WebCrawler API
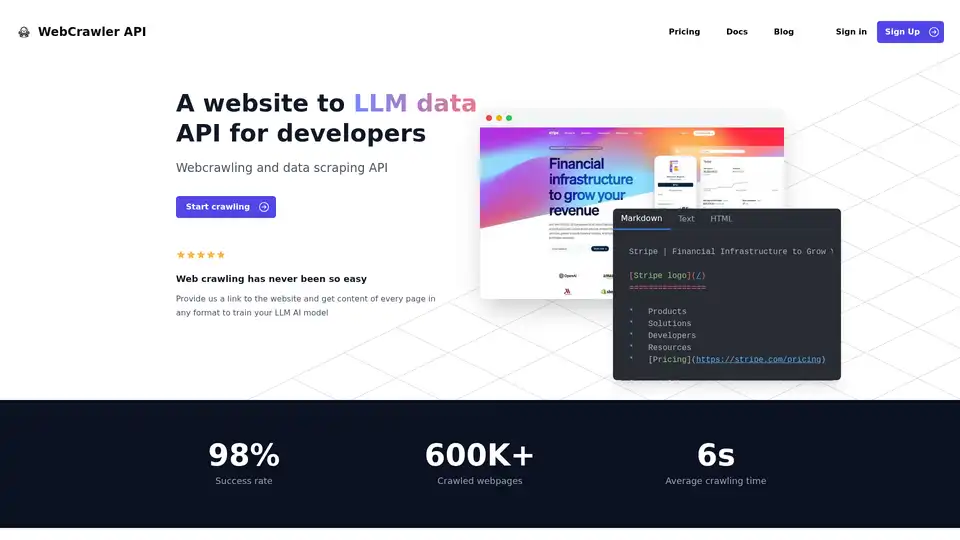
Übersicht von WebCrawler API
WebCrawler API: Müheloses Web-Crawling und Datenextraktion für KI
Was ist die WebCrawler API? Es handelt sich um ein leistungsstarkes Tool, das entwickelt wurde, um den Prozess der Datenextraktion von Websites zu vereinfachen, insbesondere für das Training von Large Language Models (LLMs) und anderen KI-Anwendungen. Es bewältigt die Komplexität des Web-Crawlings, sodass Sie sich auf die Nutzung der Daten konzentrieren können.
Hauptmerkmale:
- Einfache Integration: Integrieren Sie die WebCrawlerAPI mit nur wenigen Codezeilen unter Verwendung von NodeJS, Python, PHP oder .NET.
- Vielseitige Ausgabeformate: Erhalten Sie Inhalte in den Formaten Markdown, Text oder HTML, die auf Ihre Bedürfnisse zugeschnitten sind.
- Hohe Erfolgsquote: Mit einer Erfolgsquote von 98 % überwindet die WebCrawlerAPI häufige Crawling-Probleme wie Anti-Bot-Blocks, CAPTCHAs und IP-Blocks.
- Umfassende Link-Verarbeitung: Verwaltet interne Links, entfernt Duplikate und bereinigt URLs.
- JS-Rendering: Verwendet Puppeteer und Playwright auf stabile Weise, um JavaScript-lastige Websites zu verarbeiten.
- Skalierbare Infrastruktur: Verwaltet und speichert zuverlässig Millionen gecrawlter Seiten.
- Automatische Datenbereinigung: Konvertiert HTML mit komplexen Parsing-Regeln in sauberen Text oder Markdown.
- Proxy-Verwaltung: Beinhaltet unbegrenzte Proxy-Nutzung, sodass Sie sich keine Sorgen um IP-Beschränkungen machen müssen.
Wie funktioniert die WebCrawler API?
Die WebCrawler API abstrahiert die Schwierigkeiten des Web-Crawlings, wie z. B.:
- Link-Verarbeitung: Verwalten interner Links, Entfernen von Duplikaten und Bereinigen von URLs.
- JS-Rendering: Rendern von JavaScript-lastigen Websites, um dynamische Inhalte zu extrahieren.
- Anti-Bot-Blocks: Umgehen von CAPTCHAs, IP-Blocks und Ratenbeschränkungen.
- Speicherung: Verwalten und Speichern großer Mengen gecrawlter Daten.
- Skalierung: Verarbeiten mehrerer Crawler auf verschiedenen Servern.
- Datenbereinigung: Konvertieren von HTML in sauberen Text oder Markdown.
Indem die WebCrawlerAPI diese zugrunde liegenden Komplexitäten behandelt, ermöglicht sie Ihnen, sich auf das zu konzentrieren, was wirklich zählt – die Nutzung der extrahierten Daten für Ihre KI-Projekte.
Wie verwendet man die WebCrawler API?
- Registrieren Sie sich für ein Konto und beziehen Sie Ihren API-Zugangsschlüssel.
- Wählen Sie Ihre bevorzugte Programmiersprache: NodeJS, Python, PHP oder .NET.
- Integrieren Sie den WebCrawlerAPI-Client in Ihren Code.
- Geben Sie die Ziel-URL und das gewünschte Ausgabeformat (Markdown, Text oder HTML) an.
- Starten Sie das Crawling und rufen Sie den extrahierten Inhalt ab.
Beispiel mit NodeJS:
// npm i webcrawlerapi-js
import webcrawlerapi from "webcrawlerapi-js";
async function main() {
const client = new webcrawlerapi.WebcrawlerClient(
"YOUR API ACCESS KEY HERE",
)
const syncJob = await client.crawl({
"items_limit": 10,
"url": "https://stripe.com/",
"scrape_type": "markdown"
}
)
console.log(syncJob);
}
main().catch(console.error);
Warum die WebCrawler API wählen?
- Konzentrieren Sie sich auf Ihr Kerngeschäft: Vermeiden Sie es, Zeit und Ressourcen für die Verwaltung einer komplexen Web-Crawling-Infrastruktur aufzuwenden.
- Greifen Sie auf saubere und strukturierte Daten zu: Erhalten Sie Daten in Ihrem bevorzugten Format, bereit für das KI-Training.
- Skalieren Sie Ihre Datengewinnungsbemühungen: Verarbeiten Sie Millionen von Seiten, ohne sich um Infrastrukturbeschränkungen sorgen zu müssen.
- Kostengünstige Preisgestaltung: Zahlen Sie nur für erfolgreiche Anfragen, ohne Abonnementgebühren.
Für wen ist die WebCrawler API geeignet?
Die WebCrawler API ist ideal für:
- KI- und Machine-Learning-Ingenieure: Die große Datensätze benötigen, um ihre Modelle zu trainieren.
- Data Scientists: Die Daten von Websites für Analysen und Forschung extrahieren müssen.
- Unternehmen: Die Wettbewerber beobachten, Markttrends verfolgen oder Kundeninformationen sammeln müssen.
Preisgestaltung
WebCrawlerAPI bietet eine einfache, nutzungsbasierte Preisgestaltung ohne Abonnementgebühren. Sie zahlen nur für erfolgreiche Anfragen. Ein Kostenrechner steht zur Verfügung, um Ihre monatlichen Ausgaben basierend auf der Anzahl der Seiten, die Sie crawlen möchten, abzuschätzen.
FAQ
- Was ist WebcrawlerAPI? WebcrawlerAPI ist eine API, mit der Sie Inhalte von Websites mit einer hohen Erfolgsquote extrahieren können, wobei Proxys, Wiederholungsversuche und Headless-Browser verarbeitet werden.
- Kann ich nur bestimmte Seiten oder die gesamte Website crawlen? Sie können angeben, ob Sie nur bestimmte Seiten oder die gesamte Website crawlen möchten, wenn Sie eine Anfrage stellen.
- Kann ich gecrawlte Daten in RAG verwenden oder mein eigenes KI-Modell trainieren? Ja, die gecrawlten Daten können in Retrieval-Augmented Generation (RAG)-Systemen verwendet werden oder um Ihr eigenes KI-Modell zu trainieren.
- Muss ich ein Abonnement bezahlen, um WebcrawlerAPI zu verwenden? Nein, es fallen keine Abonnementgebühren an. Sie zahlen nur für erfolgreiche Anfragen.
- Kann ich WebcrawlerAPI vor dem Kauf ausprobieren? Kontaktieren Sie sie, um sich nach Testoptionen zu erkundigen.
- Was ist, wenn ich Hilfe bei der Integration benötige? E-Mail-Support wird bereitgestellt.
Der beste Weg, um Website-Daten für das KI-Training mit WebCrawlerAPI zu extrahieren
WebCrawlerAPI bietet eine optimierte Lösung für die Extraktion von Website-Daten, vereinfacht die Komplexität des Web-Crawlings und ermöglicht es Ihnen, sich auf das KI-Modelltraining und die Datenanalyse zu konzentrieren. Mit seiner hohen Erfolgsquote, den vielseitigen Ausgabeformaten und den effizienten Datenbereinigungsfunktionen ermöglicht es KI-Ingenieuren, Datenwissenschaftlern und Unternehmen, effektiv wertvolle Erkenntnisse aus dem Web zu gewinnen.
Beste Alternativwerkzeuge zu "WebCrawler API"
Firecrawl ist die führende Web-Crawling-, Scraping- und Such-API für KI-Anwendungen. Sie verwandelt Websites in saubere, strukturierte, LLM-bereite Daten im großen Maßstab und versorgt KI-Agenten mit zuverlässiger Web-Extraktion ohne Proxys oder Kopfschmerzen.
Verwandeln Sie jede Website mit Skrape.ai in saubere, strukturierte Daten. Unsere KI-gestützte API extrahiert Daten in Ihrem bevorzugten Format für KI-Training.

Olostep ist eine Webdaten-API für KI und Forschungsagenten. Sie ermöglicht es Ihnen, strukturierte Webdaten von jeder Website in Echtzeit zu extrahieren und Ihre Web-Research-Workflows zu automatisieren. Anwendungsfälle sind Daten für KI, Tabellenkalkulationsanreicherung, Leadgenerierung und mehr.
UseScraper ist eine superschnelle Web Scraping und Crawling API. Scrapen Sie jede URL sofort, crawlen Sie ganze Websites und geben Sie Daten in Klartext, HTML oder Markdown aus. Die ersten 1.000 Seiten sind kostenlos.
Agenty® ist eine No-Code-Web-Scraping-Software, die Datenerfassung, Änderungsüberwachung und Browserautomatisierung automatisiert. Extrahieren Sie mit KI wertvolle Informationen von Websites, verbessern Sie die Forschung und gewinnen Sie Einblicke.
Chat Data ist ein KI-Chatbot-Erstellungstool für Websites, Discord, Slack, Shopify, WordPress und mehr. Einmal trainieren, überall einsetzen. Anpassen, verbinden und teilen.
Apify ist eine Full-Stack-Cloud-Plattform für Web Scraping, Browserautomatisierung und KI-Agenten. Verwenden Sie vorgefertigte Tools oder erstellen Sie Ihre eigenen Actors für Datenextraktion und Workflow-Automatisierung.
Crawl AI: Erstellen Sie benutzerdefinierte KI-Assistenten, -Agenten und Web Scraper einfach. Scrapen Sie Websites, extrahieren Sie Daten und fördern Sie die tiefgreifende Forschung.
PromptLoop: KI-Plattform für GTM & B2B-Vertrieb. Automatisieren Sie Web Scraping, Deep Research und CRM-Datenanreicherung für genaue B2B-Einblicke. 10x schnellere B2B-Recherche. Starten Sie kostenlos.
Capalyze ist ein Datenanalysetool, das Unternehmen durch Multi-Source-Integration und Web-Datencrawling mit Einblicken versorgt und zu klügeren Entscheidungen führt.

Exa ist eine KI-gestützte Suchmaschine und Webdaten-API für Entwickler. Sie bietet schnelle Websuche, Websets für komplexe Abfragen und Tools für Crawling, Beantwortung und tiefgehende Recherchen, wodurch KI auf Echtzeitinformationen zugreifen kann.
Horseman ist ein konfigurierbarer Webcrawler, der JavaScript-Snippets und die GPT-Integration verwendet, um Einblicke in Ihre Website zu gewähren. Es ist perfekt für Entwickler, SEO-Spezialisten und Performance-Analysten.
Aktuelle KI-basierte Web-Apps und die vollständige Sammlung von 15 Utility-Web-Apps, die mit KI in 30 Tagen erstellt wurden, einschließlich AutoRoadmap.
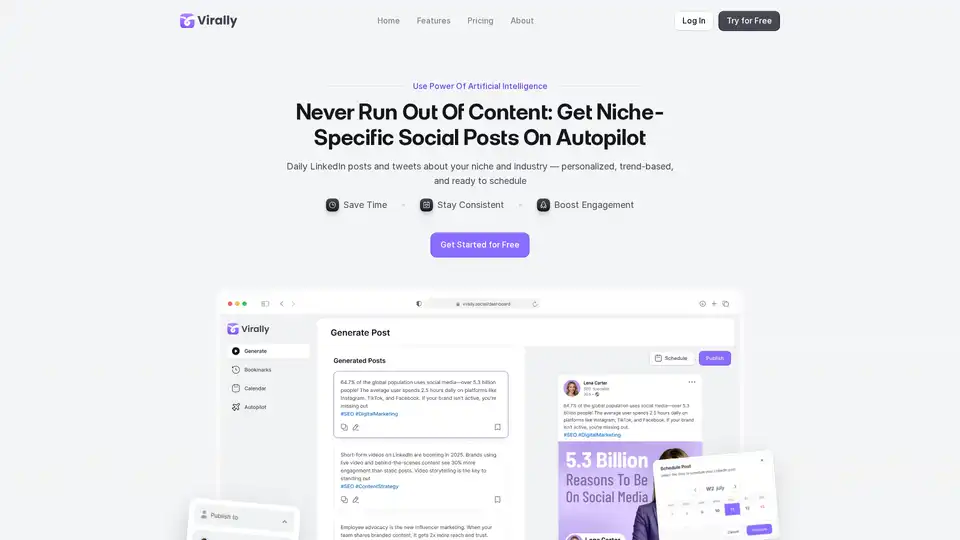
Virally automatisiert personalisierte, trendbasierte LinkedIn- und X-Beiträge mit KI. Durchsucht das Web nach frischem Content, repurposed ihn zu bereit-zu-veröffentlichen Posts im Autopilot- oder Manual-Modus. Ideal für vielbeschäftigte Profis, um Zeit zu sparen und Engagement zu steigern.