehr, um erstklassige KI-Produkte zu entwickeln.

Openlayer ist eine KI-Unternehmensplattform, die eine einheitliche KI-Bewertung, Observability und Governance für KI-Systeme von ML bis LLMs bietet. Testen, überwachen und verwalten Sie KI-Systeme während des gesamten KI-Lebenszyklus.
Latitude ist eine Open-Source-Plattform für Prompt-Engineering, die es Fachexperten ermöglicht, mit Ingenieuren zusammenzuarbeiten, um LLM-Funktionen in Produktionsqualität bereitzustellen. KI-Produkte mit Vertrauen erstellen, bewerten und bereitstellen.
Maxim AI ist eine End-to-End-Bewertungs- und Observability-Plattform, die Teams dabei unterstützt, KI-Agenten zuverlässig und 5-mal schneller bereitzustellen, mit umfassenden Test-, Überwachungs- und Qualitätssicherungswerkzeugen.
Future AGI ist eine einheitliche LLM-Observability- und KI-Agenten-Evaluierungsplattform, die Unternehmen dabei hilft, durch umfassende Test-, Evaluierungs- und Optimierungswerkzeuge 99% Genauigkeit in KI-Anwendungen zu erreichen.
HoneyHive bietet KI-Bewertungs-, Test- und Observability-Tools für Teams, die LLM-Anwendungen entwickeln. Es bietet eine einheitliche LLMOps-Plattform.
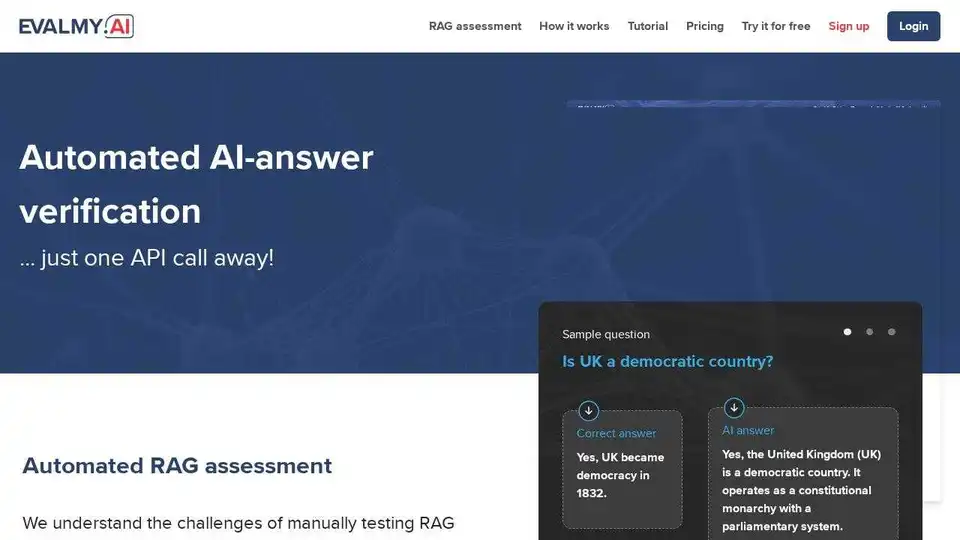
EvalMy.AI automatisiert die KI-Antwortüberprüfung & RAG-Bewertung und optimiert so LLM-Tests. Gewährleisten Sie Genauigkeit, Konfigurierbarkeit & Skalierbarkeit mit einer einfach zu bedienenden API.

Confident AI ist eine auf DeepEval basierende LLM-Evaluierungsplattform, die Ingenieurteams befähigt, die Leistung von LLM-Anwendungen zu testen, zu bewerten, zu sichern und zu verbessern. Sie bietet erstklassige Metriken, Schutzmaßnahmen und Beobachtbarkeit zur Optimierung von KI-Systemen und zum Aufdecken von Regressionen.