BenchLLM
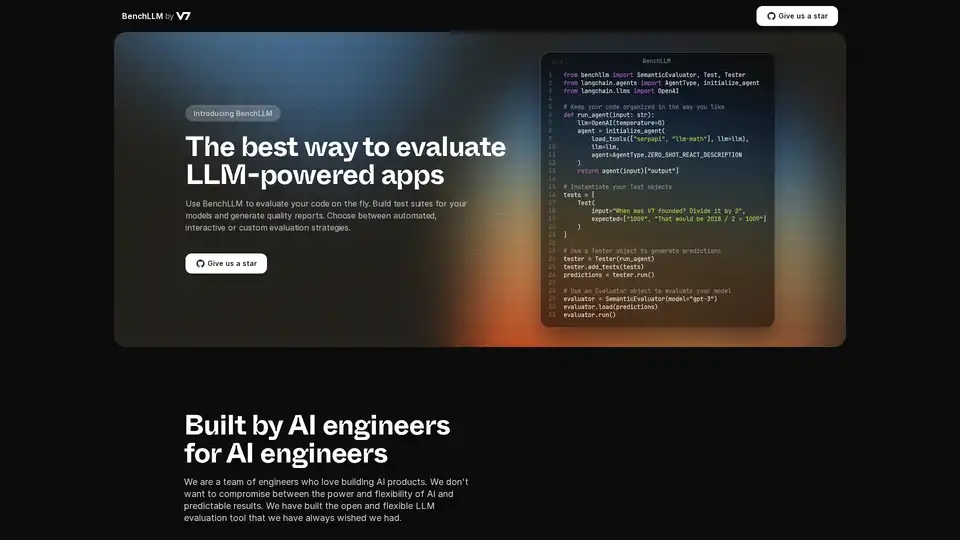
Visão geral de BenchLLM
O que é o BenchLLM?
BenchLLM é uma ferramenta projetada para avaliar o desempenho e a qualidade de aplicações alimentadas por Modelos de Linguagem Grandes (LLMs). Ele fornece uma estrutura flexível e abrangente para construir conjuntos de testes, gerar relatórios de qualidade e monitorar o desempenho do modelo. Seja qual for a sua necessidade, estratégias de avaliação automatizadas, interativas ou personalizadas, o BenchLLM oferece os recursos e capacidades para garantir que seus modelos de AI atendam aos padrões exigidos.
Como o BenchLLM funciona?
O BenchLLM funciona permitindo que os usuários definam testes, executem modelos nesses testes e, em seguida, avaliem os resultados. Aqui está uma análise detalhada:
- Defina Testes Intuitivamente: Os testes podem ser definidos em formato JSON ou YAML, facilitando a configuração e o gerenciamento de casos de teste.
- Organize Testes em Suítes: Organize os testes em suítes para facilitar o versionamento e o gerenciamento. Isso ajuda a manter diferentes versões de testes à medida que os modelos evoluem.
- Execute Testes: Use a poderosa CLI ou a API flexível para executar testes em seus modelos. O BenchLLM oferece suporte a OpenAI, Langchain e qualquer outra API pronta para uso.
- Avalie Resultados: O BenchLLM fornece várias estratégias de avaliação para avaliar o desempenho de seus modelos. Ele ajuda a identificar regressões na produção e a monitorar o desempenho do modelo ao longo do tempo.
- Gere Relatórios: Gere relatórios de avaliação e compartilhe-os com sua equipe. Esses relatórios fornecem insights sobre os pontos fortes e fracos de seus modelos.
Exemplo de Trechos de Código:
Aqui está um exemplo de como usar o BenchLLM com Langchain:
from benchllm import SemanticEvaluator, Test, Tester
from langchain.agents import AgentType, initialize_agent
from langchain.llms import OpenAI
## Keep your code organized in the way you like
def run_agent(input: str):
llm=OpenAI(temperature=0)
agent = initialize_agent(
load_tools(["serpapi", "llm-math"], llm=llm),
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
return agent(input)["output"]
## Instantiate your Test objects
tests = [
Test(
input="When was V7 founded? Divide it by 2",
expected=["1009", "That would be 2018 / 2 = 1009"]
)
]
## Use a Tester object to generate predictions
tester = Tester(run_agent)
tester.add_tests(tests)
predictions = tester.run()
## Use an Evaluator object to evaluate your model
evaluator = SemanticEvaluator(model="gpt-3")
evaluator.load(predictions)
evaluator.run()
Aqui está um exemplo de como usar o BenchLLM com a API ChatCompletion da OpenAI:
import benchllm
from benchllm.input_types import ChatInput
import openai
def chat(messages: ChatInput):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0].message.content.strip()
@benchllm.test(suite=".")
def run(input: ChatInput):
return chat(input)
Principais Características e Benefícios
- API Flexível: Teste o código em tempo real com suporte para OpenAI, Langchain e outras APIs.
- CLI Poderosa: Execute e avalie modelos com comandos CLI simples, ideal para pipelines de CI/CD.
- Avaliação Fácil: Defina testes intuitivamente em formato JSON ou YAML.
- Automação: Automatize avaliações dentro de um pipeline de CI/CD para garantir qualidade contínua.
- Relatórios Perspicazes: Gere e compartilhe relatórios de avaliação para monitorar o desempenho do modelo.
- Monitoramento de Desempenho: Detecte regressões na produção monitorando o desempenho do modelo.
Como usar o BenchLLM?
- Instalação: Baixe e instale o BenchLLM.
- Defina Testes: Crie conjuntos de testes em JSON ou YAML.
- Execute Avaliações: Use a CLI ou a API para executar testes em suas aplicações LLM.
- Analise Relatórios: Revise os relatórios gerados para identificar áreas para melhorias.
Para quem é o BenchLLM?
O BenchLLM foi projetado para engenheiros e desenvolvedores de AI que desejam garantir a qualidade e a confiabilidade de suas aplicações alimentadas por LLM. É particularmente útil para:
- Engenheiros de AI: Aqueles que constroem e mantêm produtos de AI.
- Desenvolvedores: Integrando LLMs em suas aplicações.
- Equipes: Que procuram monitorar e melhorar o desempenho de seus modelos de AI.
Por que escolher o BenchLLM?
O BenchLLM fornece uma solução abrangente para avaliar aplicações LLM, oferecendo flexibilidade, automação e relatórios perspicazes. Ele é construído por engenheiros de AI que entendem a necessidade de ferramentas poderosas e flexíveis que forneçam resultados previsíveis. Ao usar o BenchLLM, você pode:
- Garantir a qualidade de suas aplicações LLM.
- Automatizar o processo de avaliação.
- Monitorar o desempenho do modelo e detectar regressões.
- Melhorar a colaboração com relatórios perspicazes.
Ao escolher o BenchLLM, você está optando por uma solução robusta e confiável para avaliar seus modelos de AI e garantir que eles atendam aos mais altos padrões de desempenho e qualidade.
Melhores ferramentas alternativas para "BenchLLM"

Openlayer é uma plataforma de IA empresarial que fornece avaliação, observabilidade e governança de IA unificadas para sistemas de IA, desde ML até LLM. Teste, monitore e governe os sistemas de IA durante todo o ciclo de vida da IA.
Parea AI é a plataforma definitiva de experimentação e anotação humana para equipes de IA, permitindo avaliação fluida de LLM, testes de prompts e implantação em produção para construir aplicativos de IA confiáveis.

Confident AI é uma plataforma de avaliação LLM construída sobre DeepEval, capacitando equipes de engenharia a testar, comparar, proteger e aprimorar o desempenho de aplicativos LLM. Oferece métricas e guardrails de ponta, além de observabilidade para otimizar sistemas de IA e detectar regressões.
PromptPoint ajuda você a criar, testar e implementar prompts rapidamente com testes automatizados de prompts. Turbine a engenharia de prompts da sua equipe com saídas LLM de alta qualidade.
Maxim AI é uma plataforma completa de avaliação e observabilidade que ajuda as equipes a implantar agentes de IA de forma confiável e 5 vezes mais rápido com ferramentas abrangentes de teste, monitoramento e garantia de qualidade.
UpTrain é uma plataforma LLMOps completa que fornece ferramentas de nível empresarial para avaliar, experimentar, monitorar e testar aplicações LLM. Hospede em seu próprio ambiente de nuvem segura e dimensione a IA com confiança.
Athina é uma plataforma colaborativa de IA que ajuda as equipes a construir, testar e monitorar recursos baseados em LLM 10 vezes mais rápido. Com ferramentas para gerenciamento de prompts, avaliações e observabilidade, garante a privacidade de dados e suporta modelos personalizados.
LangChain é uma estrutura de código aberto que ajuda os desenvolvedores a construir, testar e implantar agentes de IA. Ele oferece ferramentas para observabilidade, avaliação e implantação, suportando vários casos de uso, desde copilotos até pesquisa de IA.
Weco AI automatiza experimentos de aprendizado de máquina usando tecnologia AIDE ML, otimizando pipelines ML por meio de avaliação de código orientada por IA e experimentação sistemática para melhorar métricas de precisão e desempenho.
EvalMy.AI automatiza a verificação de respostas de IA e a avaliação RAG, simplificando os testes de LLM. Garanta precisão, configurabilidade e escalabilidade com uma API fácil de usar.
FinetuneDB é uma plataforma de fine-tuning de IA que permite criar e gerenciar conjuntos de dados para treinar LLMs personalizados de forma rápida e econômica, melhorando o desempenho do modelo com dados de produção e ferramentas colaborativas.
Gentrace ajuda a rastrear, avaliar e analisar erros de agentes de IA. Converse com a IA para depurar rastreamentos, automatizar avaliações e ajustar produtos LLM para um desempenho confiável. Comece grátis hoje!
Snoika é uma plataforma SaaS alimentada por IA para otimizar a visibilidade de marcas em motores de busca IA como ChatGPT, Gemini e Perplexity. Oferece análise SEO, criação de conteúdo, construção de sites e análises para impulsionar tráfego orgânico e crescimento 3x mais rápido a 90% menos custo.
Teammately é o Agente de IA para Engenheiros de IA, automatizando e acelerando cada etapa na construção de IA confiável em escala. Construa IA de nível de produção mais rápido com geração de prompts, RAG e observabilidade.