Selene
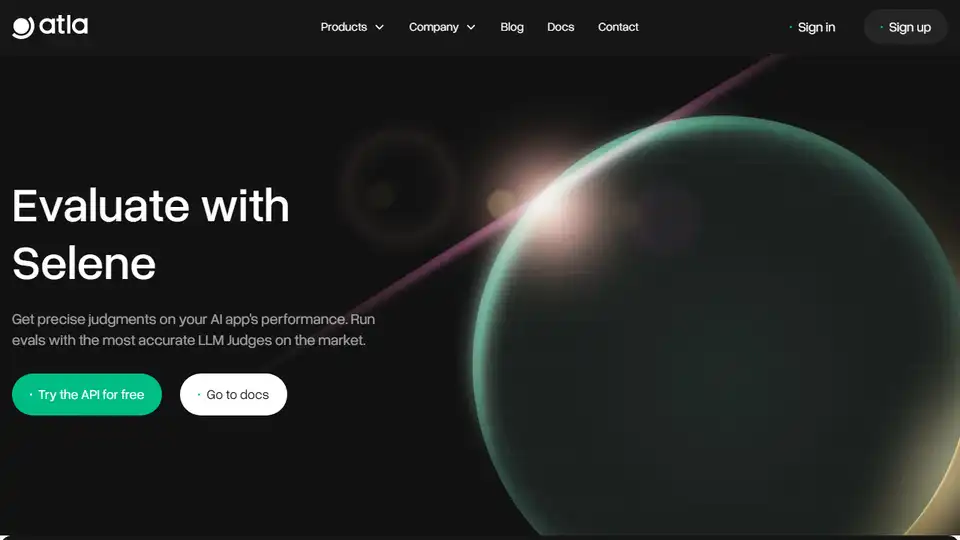
Visão geral de Selene
Selene da Atla AI: Modelos de Avaliação de IA de Fronteira
O que é Selene?
Selene é um conjunto de modelos LLM Judge de código aberto desenvolvidos pela Atla AI, projetados para fornecer avaliações precisas e confiáveis do desempenho de aplicações de AI. Ele ajuda os desenvolvedores a construir confiança com os clientes, garantindo a confiabilidade de seus aplicativos de AI generativa por meio de pontuações detalhadas e críticas acionáveis.
Como o Selene funciona?
Os modelos Selene funcionam como LLM-as-a-Judge, analisando as respostas de AI para fornecer pontuações e críticas. Você pode usar os modelos Selene através do Hugging Face Transformers, Ollama ou Github.
Modelos Selene
Explore o tamanho certo para suas necessidades de avaliação com dois modelos principais:
- Selene 1: O modelo principal, que oferece precisão líder do setor em uma ampla variedade de tarefas de avaliação. Ideal para avaliações de pré-produção.
- Selene 1 Mini: Uma versão enxuta e otimizada, perfeita para executar avaliações no tempo de inferência, priorizando velocidade e eficiência.
Principais Características e Benefícios
- Alta Precisão: Selene foi projetado para fornecer as avaliações mais precisas disponíveis.
- Avaliação Versátil: Adequado para uma ampla variedade de tarefas de avaliação.
- Otimizado para Velocidade: Selene 1 Mini é otimizado para executar avaliações rapidamente durante a inferência.
- Código Aberto: Use e contribua com os modelos através do Hugging Face Transformers.
Como Usar o Selene
Para usar o Selene, você pode aproveitar a biblioteca Hugging Face Transformers. Aqui está um exemplo simples:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # o dispositivo para carregar o modelo
model_id = "AtlaAI/Selene-1-Mini-Llama-3.1-8B"
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)
prompt = "Ouvi dizer que você pode avaliar minhas respostas?" # substitua pelo seu prompt de avaliação
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Casos de Uso
- Avaliando o Desempenho do Agente: Use Selene para avaliar o desempenho de agentes de AI, rastrear erros e obter insights instantâneos.
- Construindo Confiança: Garanta a confiabilidade do seu aplicativo de AI generativa para construir confiança com os clientes.
- Avaliações de Pré-Produção: Use Selene 1 para avaliações rigorosas antes de implantar sua aplicação de AI.
- Avaliações em Tempo de Inferência: Use Selene 1 Mini para avaliações rápidas durante a inferência.
Por que Selene é importante?
À medida que as aplicações de AI se tornam mais prevalentes, garantir sua confiabilidade e credibilidade é crucial. Selene fornece um meio robusto e preciso de avaliar o desempenho da AI, capacitando os desenvolvedores a criar sistemas de AI mais seguros e confiáveis. É particularmente importante para construir confiança com os clientes, especialmente em aplicações de AI generativa onde as saídas podem ser imprevisíveis.
Onde posso usar Selene?
Você pode integrar Selene em seu fluxo de trabalho de desenvolvimento de AI usando Hugging Face Transformers. Além disso, você pode explorar Agent Evals by Atla para aprimorar e rastrear Agentes.
Ao fornecer modelos de avaliação de código aberto, a Atla AI contribui para um futuro com AI segura e confiável.
Melhores ferramentas alternativas para "Selene"
Query Vary é uma plataforma sem código que permite que as equipes treinem IA de forma colaborativa e construam automações baseadas em IA. Ele integra IA generativa para otimizar fluxos de trabalho e melhorar a produtividade sem programação.

Parea AI é uma plataforma de experimentação e anotação de IA que ajuda as equipes a enviar aplicativos LLM com confiança. Oferece recursos para rastreamento de experimentos, observabilidade, revisão humana e implantação rápida.
BenchLLM é uma ferramenta de código aberto para avaliar aplicativos com tecnologia LLM. Crie conjuntos de testes, gere relatórios e monitore o desempenho do modelo com estratégias automatizadas, interativas ou personalizadas.
Teammately é o Agente de IA para Engenheiros de IA, automatizando e acelerando cada etapa na construção de IA confiável em escala. Construa IA de nível de produção mais rápido com geração de prompts, RAG e observabilidade.
Maxim AI é uma plataforma completa de avaliação e observabilidade que ajuda as equipes a implantar agentes de IA de forma confiável e 5 vezes mais rápido com ferramentas abrangentes de teste, monitoramento e garantia de qualidade.
Parea AI é a plataforma definitiva de experimentação e anotação humana para equipes de IA, permitindo avaliação fluida de LLM, testes de prompts e implantação em produção para construir aplicativos de IA confiáveis.
Coxwave Align permite que organizações modernas analisem e avaliem facilmente dados de produtos conversacionais baseados em LLM.
Arize AI fornece uma plataforma unificada de observabilidade LLM e avaliação de agentes para aplicações de IA, desde o desenvolvimento até a produção. Otimize prompts, rastreie agentes e monitore o desempenho da IA em tempo real.

Bolt Foundry fornece ferramentas de engenharia de contexto para tornar o comportamento da IA previsível e testável, ajudando você a construir produtos LLM confiáveis. Teste os LLM como se testasse o código.
Latitude é uma plataforma de código aberto para engenharia de prompts, permitindo que especialistas de domínio colaborem com engenheiros para entregar recursos LLM de nível de produção. Construa, avalie e implemente produtos de IA com confiança.

Openlayer é uma plataforma de IA empresarial que fornece avaliação, observabilidade e governança de IA unificadas para sistemas de IA, desde ML até LLM. Teste, monitore e governe os sistemas de IA durante todo o ciclo de vida da IA.

Confident AI: Plataforma de avaliação LLM DeepEval para testar, avaliar e melhorar o desempenho de aplicativos LLM.
LangWatch é uma plataforma de teste de agentes de IA, avaliação de LLM e observabilidade de LLM. Teste agentes, evite regressões e depure problemas.
Future AGI oferece uma plataforma unificada de observabilidade de LLM e avaliação de agentes de IA para aplicações de IA, garantindo precisão e IA responsável desde o desenvolvimento até a produção.