BenchLLM
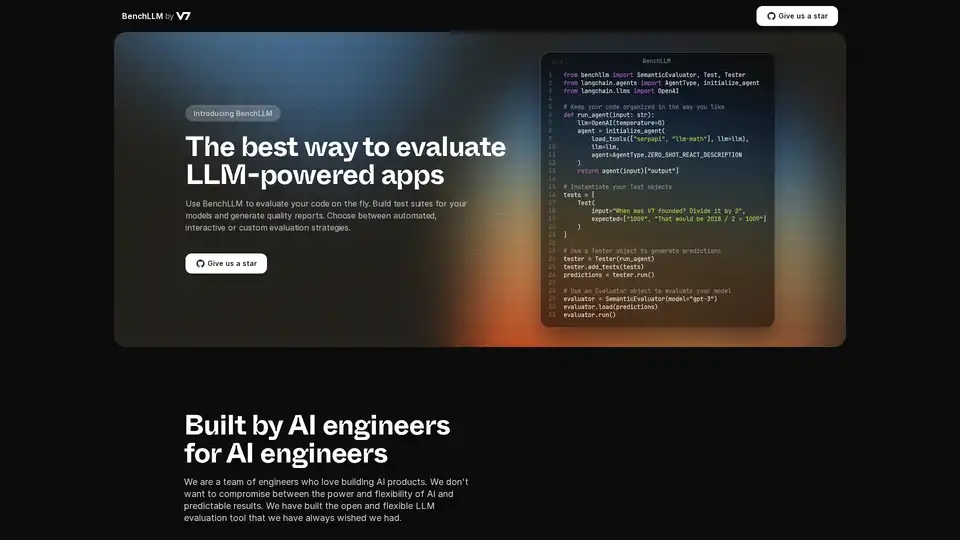
Vue d'ensemble de BenchLLM
Qu'est-ce que BenchLLM ?
BenchLLM est un outil conçu pour évaluer la performance et la qualité des applications alimentées par des modèles de langage de grande taille (LLM). Il fournit un cadre flexible et complet pour construire des suites de tests, générer des rapports de qualité et surveiller la performance des modèles. Que vous ayez besoin de stratégies d'évaluation automatisées, interactives ou personnalisées, BenchLLM offre les fonctionnalités et les capacités nécessaires pour garantir que vos modèles d'IA répondent aux normes requises.
Comment fonctionne BenchLLM ?
BenchLLM fonctionne en permettant aux utilisateurs de définir des tests, d'exécuter des modèles par rapport à ces tests, puis d'évaluer les résultats. Voici une explication détaillée :
- Définir les tests intuitivement: Les tests peuvent être définis au format JSON ou YAML, ce qui facilite la configuration et la gestion des cas de test.
- Organiser les tests en suites: Organisez les tests en suites pour faciliter le contrôle de version et la gestion. Cela aide à maintenir différentes versions des tests à mesure que les modèles évoluent.
- Exécuter les tests: Utilisez la puissante CLI ou l'API flexible pour exécuter des tests sur vos modèles. BenchLLM prend en charge OpenAI, Langchain et toute autre API prête à l'emploi.
- Évaluer les résultats: BenchLLM fournit plusieurs stratégies d'évaluation pour évaluer la performance de vos modèles. Il aide à identifier les régressions en production et à surveiller la performance des modèles au fil du temps.
- Générer des rapports: Générez des rapports d'évaluation et partagez-les avec votre équipe. Ces rapports fournissent des informations sur les forces et les faiblesses de vos modèles.
Exemples d'extraits de code:
Voici un exemple d'utilisation de BenchLLM avec Langchain :
from benchllm import SemanticEvaluator, Test, Tester
from langchain.agents import AgentType, initialize_agent
from langchain.llms import OpenAI
## Keep your code organized in the way you like
def run_agent(input: str):
llm=OpenAI(temperature=0)
agent = initialize_agent(
load_tools(["serpapi", "llm-math"], llm=llm),
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
return agent(input)["output"]
## Instantiate your Test objects
tests = [
Test(
input="When was V7 founded? Divide it by 2",
expected=["1009", "That would be 2018 / 2 = 1009"]
)
]
## Use a Tester object to generate predictions
tester = Tester(run_agent)
tester.add_tests(tests)
predictions = tester.run()
## Use an Evaluator object to evaluate your model
evaluator = SemanticEvaluator(model="gpt-3")
evaluator.load(predictions)
evaluator.run()
Voici un exemple d'utilisation de BenchLLM avec l'API ChatCompletion d'OpenAI :
import benchllm
from benchllm.input_types import ChatInput
import openai
def chat(messages: ChatInput):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0].message.content.strip()
@benchllm.test(suite=".")
def run(input: ChatInput):
return chat(input)
Principales caractéristiques et avantages
- API flexible: Testez le code à la volée avec la prise en charge d'OpenAI, Langchain et d'autres API.
- CLI puissante: Exécutez et évaluez les modèles avec de simples commandes CLI, idéal pour les pipelines CI/CD.
- Évaluation facile: Définissez les tests de manière intuitive au format JSON ou YAML.
- Automatisation: Automatisez les évaluations au sein d'un pipeline CI/CD pour garantir une qualité continue.
- Rapports perspicaces: Générez et partagez des rapports d'évaluation pour surveiller la performance des modèles.
- Surveillance de la performance: Détectez les régressions en production en surveillant la performance des modèles.
Comment utiliser BenchLLM ?
- Installation: Téléchargez et installez BenchLLM.
- Définir les tests: Créez des suites de tests en JSON ou YAML.
- Exécuter les évaluations: Utilisez la CLI ou l'API pour exécuter des tests sur vos applications LLM.
- Analyser les rapports: Examinez les rapports générés pour identifier les points à améliorer.
À qui s'adresse BenchLLM ?
BenchLLM est conçu pour les ingénieurs et les développeurs en IA qui souhaitent garantir la qualité et la fiabilité de leurs applications alimentées par LLM. Il est particulièrement utile pour :
- Ingénieurs en IA: Ceux qui construisent et maintiennent des produits d'IA.
- Développeurs: Intégrer les LLM dans leurs applications.
- Équipes: Qui cherchent à surveiller et à améliorer la performance de leurs modèles d'IA.
Pourquoi choisir BenchLLM ?
BenchLLM fournit une solution complète pour évaluer les applications LLM, offrant flexibilité, automatisation et rapports perspicaces. Il est construit par des ingénieurs en IA qui comprennent la nécessité d'outils puissants et flexibles qui fournissent des résultats prévisibles. En utilisant BenchLLM, vous pouvez :
- Assurer la qualité de vos applications LLM.
- Automatiser le processus d'évaluation.
- Surveiller la performance des modèles et détecter les régressions.
- Améliorer la collaboration grâce à des rapports perspicaces.
En choisissant BenchLLM, vous optez pour une solution robuste et fiable pour évaluer vos modèles d'IA et garantir qu'ils répondent aux normes de performance et de qualité les plus élevées.
Meilleurs outils alternatifs à "BenchLLM"

Openlayer est une plateforme d'IA d'entreprise offrant une évaluation, une observabilité et une gouvernance unifiées de l'IA pour les systèmes d'IA, du ML aux LLM. Testez, surveillez et gouvernez les systèmes d'IA tout au long du cycle de vie de l'IA.

Confident AI est une plateforme d'évaluation LLM basée sur DeepEval, permettant aux équipes d'ingénierie de tester, évaluer, sécuriser et améliorer les performances des applications LLM. Elle fournit des métriques, des garde-fous et une observabilité de pointe pour optimiser les systèmes d'IA et détecter les régressions.
Maxim AI est une plateforme d'évaluation et d'observabilité de bout en bout qui aide les équipes à déployer des agents IA de manière fiable et 5 fois plus rapidement avec des outils complets de test, de surveillance et d'assurance qualité.
Parea AI est la plateforme ultime d'expérimentation et d'annotation humaine pour les équipes d'IA, permettant une évaluation fluide des LLM, des tests de prompts et un déploiement en production pour construire des applications d'IA fiables.
Elixir est une plateforme d'AI Ops et d'assurance qualité conçue pour surveiller, tester et déboguer les agents vocaux d'IA. Il offre des tests automatisés, une revue d'appels et un suivi LLM pour garantir des performances fiables.
PromptPoint vous aide à concevoir, tester et déployer rapidement des prompts grâce à des tests automatisés de prompts. Boostez l'ingénierie des prompts de votre équipe grâce à des sorties LLM de haute qualité.
LangChain est un framework open source qui aide les développeurs à créer, tester et déployer des agents d'IA. Il offre des outils d'observabilité, d'évaluation et de déploiement, prenant en charge divers cas d'utilisation, des copilotes à la recherche d'IA.
Vivgrid est une plateforme d'infrastructure d'agents d'IA qui aide les développeurs à créer, observer, évaluer et déployer des agents d'IA avec des garde-fous de sécurité et une inférence à faible latence. Il prend en charge GPT-5, Gemini 2.5 Pro et DeepSeek-V3.
UpTrain est une plateforme LLMOps complète qui fournit des outils de qualité entreprise pour évaluer, expérimenter, surveiller et tester les applications LLM. Hébergez dans votre propre environnement cloud sécurisé et mettez l'IA à l'échelle en toute confiance.
Weco AI automatise les expériences d'apprentissage automatique en utilisant la technologie AIDE ML, optimisant les pipelines ML grâce à l'évaluation de code pilotée par IA et l'expérimentation systématique pour améliorer les métriques de précision et de performance.
Athina est une plateforme collaborative d'IA qui aide les équipes à construire, tester et surveiller les fonctionnalités basées sur LLM 10 fois plus rapidement. Avec des outils pour la gestion de prompts, les évaluations et l'observabilité, elle assure la confidentialité des données et prend en charge les modèles personnalisés.
EvalMy.AI automatise la vérification des réponses de l'IA et l'évaluation RAG, rationalisant les tests LLM. Garantissez l'exactitude, la configurabilité et l'évolutivité grâce à une API facile à utiliser.
Freeplay est une plateforme d'IA conçue pour aider les équipes à créer, tester et améliorer les produits d'IA grâce à la gestion des invites, aux évaluations, à l'observabilité et aux flux de travail d'examen des données. Il rationalise le développement de l'IA et garantit une qualité de produit élevée.
Les agents d'IA Patsnap Eureka automatisent les flux de travail à forte intensité de main-d'œuvre pour la propriété intellectuelle, la R&D, les sciences de la vie et les matériaux, permettant aux experts de se concentrer sur les décisions à fort impact et l'innovation. Il fournit des résultats précis, fournissant des informations fiables.